forked from wylab/llama.cpp
Compare commits
41 Commits
| Author | SHA1 | Date | |
|---|---|---|---|
|
|
96e33a814e | ||
|
|
dfc959b886 | ||
|
|
8f48807380 | ||
|
|
bf6bc3c155 | ||
|
|
179fd82a72 | ||
|
|
d34d5ca1e9 | ||
|
|
eb492bf43f | ||
|
|
e3b35ddf1c | ||
|
|
6ce863c803 | ||
|
|
3997c78e33 | ||
|
|
ee74642982 | ||
|
|
a28310488c | ||
|
|
86af848153 | ||
|
|
147a521636 | ||
|
|
e1f15b454f | ||
|
|
0e1ccf15c7 | ||
|
|
5e25ddebff | ||
|
|
fd05c51cec | ||
|
|
b365c3ff01 | ||
|
|
cb64222b0c | ||
|
|
6eb7081860 | ||
|
|
4117ae5557 | ||
|
|
65e96a2464 | ||
|
|
9496bbb808 | ||
|
|
ddcb75dd8a | ||
|
|
52ab19df63 | ||
|
|
5182dd64cd | ||
|
|
10b4f82d44 | ||
|
|
408616adbd | ||
|
|
9e39a1e6a9 | ||
|
|
74e05131e9 | ||
|
|
f74747d886 | ||
|
|
ce734a8a2f | ||
|
|
14931a826e | ||
|
|
f99ef53d2a | ||
|
|
cc0a04343e | ||
|
|
98c1c7a7bf | ||
|
|
acb73d8340 | ||
|
|
0a271d82b4 | ||
|
|
52fc7fee8a | ||
|
|
cdbada8d10 |
@@ -70,6 +70,7 @@ jobs:
|
||||
with:
|
||||
key: macOS-latest-cmake-arm64
|
||||
evict-old-files: 1d
|
||||
save: ${{ github.event_name == 'push' && github.ref == 'refs/heads/master' }}
|
||||
|
||||
- name: Build
|
||||
id: cmake_build
|
||||
@@ -106,6 +107,7 @@ jobs:
|
||||
with:
|
||||
key: macOS-latest-cmake-x64
|
||||
evict-old-files: 1d
|
||||
save: ${{ github.event_name == 'push' && github.ref == 'refs/heads/master' }}
|
||||
|
||||
- name: Build
|
||||
id: cmake_build
|
||||
@@ -142,6 +144,7 @@ jobs:
|
||||
with:
|
||||
key: macOS-latest-cmake-arm64-webgpu
|
||||
evict-old-files: 1d
|
||||
save: ${{ github.event_name == 'push' && github.ref == 'refs/heads/master' }}
|
||||
|
||||
- name: Dawn Dependency
|
||||
id: dawn-depends
|
||||
@@ -195,6 +198,7 @@ jobs:
|
||||
with:
|
||||
key: ubuntu-cpu-cmake-${{ matrix.build }}
|
||||
evict-old-files: 1d
|
||||
save: ${{ github.event_name == 'push' && github.ref == 'refs/heads/master' }}
|
||||
|
||||
- name: Build Dependencies
|
||||
id: build_depends
|
||||
@@ -276,6 +280,7 @@ jobs:
|
||||
with:
|
||||
key: ubuntu-latest-cmake-sanitizer-${{ matrix.sanitizer }}
|
||||
evict-old-files: 1d
|
||||
save: ${{ github.event_name == 'push' && github.ref == 'refs/heads/master' }}
|
||||
|
||||
- name: Dependencies
|
||||
id: depends
|
||||
@@ -396,6 +401,7 @@ jobs:
|
||||
with:
|
||||
key: ubuntu-24-cmake-vulkan-deb
|
||||
evict-old-files: 1d
|
||||
save: ${{ github.event_name == 'push' && github.ref == 'refs/heads/master' }}
|
||||
|
||||
- name: Dependencies
|
||||
id: depends
|
||||
@@ -431,6 +437,7 @@ jobs:
|
||||
with:
|
||||
key: ubuntu-24-cmake-vulkan
|
||||
evict-old-files: 1d
|
||||
save: ${{ github.event_name == 'push' && github.ref == 'refs/heads/master' }}
|
||||
|
||||
- name: Dependencies
|
||||
id: depends
|
||||
@@ -490,6 +497,7 @@ jobs:
|
||||
with:
|
||||
key: ubuntu-24-cmake-webgpu
|
||||
evict-old-files: 1d
|
||||
save: ${{ github.event_name == 'push' && github.ref == 'refs/heads/master' }}
|
||||
|
||||
- name: Dependencies
|
||||
id: depends
|
||||
@@ -562,6 +570,7 @@ jobs:
|
||||
with:
|
||||
key: ubuntu-latest-wasm-webgpu
|
||||
evict-old-files: 1d
|
||||
save: ${{ github.event_name == 'push' && github.ref == 'refs/heads/master' }}
|
||||
|
||||
- name: Install Emscripten
|
||||
run: |
|
||||
@@ -609,6 +618,7 @@ jobs:
|
||||
with:
|
||||
key: ubuntu-22-cmake-hip
|
||||
evict-old-files: 1d
|
||||
save: ${{ github.event_name == 'push' && github.ref == 'refs/heads/master' }}
|
||||
|
||||
- name: Build with native CMake HIP support
|
||||
id: cmake_build
|
||||
@@ -641,6 +651,7 @@ jobs:
|
||||
with:
|
||||
key: ubuntu-22-cmake-musa
|
||||
evict-old-files: 1d
|
||||
save: ${{ github.event_name == 'push' && github.ref == 'refs/heads/master' }}
|
||||
|
||||
- name: Build with native CMake MUSA support
|
||||
id: cmake_build
|
||||
@@ -688,6 +699,7 @@ jobs:
|
||||
with:
|
||||
key: ubuntu-22-cmake-sycl
|
||||
evict-old-files: 1d
|
||||
save: ${{ github.event_name == 'push' && github.ref == 'refs/heads/master' }}
|
||||
|
||||
- name: Build
|
||||
id: cmake_build
|
||||
@@ -738,6 +750,7 @@ jobs:
|
||||
with:
|
||||
key: ubuntu-22-cmake-sycl-fp16
|
||||
evict-old-files: 1d
|
||||
save: ${{ github.event_name == 'push' && github.ref == 'refs/heads/master' }}
|
||||
|
||||
- name: Build
|
||||
id: cmake_build
|
||||
@@ -771,6 +784,7 @@ jobs:
|
||||
with:
|
||||
key: macOS-latest-cmake-ios
|
||||
evict-old-files: 1d
|
||||
save: ${{ github.event_name == 'push' && github.ref == 'refs/heads/master' }}
|
||||
|
||||
- name: Build
|
||||
id: cmake_build
|
||||
@@ -802,6 +816,7 @@ jobs:
|
||||
with:
|
||||
key: macOS-latest-cmake-tvos
|
||||
evict-old-files: 1d
|
||||
save: ${{ github.event_name == 'push' && github.ref == 'refs/heads/master' }}
|
||||
|
||||
- name: Build
|
||||
id: cmake_build
|
||||
@@ -863,6 +878,7 @@ jobs:
|
||||
with:
|
||||
key: macOS-latest-swift
|
||||
evict-old-files: 1d
|
||||
save: ${{ github.event_name == 'push' && github.ref == 'refs/heads/master' }}
|
||||
|
||||
- name: Download xcframework artifact
|
||||
uses: actions/download-artifact@v4
|
||||
@@ -905,6 +921,7 @@ jobs:
|
||||
key: windows-msys2
|
||||
variant: ccache
|
||||
evict-old-files: 1d
|
||||
save: ${{ github.event_name == 'push' && github.ref == 'refs/heads/master' }}
|
||||
|
||||
- name: Setup ${{ matrix.sys }}
|
||||
uses: msys2/setup-msys2@v2
|
||||
@@ -973,6 +990,7 @@ jobs:
|
||||
key: windows-latest-cmake-${{ matrix.build }}
|
||||
variant: ccache
|
||||
evict-old-files: 1d
|
||||
save: ${{ github.event_name == 'push' && github.ref == 'refs/heads/master' }}
|
||||
|
||||
- name: Download OpenBLAS
|
||||
id: get_openblas
|
||||
@@ -1077,6 +1095,7 @@ jobs:
|
||||
with:
|
||||
key: ubuntu-latest-cmake-cuda
|
||||
evict-old-files: 1d
|
||||
save: ${{ github.event_name == 'push' && github.ref == 'refs/heads/master' }}
|
||||
|
||||
- name: Build with CMake
|
||||
run: |
|
||||
@@ -1109,6 +1128,7 @@ jobs:
|
||||
key: windows-cuda-${{ matrix.cuda }}
|
||||
variant: ccache
|
||||
evict-old-files: 1d
|
||||
save: ${{ github.event_name == 'push' && github.ref == 'refs/heads/master' }}
|
||||
|
||||
- name: Install Cuda Toolkit
|
||||
uses: ./.github/actions/windows-setup-cuda
|
||||
@@ -1160,6 +1180,7 @@ jobs:
|
||||
key: windows-latest-cmake-sycl
|
||||
variant: ccache
|
||||
evict-old-files: 1d
|
||||
save: ${{ github.event_name == 'push' && github.ref == 'refs/heads/master' }}
|
||||
|
||||
- name: Install
|
||||
run: |
|
||||
@@ -1221,6 +1242,7 @@ jobs:
|
||||
with:
|
||||
key: ${{ github.job }}
|
||||
evict-old-files: 1d
|
||||
save: ${{ github.event_name == 'push' && github.ref == 'refs/heads/master' }}
|
||||
|
||||
- name: Build
|
||||
id: cmake_build
|
||||
@@ -1466,6 +1488,7 @@ jobs:
|
||||
with:
|
||||
key: ggml-ci-x64-cpu-low-perf
|
||||
evict-old-files: 1d
|
||||
save: ${{ github.event_name == 'push' && github.ref == 'refs/heads/master' }}
|
||||
|
||||
- name: Dependencies
|
||||
id: depends
|
||||
@@ -1491,6 +1514,7 @@ jobs:
|
||||
with:
|
||||
key: ggml-ci-arm64-cpu-low-perf
|
||||
evict-old-files: 1d
|
||||
save: ${{ github.event_name == 'push' && github.ref == 'refs/heads/master' }}
|
||||
|
||||
- name: Dependencies
|
||||
id: depends
|
||||
@@ -1516,6 +1540,7 @@ jobs:
|
||||
with:
|
||||
key: ggml-ci-x64-cpu-high-perf
|
||||
evict-old-files: 1d
|
||||
save: ${{ github.event_name == 'push' && github.ref == 'refs/heads/master' }}
|
||||
|
||||
- name: Dependencies
|
||||
id: depends
|
||||
@@ -1541,6 +1566,7 @@ jobs:
|
||||
with:
|
||||
key: ggml-ci-arm64-cpu-high-perf
|
||||
evict-old-files: 1d
|
||||
save: ${{ github.event_name == 'push' && github.ref == 'refs/heads/master' }}
|
||||
|
||||
- name: Dependencies
|
||||
id: depends
|
||||
@@ -1566,6 +1592,7 @@ jobs:
|
||||
with:
|
||||
key: ggml-ci-arm64-cpu-high-perf-sve
|
||||
evict-old-files: 1d
|
||||
save: ${{ github.event_name == 'push' && github.ref == 'refs/heads/master' }}
|
||||
|
||||
- name: Dependencies
|
||||
id: depends
|
||||
@@ -1701,6 +1728,7 @@ jobs:
|
||||
with:
|
||||
key: ggml-ci-arm64-cpu-kleidiai
|
||||
evict-old-files: 1d
|
||||
save: ${{ github.event_name == 'push' && github.ref == 'refs/heads/master' }}
|
||||
|
||||
- name: Dependencies
|
||||
id: depends
|
||||
@@ -2084,6 +2112,7 @@ jobs:
|
||||
with:
|
||||
key: ggml-ci-arm64-graviton4-kleidiai
|
||||
evict-old-files: 1d
|
||||
save: ${{ github.event_name == 'push' && github.ref == 'refs/heads/master' }}
|
||||
|
||||
- name: Test
|
||||
id: ggml-ci
|
||||
|
||||
@@ -66,16 +66,9 @@ jobs:
|
||||
id: pack_artifacts
|
||||
run: |
|
||||
cp LICENSE ./build/bin/
|
||||
zip -y -r llama-${{ steps.tag.outputs.name }}-bin-macos-arm64.zip ./build/bin/*
|
||||
tar -czvf llama-${{ steps.tag.outputs.name }}-bin-macos-arm64.tar.gz -s ",./,llama-${{ steps.tag.outputs.name }}/," -C ./build/bin .
|
||||
|
||||
- name: Upload artifacts (zip)
|
||||
uses: actions/upload-artifact@v4
|
||||
with:
|
||||
path: llama-${{ steps.tag.outputs.name }}-bin-macos-arm64.zip
|
||||
name: llama-bin-macos-arm64.zip
|
||||
|
||||
- name: Upload artifacts (tar)
|
||||
- name: Upload artifacts
|
||||
uses: actions/upload-artifact@v4
|
||||
with:
|
||||
path: llama-${{ steps.tag.outputs.name }}-bin-macos-arm64.tar.gz
|
||||
@@ -127,16 +120,9 @@ jobs:
|
||||
id: pack_artifacts
|
||||
run: |
|
||||
cp LICENSE ./build/bin/
|
||||
zip -y -r llama-${{ steps.tag.outputs.name }}-bin-macos-x64.zip ./build/bin/*
|
||||
tar -czvf llama-${{ steps.tag.outputs.name }}-bin-macos-x64.tar.gz -s ",./,llama-${{ steps.tag.outputs.name }}/," -C ./build/bin .
|
||||
|
||||
- name: Upload artifacts (zip)
|
||||
uses: actions/upload-artifact@v4
|
||||
with:
|
||||
path: llama-${{ steps.tag.outputs.name }}-bin-macos-x64.zip
|
||||
name: llama-bin-macos-x64.zip
|
||||
|
||||
- name: Upload artifacts (tar)
|
||||
- name: Upload artifacts
|
||||
uses: actions/upload-artifact@v4
|
||||
with:
|
||||
path: llama-${{ steps.tag.outputs.name }}-bin-macos-x64.tar.gz
|
||||
@@ -196,16 +182,9 @@ jobs:
|
||||
id: pack_artifacts
|
||||
run: |
|
||||
cp LICENSE ./build/bin/
|
||||
zip -y -r llama-${{ steps.tag.outputs.name }}-bin-ubuntu-${{ matrix.build }}.zip ./build/bin/*
|
||||
tar -czvf llama-${{ steps.tag.outputs.name }}-bin-ubuntu-${{ matrix.build }}.tar.gz --transform "s,./,llama-${{ steps.tag.outputs.name }}/," -C ./build/bin .
|
||||
|
||||
- name: Upload artifacts (zip)
|
||||
uses: actions/upload-artifact@v4
|
||||
with:
|
||||
path: llama-${{ steps.tag.outputs.name }}-bin-ubuntu-${{ matrix.build }}.zip
|
||||
name: llama-bin-ubuntu-${{ matrix.build }}.zip
|
||||
|
||||
- name: Upload artifacts (tar)
|
||||
- name: Upload artifacts
|
||||
uses: actions/upload-artifact@v4
|
||||
with:
|
||||
path: llama-${{ steps.tag.outputs.name }}-bin-ubuntu-${{ matrix.build }}.tar.gz
|
||||
@@ -256,16 +235,9 @@ jobs:
|
||||
id: pack_artifacts
|
||||
run: |
|
||||
cp LICENSE ./build/bin/
|
||||
zip -y -r llama-${{ steps.tag.outputs.name }}-bin-ubuntu-vulkan-x64.zip ./build/bin/*
|
||||
tar -czvf llama-${{ steps.tag.outputs.name }}-bin-ubuntu-vulkan-x64.tar.gz --transform "s,./,llama-${{ steps.tag.outputs.name }}/," -C ./build/bin .
|
||||
|
||||
- name: Upload artifacts (zip)
|
||||
uses: actions/upload-artifact@v4
|
||||
with:
|
||||
path: llama-${{ steps.tag.outputs.name }}-bin-ubuntu-vulkan-x64.zip
|
||||
name: llama-bin-ubuntu-vulkan-x64.zip
|
||||
|
||||
- name: Upload artifacts (tar)
|
||||
- name: Upload artifacts
|
||||
uses: actions/upload-artifact@v4
|
||||
with:
|
||||
path: llama-${{ steps.tag.outputs.name }}-bin-ubuntu-vulkan-x64.tar.gz
|
||||
@@ -716,21 +688,16 @@ jobs:
|
||||
- name: Pack artifacts
|
||||
id: pack_artifacts
|
||||
run: |
|
||||
zip -y -r llama-${{ steps.tag.outputs.name }}-xcframework.zip build-apple/llama.xcframework
|
||||
tar -czvf llama-${{ steps.tag.outputs.name }}-xcframework.tar.gz -C build-apple llama.xcframework
|
||||
# Zip file is required for Swift Package Manager, which does not support tar.gz for binary targets.
|
||||
# For more details, see https://developer.apple.com/documentation/xcode/distributing-binary-frameworks-as-swift-packages
|
||||
zip -r -y llama-${{ steps.tag.outputs.name }}-xcframework.zip build-apple/llama.xcframework
|
||||
|
||||
- name: Upload artifacts (zip)
|
||||
- name: Upload artifacts
|
||||
uses: actions/upload-artifact@v4
|
||||
with:
|
||||
path: llama-${{ steps.tag.outputs.name }}-xcframework.zip
|
||||
name: llama-${{ steps.tag.outputs.name }}-xcframework.zip
|
||||
|
||||
- name: Upload artifacts (tar)
|
||||
uses: actions/upload-artifact@v4
|
||||
with:
|
||||
path: llama-${{ steps.tag.outputs.name }}-xcframework.tar.gz
|
||||
name: llama-${{ steps.tag.outputs.name }}-xcframework.tar.gz
|
||||
|
||||
|
||||
openEuler-cann:
|
||||
strategy:
|
||||
@@ -797,7 +764,7 @@ jobs:
|
||||
cp LICENSE ./build/bin/
|
||||
tar -czvf llama-${{ steps.tag.outputs.name }}-bin-${{ matrix.chip_type }}-openEuler-${{ matrix.arch }}.tar.gz --transform "s,./,llama-${{ steps.tag.outputs.name }}/," -C ./build/bin .
|
||||
|
||||
- name: Upload artifacts (tar)
|
||||
- name: Upload artifacts
|
||||
uses: actions/upload-artifact@v4
|
||||
with:
|
||||
path: llama-${{ steps.tag.outputs.name }}-bin-${{ matrix.chip_type }}-openEuler-${{ matrix.arch }}.tar.gz
|
||||
@@ -889,9 +856,6 @@ jobs:
|
||||
with:
|
||||
tag_name: ${{ steps.tag.outputs.name }}
|
||||
body: |
|
||||
> [!WARNING]
|
||||
> **Release Format Update**: Linux releases will soon use .tar.gz archives instead of .zip. Please make the necessary changes to your deployment scripts.
|
||||
|
||||
<details open>
|
||||
|
||||
${{ github.event.head_commit.message }}
|
||||
@@ -901,7 +865,7 @@ jobs:
|
||||
**macOS/iOS:**
|
||||
- [macOS Apple Silicon (arm64)](https://github.com/ggml-org/llama.cpp/releases/download/${{ steps.tag.outputs.name }}/llama-${{ steps.tag.outputs.name }}-bin-macos-arm64.tar.gz)
|
||||
- [macOS Intel (x64)](https://github.com/ggml-org/llama.cpp/releases/download/${{ steps.tag.outputs.name }}/llama-${{ steps.tag.outputs.name }}-bin-macos-x64.tar.gz)
|
||||
- [iOS XCFramework](https://github.com/ggml-org/llama.cpp/releases/download/${{ steps.tag.outputs.name }}/llama-${{ steps.tag.outputs.name }}-xcframework.tar.gz)
|
||||
- [iOS XCFramework](https://github.com/ggml-org/llama.cpp/releases/download/${{ steps.tag.outputs.name }}/llama-${{ steps.tag.outputs.name }}-xcframework.zip)
|
||||
|
||||
**Linux:**
|
||||
- [Ubuntu x64 (CPU)](https://github.com/ggml-org/llama.cpp/releases/download/${{ steps.tag.outputs.name }}/llama-${{ steps.tag.outputs.name }}-bin-ubuntu-x64.tar.gz)
|
||||
@@ -911,8 +875,8 @@ jobs:
|
||||
**Windows:**
|
||||
- [Windows x64 (CPU)](https://github.com/ggml-org/llama.cpp/releases/download/${{ steps.tag.outputs.name }}/llama-${{ steps.tag.outputs.name }}-bin-win-cpu-x64.zip)
|
||||
- [Windows arm64 (CPU)](https://github.com/ggml-org/llama.cpp/releases/download/${{ steps.tag.outputs.name }}/llama-${{ steps.tag.outputs.name }}-bin-win-cpu-arm64.zip)
|
||||
- [Windows x64 (CUDA 12)](https://github.com/ggml-org/llama.cpp/releases/download/${{ steps.tag.outputs.name }}/llama-${{ steps.tag.outputs.name }}-bin-win-cuda-12.4-x64.zip)
|
||||
- [Windows x64 (CUDA 13)](https://github.com/ggml-org/llama.cpp/releases/download/${{ steps.tag.outputs.name }}/llama-${{ steps.tag.outputs.name }}-bin-win-cuda-13.1-x64.zip)
|
||||
- [Windows x64 (CUDA 12)](https://github.com/ggml-org/llama.cpp/releases/download/${{ steps.tag.outputs.name }}/llama-${{ steps.tag.outputs.name }}-bin-win-cuda-12.4-x64.zip) - [CUDA 12.4 DLLs](https://github.com/ggml-org/llama.cpp/releases/download/${{ steps.tag.outputs.name }}/cudart-llama-bin-win-cuda-12.4-x64.zip)
|
||||
- [Windows x64 (CUDA 13)](https://github.com/ggml-org/llama.cpp/releases/download/${{ steps.tag.outputs.name }}/llama-${{ steps.tag.outputs.name }}-bin-win-cuda-13.1-x64.zip) - [CUDA 13.1 DLLs](https://github.com/ggml-org/llama.cpp/releases/download/${{ steps.tag.outputs.name }}/cudart-llama-bin-win-cuda-13.1-x64.zip)
|
||||
- [Windows x64 (Vulkan)](https://github.com/ggml-org/llama.cpp/releases/download/${{ steps.tag.outputs.name }}/llama-${{ steps.tag.outputs.name }}-bin-win-vulkan-x64.zip)
|
||||
- [Windows x64 (SYCL)](https://github.com/ggml-org/llama.cpp/releases/download/${{ steps.tag.outputs.name }}/llama-${{ steps.tag.outputs.name }}-bin-win-sycl-x64.zip)
|
||||
- [Windows x64 (HIP)](https://github.com/ggml-org/llama.cpp/releases/download/${{ steps.tag.outputs.name }}/llama-${{ steps.tag.outputs.name }}-bin-win-hip-radeon-x64.zip)
|
||||
|
||||
@@ -1,4 +1,4 @@
|
||||
# Copilot Instructions for llama.cpp
|
||||
# Instructions for llama.cpp
|
||||
|
||||
## Repository Overview
|
||||
|
||||
@@ -12,6 +12,24 @@ llama.cpp is a large-scale C/C++ project for efficient LLM (Large Language Model
|
||||
- **Backends supported**: CPU (AVX/NEON/RVV optimized), CUDA, Metal, Vulkan, SYCL, ROCm, MUSA
|
||||
- **License**: MIT
|
||||
|
||||
## Disclose AI Usage
|
||||
|
||||
It is crucial to remind contributors that the project mandates disclosure of any AI usage in pull requests. This requirement stems from the potential for AI-generated code to include suboptimal optimizations and hidden bugs, owing to the inherent overconfidence in AI outputs.
|
||||
|
||||
When generating significant portions of code, address this by:
|
||||
- Informing the user that AI-generated content may be rejected by maintainers.
|
||||
- Clearly marking AI-generated code in commit messages and comments.
|
||||
- Example of commit message: `[AI] Fix a race condition in ...`
|
||||
- Example of code comment: `// [AI] spawn a new thread ...`
|
||||
|
||||
These measures apply to:
|
||||
- Changes resulting in large portions of code or complex logic.
|
||||
- Modifications or additions to public APIs in `llama.h`, `ggml.h`, or `mtmd.h`.
|
||||
- Backend-related changes, such as those involving CPU, CUDA, Metal, Vulkan, etc.
|
||||
- Modifications to `tools/server`.
|
||||
|
||||
Note: These measures can be omitted for small fixes or trivial changes.
|
||||
|
||||
## Build Instructions
|
||||
|
||||
### Prerequisites
|
||||
@@ -251,6 +269,7 @@ Primary tools:
|
||||
- **Cross-platform compatibility**: Test on Linux, macOS, Windows when possible
|
||||
- **Performance focus**: This is a performance-critical inference library
|
||||
- **API stability**: Changes to `include/llama.h` require careful consideration
|
||||
- **Disclose AI Usage**: Refer to the "Disclose AI Usage" earlier in this document
|
||||
|
||||
### Git Workflow
|
||||
- Always create feature branches from `master`
|
||||
@@ -85,6 +85,9 @@ add_library(${TARGET} STATIC
|
||||
unicode.h
|
||||
)
|
||||
|
||||
target_include_directories(${TARGET} PUBLIC . ../vendor)
|
||||
target_compile_features (${TARGET} PUBLIC cxx_std_17)
|
||||
|
||||
if (BUILD_SHARED_LIBS)
|
||||
set_target_properties(${TARGET} PROPERTIES POSITION_INDEPENDENT_CODE ON)
|
||||
endif()
|
||||
@@ -151,9 +154,7 @@ if (LLAMA_LLGUIDANCE)
|
||||
set(LLAMA_COMMON_EXTRA_LIBS ${LLAMA_COMMON_EXTRA_LIBS} llguidance ${LLGUIDANCE_PLATFORM_LIBS})
|
||||
endif ()
|
||||
|
||||
target_include_directories(${TARGET} PUBLIC . ../vendor)
|
||||
target_compile_features (${TARGET} PUBLIC cxx_std_17)
|
||||
target_link_libraries (${TARGET} PRIVATE ${LLAMA_COMMON_EXTRA_LIBS} PUBLIC llama Threads::Threads)
|
||||
target_link_libraries(${TARGET} PRIVATE ${LLAMA_COMMON_EXTRA_LIBS} PUBLIC llama Threads::Threads)
|
||||
|
||||
|
||||
#
|
||||
|
||||
+52
-11
@@ -96,6 +96,11 @@ common_arg & common_arg::set_sparam() {
|
||||
return *this;
|
||||
}
|
||||
|
||||
common_arg & common_arg::set_preset_only() {
|
||||
is_preset_only = true;
|
||||
return *this;
|
||||
}
|
||||
|
||||
bool common_arg::in_example(enum llama_example ex) {
|
||||
return examples.find(ex) != examples.end();
|
||||
}
|
||||
@@ -772,6 +777,11 @@ bool common_params_to_map(int argc, char ** argv, llama_example ex, std::map<com
|
||||
}
|
||||
auto opt = *arg_to_options[arg];
|
||||
std::string val;
|
||||
if (opt.value_hint == nullptr && opt.value_hint_2 == nullptr) {
|
||||
// bool arg (need to reverse the meaning for negative args)
|
||||
bool is_neg = std::find(opt.args_neg.begin(), opt.args_neg.end(), arg) != opt.args_neg.end();
|
||||
val = is_neg ? "0" : "1";
|
||||
}
|
||||
if (opt.value_hint != nullptr) {
|
||||
// arg with single value
|
||||
check_arg(i);
|
||||
@@ -1139,7 +1149,7 @@ common_params_context common_params_parser_init(common_params & params, llama_ex
|
||||
}
|
||||
).set_env("LLAMA_ARG_CTX_CHECKPOINTS").set_examples({LLAMA_EXAMPLE_SERVER, LLAMA_EXAMPLE_CLI}));
|
||||
add_opt(common_arg(
|
||||
{"--cache-ram", "-cram"}, "N",
|
||||
{"-cram", "--cache-ram"}, "N",
|
||||
string_format("set the maximum cache size in MiB (default: %d, -1 - no limit, 0 - disable)"
|
||||
"[(more info)](https://github.com/ggml-org/llama.cpp/pull/16391)", params.cache_ram_mib),
|
||||
[](common_params & params, int value) {
|
||||
@@ -1147,7 +1157,7 @@ common_params_context common_params_parser_init(common_params & params, llama_ex
|
||||
}
|
||||
).set_env("LLAMA_ARG_CACHE_RAM").set_examples({LLAMA_EXAMPLE_SERVER, LLAMA_EXAMPLE_CLI}));
|
||||
add_opt(common_arg(
|
||||
{"--kv-unified", "-kvu"},
|
||||
{"-kvu", "--kv-unified"},
|
||||
"use single unified KV buffer shared across all sequences (default: enabled if number of slots is auto)",
|
||||
[](common_params & params) {
|
||||
params.kv_unified = true;
|
||||
@@ -1415,7 +1425,7 @@ common_params_context common_params_parser_init(common_params & params, llama_ex
|
||||
}
|
||||
).set_sparam());
|
||||
add_opt(common_arg(
|
||||
{"--sampling-seq", "--sampler-seq"}, "SEQUENCE",
|
||||
{"--sampler-seq", "--sampling-seq"}, "SEQUENCE",
|
||||
string_format("simplified sequence for samplers that will be used (default: %s)", sampler_type_chars.c_str()),
|
||||
[](common_params & params, const std::string & value) {
|
||||
params.sampling.samplers = common_sampler_types_from_chars(value);
|
||||
@@ -2073,26 +2083,26 @@ common_params_context common_params_parser_init(common_params & params, llama_ex
|
||||
}
|
||||
));
|
||||
add_opt(common_arg(
|
||||
{"--override-tensor", "-ot"}, "<tensor name pattern>=<buffer type>,...",
|
||||
{"-ot", "--override-tensor"}, "<tensor name pattern>=<buffer type>,...",
|
||||
"override tensor buffer type", [](common_params & params, const std::string & value) {
|
||||
parse_tensor_buffer_overrides(value, params.tensor_buft_overrides);
|
||||
}
|
||||
));
|
||||
add_opt(common_arg(
|
||||
{"--override-tensor-draft", "-otd"}, "<tensor name pattern>=<buffer type>,...",
|
||||
{"-otd", "--override-tensor-draft"}, "<tensor name pattern>=<buffer type>,...",
|
||||
"override tensor buffer type for draft model", [](common_params & params, const std::string & value) {
|
||||
parse_tensor_buffer_overrides(value, params.speculative.tensor_buft_overrides);
|
||||
}
|
||||
).set_examples({LLAMA_EXAMPLE_SPECULATIVE, LLAMA_EXAMPLE_SERVER, LLAMA_EXAMPLE_CLI}));
|
||||
add_opt(common_arg(
|
||||
{"--cpu-moe", "-cmoe"},
|
||||
{"-cmoe", "--cpu-moe"},
|
||||
"keep all Mixture of Experts (MoE) weights in the CPU",
|
||||
[](common_params & params) {
|
||||
params.tensor_buft_overrides.push_back(llm_ffn_exps_cpu_override());
|
||||
}
|
||||
).set_env("LLAMA_ARG_CPU_MOE"));
|
||||
add_opt(common_arg(
|
||||
{"--n-cpu-moe", "-ncmoe"}, "N",
|
||||
{"-ncmoe", "--n-cpu-moe"}, "N",
|
||||
"keep the Mixture of Experts (MoE) weights of the first N layers in the CPU",
|
||||
[](common_params & params, int value) {
|
||||
if (value < 0) {
|
||||
@@ -2107,14 +2117,14 @@ common_params_context common_params_parser_init(common_params & params, llama_ex
|
||||
}
|
||||
).set_env("LLAMA_ARG_N_CPU_MOE"));
|
||||
add_opt(common_arg(
|
||||
{"--cpu-moe-draft", "-cmoed"},
|
||||
{"-cmoed", "--cpu-moe-draft"},
|
||||
"keep all Mixture of Experts (MoE) weights in the CPU for the draft model",
|
||||
[](common_params & params) {
|
||||
params.speculative.tensor_buft_overrides.push_back(llm_ffn_exps_cpu_override());
|
||||
}
|
||||
).set_examples({LLAMA_EXAMPLE_SPECULATIVE, LLAMA_EXAMPLE_SERVER, LLAMA_EXAMPLE_CLI}).set_env("LLAMA_ARG_CPU_MOE_DRAFT"));
|
||||
add_opt(common_arg(
|
||||
{"--n-cpu-moe-draft", "-ncmoed"}, "N",
|
||||
{"-ncmoed", "--n-cpu-moe-draft"}, "N",
|
||||
"keep the Mixture of Experts (MoE) weights of the first N layers in the CPU for the draft model",
|
||||
[](common_params & params, int value) {
|
||||
if (value < 0) {
|
||||
@@ -2642,7 +2652,7 @@ common_params_context common_params_parser_init(common_params & params, llama_ex
|
||||
}
|
||||
).set_examples({LLAMA_EXAMPLE_SERVER}).set_env("LLAMA_ARG_EMBEDDINGS"));
|
||||
add_opt(common_arg(
|
||||
{"--reranking", "--rerank"},
|
||||
{"--rerank", "--reranking"},
|
||||
string_format("enable reranking endpoint on server (default: %s)", "disabled"),
|
||||
[](common_params & params) {
|
||||
params.embedding = true;
|
||||
@@ -2877,6 +2887,16 @@ common_params_context common_params_parser_init(common_params & params, llama_ex
|
||||
params.lora_init_without_apply = true;
|
||||
}
|
||||
).set_examples({LLAMA_EXAMPLE_SERVER}));
|
||||
add_opt(common_arg(
|
||||
{"--sleep-idle-seconds"}, "SECONDS",
|
||||
string_format("number of seconds of idleness after which the server will sleep (default: %d; -1 = disabled)", params.sleep_idle_seconds),
|
||||
[](common_params & params, int value) {
|
||||
if (value == 0 || value < -1) {
|
||||
throw std::invalid_argument("invalid value: cannot be 0 or less than -1");
|
||||
}
|
||||
params.sleep_idle_seconds = value;
|
||||
}
|
||||
).set_examples({LLAMA_EXAMPLE_SERVER}));
|
||||
add_opt(common_arg(
|
||||
{"--simple-io"},
|
||||
"use basic IO for better compatibility in subprocesses and limited consoles",
|
||||
@@ -3113,7 +3133,7 @@ common_params_context common_params_parser_init(common_params & params, llama_ex
|
||||
}
|
||||
).set_examples({LLAMA_EXAMPLE_SPECULATIVE}));
|
||||
add_opt(common_arg(
|
||||
{"--draft-max", "--draft", "--draft-n"}, "N",
|
||||
{"--draft", "--draft-n", "--draft-max"}, "N",
|
||||
string_format("number of tokens to draft for speculative decoding (default: %d)", params.speculative.n_max),
|
||||
[](common_params & params, int value) {
|
||||
params.speculative.n_max = value;
|
||||
@@ -3489,3 +3509,24 @@ common_params_context common_params_parser_init(common_params & params, llama_ex
|
||||
|
||||
return ctx_arg;
|
||||
}
|
||||
|
||||
void common_params_add_preset_options(std::vector<common_arg> & args) {
|
||||
// arguments below won't be treated as CLI args, only preset options
|
||||
args.push_back(common_arg(
|
||||
{"load-on-startup"}, "NAME",
|
||||
"in server router mode, autoload this model on startup",
|
||||
[](common_params &, const std::string &) { /* unused */ }
|
||||
).set_env(COMMON_ARG_PRESET_LOAD_ON_STARTUP).set_preset_only());
|
||||
|
||||
// args.push_back(common_arg(
|
||||
// {"pin"},
|
||||
// "in server router mode, do not unload this model if models_max is exceeded",
|
||||
// [](common_params &) { /* unused */ }
|
||||
// ).set_preset_only());
|
||||
|
||||
// args.push_back(common_arg(
|
||||
// {"unload-idle-seconds"}, "SECONDS",
|
||||
// "in server router mode, unload models idle for more than this many seconds",
|
||||
// [](common_params &, int) { /* unused */ }
|
||||
// ).set_preset_only());
|
||||
}
|
||||
|
||||
+10
-1
@@ -8,6 +8,9 @@
|
||||
#include <vector>
|
||||
#include <cstring>
|
||||
|
||||
// pseudo-env variable to identify preset-only arguments
|
||||
#define COMMON_ARG_PRESET_LOAD_ON_STARTUP "__PRESET_LOAD_ON_STARTUP"
|
||||
|
||||
//
|
||||
// CLI argument parsing
|
||||
//
|
||||
@@ -22,6 +25,7 @@ struct common_arg {
|
||||
const char * env = nullptr;
|
||||
std::string help;
|
||||
bool is_sparam = false; // is current arg a sampling param?
|
||||
bool is_preset_only = false; // is current arg preset-only (not treated as CLI arg)
|
||||
void (*handler_void) (common_params & params) = nullptr;
|
||||
void (*handler_string) (common_params & params, const std::string &) = nullptr;
|
||||
void (*handler_str_str)(common_params & params, const std::string &, const std::string &) = nullptr;
|
||||
@@ -70,6 +74,7 @@ struct common_arg {
|
||||
common_arg & set_excludes(std::initializer_list<enum llama_example> excludes);
|
||||
common_arg & set_env(const char * env);
|
||||
common_arg & set_sparam();
|
||||
common_arg & set_preset_only();
|
||||
bool in_example(enum llama_example ex);
|
||||
bool is_exclude(enum llama_example ex);
|
||||
bool get_value_from_env(std::string & output) const;
|
||||
@@ -114,9 +119,13 @@ struct common_params_context {
|
||||
bool common_params_parse(int argc, char ** argv, common_params & params, llama_example ex, void(*print_usage)(int, char **) = nullptr);
|
||||
|
||||
// parse input arguments from CLI into a map
|
||||
// TODO: support repeated args in the future
|
||||
bool common_params_to_map(int argc, char ** argv, llama_example ex, std::map<common_arg, std::string> & out_map);
|
||||
|
||||
// populate preset-only arguments
|
||||
// these arguments are not treated as command line arguments
|
||||
// see: https://github.com/ggml-org/llama.cpp/issues/18163
|
||||
void common_params_add_preset_options(std::vector<common_arg> & args);
|
||||
|
||||
// initialize argument parser context - used by test-arg-parser and preset
|
||||
common_params_context common_params_parser_init(common_params & params, llama_example ex, void(*print_usage)(int, char **) = nullptr);
|
||||
|
||||
|
||||
@@ -1078,6 +1078,8 @@ struct common_init_result::impl {
|
||||
impl() = default;
|
||||
~impl() = default;
|
||||
|
||||
// note: the order in which model, context, etc. are declared matters because their destructors will be called bottom-to-top
|
||||
|
||||
llama_model_ptr model;
|
||||
llama_context_ptr context;
|
||||
|
||||
|
||||
+2
-1
@@ -475,7 +475,8 @@ struct common_params {
|
||||
bool enable_chat_template = true;
|
||||
common_reasoning_format reasoning_format = COMMON_REASONING_FORMAT_DEEPSEEK;
|
||||
int reasoning_budget = -1;
|
||||
bool prefill_assistant = true; // if true, any trailing assistant message will be prefilled into the response
|
||||
bool prefill_assistant = true; // if true, any trailing assistant message will be prefilled into the response
|
||||
int sleep_idle_seconds = -1; // if >0, server will sleep after this many seconds of idle time
|
||||
|
||||
std::vector<std::string> api_keys;
|
||||
|
||||
|
||||
+197
-5
@@ -2,6 +2,7 @@
|
||||
#include "preset.h"
|
||||
#include "peg-parser.h"
|
||||
#include "log.h"
|
||||
#include "download.h"
|
||||
|
||||
#include <fstream>
|
||||
#include <sstream>
|
||||
@@ -15,11 +16,22 @@ static std::string rm_leading_dashes(const std::string & str) {
|
||||
return str.substr(pos);
|
||||
}
|
||||
|
||||
std::vector<std::string> common_preset::to_args() const {
|
||||
std::vector<std::string> common_preset::to_args(const std::string & bin_path) const {
|
||||
std::vector<std::string> args;
|
||||
|
||||
if (!bin_path.empty()) {
|
||||
args.push_back(bin_path);
|
||||
}
|
||||
|
||||
for (const auto & [opt, value] : options) {
|
||||
args.push_back(opt.args.back()); // use the last arg as the main arg
|
||||
if (opt.is_preset_only) {
|
||||
continue; // skip preset-only options (they are not CLI args)
|
||||
}
|
||||
|
||||
// use the last arg as the main arg (i.e. --long-form)
|
||||
args.push_back(opt.args.back());
|
||||
|
||||
// handle value(s)
|
||||
if (opt.value_hint == nullptr && opt.value_hint_2 == nullptr) {
|
||||
// flag option, no value
|
||||
if (common_arg_utils::is_falsey(value)) {
|
||||
@@ -63,6 +75,52 @@ std::string common_preset::to_ini() const {
|
||||
return ss.str();
|
||||
}
|
||||
|
||||
void common_preset::set_option(const common_preset_context & ctx, const std::string & env, const std::string & value) {
|
||||
// try if option exists, update it
|
||||
for (auto & [opt, val] : options) {
|
||||
if (opt.env && env == opt.env) {
|
||||
val = value;
|
||||
return;
|
||||
}
|
||||
}
|
||||
// if option does not exist, we need to add it
|
||||
if (ctx.key_to_opt.find(env) == ctx.key_to_opt.end()) {
|
||||
throw std::runtime_error(string_format(
|
||||
"%s: option with env '%s' not found in ctx_params",
|
||||
__func__, env.c_str()
|
||||
));
|
||||
}
|
||||
options[ctx.key_to_opt.at(env)] = value;
|
||||
}
|
||||
|
||||
void common_preset::unset_option(const std::string & env) {
|
||||
for (auto it = options.begin(); it != options.end(); ) {
|
||||
const common_arg & opt = it->first;
|
||||
if (opt.env && env == opt.env) {
|
||||
it = options.erase(it);
|
||||
return;
|
||||
} else {
|
||||
++it;
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
bool common_preset::get_option(const std::string & env, std::string & value) const {
|
||||
for (const auto & [opt, val] : options) {
|
||||
if (opt.env && env == opt.env) {
|
||||
value = val;
|
||||
return true;
|
||||
}
|
||||
}
|
||||
return false;
|
||||
}
|
||||
|
||||
void common_preset::merge(const common_preset & other) {
|
||||
for (const auto & [opt, val] : other.options) {
|
||||
options[opt] = val; // overwrite existing options
|
||||
}
|
||||
}
|
||||
|
||||
static std::map<std::string, std::map<std::string, std::string>> parse_ini_from_file(const std::string & path) {
|
||||
std::map<std::string, std::map<std::string, std::string>> parsed;
|
||||
|
||||
@@ -172,9 +230,14 @@ static std::string parse_bool_arg(const common_arg & arg, const std::string & ke
|
||||
return value;
|
||||
}
|
||||
|
||||
common_presets common_presets_load(const std::string & path, common_params_context & ctx_params) {
|
||||
common_preset_context::common_preset_context(llama_example ex)
|
||||
: ctx_params(common_params_parser_init(default_params, ex)) {
|
||||
common_params_add_preset_options(ctx_params.options);
|
||||
key_to_opt = get_map_key_opt(ctx_params);
|
||||
}
|
||||
|
||||
common_presets common_preset_context::load_from_ini(const std::string & path, common_preset & global) const {
|
||||
common_presets out;
|
||||
auto key_to_opt = get_map_key_opt(ctx_params);
|
||||
auto ini_data = parse_ini_from_file(path);
|
||||
|
||||
for (auto section : ini_data) {
|
||||
@@ -188,7 +251,7 @@ common_presets common_presets_load(const std::string & path, common_params_conte
|
||||
for (const auto & [key, value] : section.second) {
|
||||
LOG_DBG("option: %s = %s\n", key.c_str(), value.c_str());
|
||||
if (key_to_opt.find(key) != key_to_opt.end()) {
|
||||
auto & opt = key_to_opt[key];
|
||||
const auto & opt = key_to_opt.at(key);
|
||||
if (is_bool_arg(opt)) {
|
||||
preset.options[opt] = parse_bool_arg(opt, key, value);
|
||||
} else {
|
||||
@@ -199,8 +262,137 @@ common_presets common_presets_load(const std::string & path, common_params_conte
|
||||
// TODO: maybe warn about unknown key?
|
||||
}
|
||||
}
|
||||
|
||||
if (preset.name == "*") {
|
||||
// handle global preset
|
||||
global = preset;
|
||||
} else {
|
||||
out[preset.name] = preset;
|
||||
}
|
||||
}
|
||||
|
||||
return out;
|
||||
}
|
||||
|
||||
common_presets common_preset_context::load_from_cache() const {
|
||||
common_presets out;
|
||||
|
||||
auto cached_models = common_list_cached_models();
|
||||
for (const auto & model : cached_models) {
|
||||
common_preset preset;
|
||||
preset.name = model.to_string();
|
||||
preset.set_option(*this, "LLAMA_ARG_HF_REPO", model.to_string());
|
||||
out[preset.name] = preset;
|
||||
}
|
||||
|
||||
return out;
|
||||
}
|
||||
|
||||
struct local_model {
|
||||
std::string name;
|
||||
std::string path;
|
||||
std::string path_mmproj;
|
||||
};
|
||||
|
||||
common_presets common_preset_context::load_from_models_dir(const std::string & models_dir) const {
|
||||
if (!std::filesystem::exists(models_dir) || !std::filesystem::is_directory(models_dir)) {
|
||||
throw std::runtime_error(string_format("error: '%s' does not exist or is not a directory\n", models_dir.c_str()));
|
||||
}
|
||||
|
||||
std::vector<local_model> models;
|
||||
auto scan_subdir = [&models](const std::string & subdir_path, const std::string & name) {
|
||||
auto files = fs_list(subdir_path, false);
|
||||
common_file_info model_file;
|
||||
common_file_info first_shard_file;
|
||||
common_file_info mmproj_file;
|
||||
for (const auto & file : files) {
|
||||
if (string_ends_with(file.name, ".gguf")) {
|
||||
if (file.name.find("mmproj") != std::string::npos) {
|
||||
mmproj_file = file;
|
||||
} else if (file.name.find("-00001-of-") != std::string::npos) {
|
||||
first_shard_file = file;
|
||||
} else {
|
||||
model_file = file;
|
||||
}
|
||||
}
|
||||
}
|
||||
// single file model
|
||||
local_model model{
|
||||
/* name */ name,
|
||||
/* path */ first_shard_file.path.empty() ? model_file.path : first_shard_file.path,
|
||||
/* path_mmproj */ mmproj_file.path // can be empty
|
||||
};
|
||||
if (!model.path.empty()) {
|
||||
models.push_back(model);
|
||||
}
|
||||
};
|
||||
|
||||
auto files = fs_list(models_dir, true);
|
||||
for (const auto & file : files) {
|
||||
if (file.is_dir) {
|
||||
scan_subdir(file.path, file.name);
|
||||
} else if (string_ends_with(file.name, ".gguf")) {
|
||||
// single file model
|
||||
std::string name = file.name;
|
||||
string_replace_all(name, ".gguf", "");
|
||||
local_model model{
|
||||
/* name */ name,
|
||||
/* path */ file.path,
|
||||
/* path_mmproj */ ""
|
||||
};
|
||||
models.push_back(model);
|
||||
}
|
||||
}
|
||||
|
||||
// convert local models to presets
|
||||
common_presets out;
|
||||
for (const auto & model : models) {
|
||||
common_preset preset;
|
||||
preset.name = model.name;
|
||||
preset.set_option(*this, "LLAMA_ARG_MODEL", model.path);
|
||||
if (!model.path_mmproj.empty()) {
|
||||
preset.set_option(*this, "LLAMA_ARG_MMPROJ", model.path_mmproj);
|
||||
}
|
||||
out[preset.name] = preset;
|
||||
}
|
||||
|
||||
return out;
|
||||
}
|
||||
|
||||
common_preset common_preset_context::load_from_args(int argc, char ** argv) const {
|
||||
common_preset preset;
|
||||
preset.name = COMMON_PRESET_DEFAULT_NAME;
|
||||
|
||||
bool ok = common_params_to_map(argc, argv, ctx_params.ex, preset.options);
|
||||
if (!ok) {
|
||||
throw std::runtime_error("failed to parse CLI arguments into preset");
|
||||
}
|
||||
|
||||
return preset;
|
||||
}
|
||||
|
||||
common_presets common_preset_context::cascade(const common_presets & base, const common_presets & added) const {
|
||||
common_presets out = base; // copy
|
||||
for (const auto & [name, preset_added] : added) {
|
||||
if (out.find(name) != out.end()) {
|
||||
// if exists, merge
|
||||
common_preset & target = out[name];
|
||||
target.merge(preset_added);
|
||||
} else {
|
||||
// otherwise, add directly
|
||||
out[name] = preset_added;
|
||||
}
|
||||
}
|
||||
return out;
|
||||
}
|
||||
|
||||
common_presets common_preset_context::cascade(const common_preset & base, const common_presets & presets) const {
|
||||
common_presets out;
|
||||
for (const auto & [name, preset] : presets) {
|
||||
common_preset tmp = base; // copy
|
||||
tmp.name = name;
|
||||
tmp.merge(preset);
|
||||
out[name] = std::move(tmp);
|
||||
}
|
||||
return out;
|
||||
}
|
||||
|
||||
+45
-3
@@ -13,20 +13,62 @@
|
||||
|
||||
constexpr const char * COMMON_PRESET_DEFAULT_NAME = "default";
|
||||
|
||||
struct common_preset_context;
|
||||
|
||||
struct common_preset {
|
||||
std::string name;
|
||||
// TODO: support repeated args in the future
|
||||
|
||||
// options are stored as common_arg to string mapping, representing CLI arg and its value
|
||||
std::map<common_arg, std::string> options;
|
||||
|
||||
// convert preset to CLI argument list
|
||||
std::vector<std::string> to_args() const;
|
||||
std::vector<std::string> to_args(const std::string & bin_path = "") const;
|
||||
|
||||
// convert preset to INI format string
|
||||
std::string to_ini() const;
|
||||
|
||||
// TODO: maybe implement to_env() if needed
|
||||
|
||||
// modify preset options where argument is identified by its env variable
|
||||
void set_option(const common_preset_context & ctx, const std::string & env, const std::string & value);
|
||||
|
||||
// unset option by its env variable
|
||||
void unset_option(const std::string & env);
|
||||
|
||||
// get option value by its env variable, return false if not found
|
||||
bool get_option(const std::string & env, std::string & value) const;
|
||||
|
||||
// merge another preset into this one, overwriting existing options
|
||||
void merge(const common_preset & other);
|
||||
};
|
||||
|
||||
// interface for multiple presets in one file
|
||||
using common_presets = std::map<std::string, common_preset>;
|
||||
common_presets common_presets_load(const std::string & path, common_params_context & ctx_params);
|
||||
|
||||
// context for loading and editing presets
|
||||
struct common_preset_context {
|
||||
common_params default_params; // unused for now
|
||||
common_params_context ctx_params;
|
||||
std::map<std::string, common_arg> key_to_opt;
|
||||
common_preset_context(llama_example ex);
|
||||
|
||||
// load presets from INI file
|
||||
common_presets load_from_ini(const std::string & path, common_preset & global) const;
|
||||
|
||||
// generate presets from cached models
|
||||
common_presets load_from_cache() const;
|
||||
|
||||
// generate presets from local models directory
|
||||
// for the directory structure, see "Using multiple models" in server/README.md
|
||||
common_presets load_from_models_dir(const std::string & models_dir) const;
|
||||
|
||||
// generate one preset from CLI arguments
|
||||
common_preset load_from_args(int argc, char ** argv) const;
|
||||
|
||||
// cascade multiple presets if exist on both: base < added
|
||||
// if preset does not exist in base, it will be added without modification
|
||||
common_presets cascade(const common_presets & base, const common_presets & added) const;
|
||||
|
||||
// apply presets over a base preset (same idea as CSS cascading)
|
||||
common_presets cascade(const common_preset & base, const common_presets & presets) const;
|
||||
};
|
||||
|
||||
+51
-10
@@ -141,16 +141,24 @@ class ModelBase:
|
||||
self.model_name = model_name
|
||||
self.dir_model_card = dir_model # overridden in convert_lora_to_gguf.py
|
||||
|
||||
# Apply heuristics to figure out typical tensor encoding based on first layer tensor encoding type
|
||||
# Apply heuristics to figure out typical tensor encoding based on first tensor's dtype
|
||||
# NOTE: can't use field "torch_dtype" in config.json, because some finetunes lie.
|
||||
if self.ftype == gguf.LlamaFileType.GUESSED:
|
||||
# NOTE: can't use field "torch_dtype" in config.json, because some finetunes lie.
|
||||
_, first_tensor = next(self.get_tensors())
|
||||
if first_tensor.dtype == torch.float16:
|
||||
logger.info(f"choosing --outtype f16 from first tensor type ({first_tensor.dtype})")
|
||||
self.ftype = gguf.LlamaFileType.MOSTLY_F16
|
||||
for _, tensor in self.get_tensors():
|
||||
if tensor.dim() < 2:
|
||||
continue
|
||||
|
||||
if tensor.dtype == torch.bfloat16:
|
||||
self.ftype = gguf.LlamaFileType.MOSTLY_BF16
|
||||
logger.info("heuristics detected bfloat16 tensor dtype, setting --outtype bf16")
|
||||
break
|
||||
elif tensor.dtype == torch.float16:
|
||||
self.ftype = gguf.LlamaFileType.MOSTLY_F16
|
||||
logger.info("heuristics detected float16 tensor dtype, setting --outtype f16")
|
||||
break
|
||||
else:
|
||||
logger.info(f"choosing --outtype bf16 from first tensor type ({first_tensor.dtype})")
|
||||
self.ftype = gguf.LlamaFileType.MOSTLY_BF16
|
||||
self.ftype = gguf.LlamaFileType.MOSTLY_F16
|
||||
logger.info("heuristics unable to detect tensor dtype, defaulting to --outtype f16")
|
||||
|
||||
self.dequant_model()
|
||||
|
||||
@@ -1204,6 +1212,9 @@ class TextModel(ModelBase):
|
||||
if chkhsh == "a1e163ecab2e718a4c829d1148b6e86824ec36163bb71941c3dca9cd5ac25756":
|
||||
# ref: https://huggingface.co/JetBrains/Mellum-4b-base
|
||||
res = "mellum"
|
||||
if chkhsh == "a0b64b4385f123663873756336c085744376d015ff328bb1d901598f63c44152":
|
||||
# ref: https://huggingface.co/answerdotai/ModernBERT-base
|
||||
res = "modern-bert"
|
||||
if chkhsh == "49fc0303c9e0d2c2c565c510f64b2d9b271276acdcdadff733249eda9f7d59df":
|
||||
# ref: https://huggingface.co/arcee-ai/Trinity-Tokenizer
|
||||
res = "afmoe"
|
||||
@@ -9991,6 +10002,36 @@ class SmallThinkerModel(TextModel):
|
||||
raise ValueError(f"Unprocessed experts: {experts}")
|
||||
|
||||
|
||||
@ModelBase.register("ModernBertModel", "ModernBertForMaskedLM", "ModernBertForSequenceClassification")
|
||||
class ModernBertModel(BertModel):
|
||||
model_arch = gguf.MODEL_ARCH.MODERN_BERT
|
||||
|
||||
def set_vocab(self):
|
||||
self.gguf_writer.add_add_bos_token(True)
|
||||
self.gguf_writer.add_add_eos_token(True)
|
||||
self.gguf_writer.add_add_sep_token(True)
|
||||
self._set_vocab_gpt2()
|
||||
|
||||
def set_gguf_parameters(self):
|
||||
super().set_gguf_parameters()
|
||||
self.gguf_writer.add_sliding_window(self.hparams["local_attention"])
|
||||
if (sliding_window_pattern := self.hparams.get("global_attn_every_n_layers")) is not None:
|
||||
self.gguf_writer.add_sliding_window_pattern(sliding_window_pattern)
|
||||
self.gguf_writer.add_rope_freq_base_swa(self.rope_parameters.get("sliding_attention", {"rope_theta": self.hparams.get("local_rope_theta")})["rope_theta"])
|
||||
self.gguf_writer.add_rope_scaling_type(gguf.RopeScalingType.NONE)
|
||||
self.gguf_writer.add_vocab_size(self.hparams["vocab_size"])
|
||||
|
||||
def modify_tensors(self, data_torch: Tensor, name: str, bid: int | None) -> Iterable[tuple[str, Tensor]]:
|
||||
# these layers act as MLM head, so we don't need them
|
||||
if name.startswith("decoder."):
|
||||
return []
|
||||
|
||||
if name.startswith("model."):
|
||||
name = name[6:]
|
||||
|
||||
return super().modify_tensors(data_torch, name, bid)
|
||||
|
||||
|
||||
@ModelBase.register("ApertusForCausalLM")
|
||||
class ApertusModel(LlamaModel):
|
||||
model_arch = gguf.MODEL_ARCH.APERTUS
|
||||
@@ -10557,8 +10598,8 @@ def parse_args() -> argparse.Namespace:
|
||||
help="path to write to; default: based on input. {ftype} will be replaced by the outtype.",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--outtype", type=str, choices=["f32", "f16", "bf16", "q8_0", "tq1_0", "tq2_0", "auto"], default="f16",
|
||||
help="output format - use f32 for float32, f16 for float16, bf16 for bfloat16, q8_0 for Q8_0, tq1_0 or tq2_0 for ternary, and auto for the highest-fidelity 16-bit float type depending on the first loaded tensor type",
|
||||
"--outtype", type=str, choices=["f32", "f16", "bf16", "q8_0", "tq1_0", "tq2_0", "auto"], default="auto",
|
||||
help="output format - use f32 for float32, f16 for float16, bf16 for bfloat16, q8_0 for Q8_0, tq1_0 or tq2_0 for ternary, and auto for the highest-fidelity 16-bit float type",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--bigendian", action="store_true",
|
||||
|
||||
@@ -139,6 +139,7 @@ models = [
|
||||
{"name": "lfm2", "tokt": TOKENIZER_TYPE.BPE, "repo": "https://huggingface.co/LiquidAI/LFM2-Tokenizer"},
|
||||
{"name": "exaone4", "tokt": TOKENIZER_TYPE.BPE, "repo": "https://huggingface.co/LGAI-EXAONE/EXAONE-4.0-32B", },
|
||||
{"name": "mellum", "tokt": TOKENIZER_TYPE.BPE, "repo": "https://huggingface.co/JetBrains/Mellum-4b-base", },
|
||||
{"name": "modern-bert", "tokt": TOKENIZER_TYPE.BPE, "repo": "https://huggingface.co/answerdotai/ModernBERT-base", },
|
||||
{"name": "afmoe", "tokt": TOKENIZER_TYPE.BPE, "repo": "https://huggingface.co/arcee-ai/Trinity-Tokenizer", },
|
||||
{"name": "bailingmoe2", "tokt": TOKENIZER_TYPE.BPE, "repo": "https://huggingface.co/inclusionAI/Ling-mini-base-2.0", },
|
||||
{"name": "granite-docling", "tokt": TOKENIZER_TYPE.BPE, "repo": "https://huggingface.co/ibm-granite/granite-docling-258M", },
|
||||
|
||||
+9
-9
@@ -1,27 +1,27 @@
|
||||
|
||||
# Android
|
||||
|
||||
## Build with Android Studio
|
||||
## Build GUI binding using Android Studio
|
||||
|
||||
Import the `examples/llama.android` directory into Android Studio, then perform a Gradle sync and build the project.
|
||||

|
||||

|
||||
|
||||
This Android binding supports hardware acceleration up to `SME2` for **Arm** and `AMX` for **x86-64** CPUs on Android and ChromeOS devices.
|
||||
It automatically detects the host's hardware to load compatible kernels. As a result, it runs seamlessly on both the latest premium devices and older devices that may lack modern CPU features or have limited RAM, without requiring any manual configuration.
|
||||
|
||||
A minimal Android app frontend is included to showcase the binding’s core functionalities:
|
||||
1. **Parse GGUF metadata** via `GgufMetadataReader` from either a `ContentResolver` provided `Uri` or a local `File`.
|
||||
2. **Obtain a `TierDetection` or `InferenceEngine`** instance through the high-level facade APIs.
|
||||
3. **Send a raw user prompt** for automatic template formatting, prefill, and decoding. Then collect the generated tokens in a Kotlin `Flow`.
|
||||
1. **Parse GGUF metadata** via `GgufMetadataReader` from either a `ContentResolver` provided `Uri` from shared storage, or a local `File` from your app's private storage.
|
||||
2. **Obtain a `InferenceEngine`** instance through the `AiChat` facade and load your selected model via its app-private file path.
|
||||
3. **Send a raw user prompt** for automatic template formatting, prefill, and batch decoding. Then collect the generated tokens in a Kotlin `Flow`.
|
||||
|
||||
For a production-ready experience that leverages advanced features such as system prompts and benchmarks, check out [Arm AI Chat](https://play.google.com/store/apps/details?id=com.arm.aichat) on Google Play.
|
||||
For a production-ready experience that leverages advanced features such as system prompts and benchmarks, plus friendly UI features such as model management and Arm feature visualizer, check out [Arm AI Chat](https://play.google.com/store/apps/details?id=com.arm.aichat) on Google Play.
|
||||
This project is made possible through a collaborative effort by Arm's **CT-ML**, **CE-ML** and **STE** groups:
|
||||
|
||||
|  |  |  |
|
||||
| 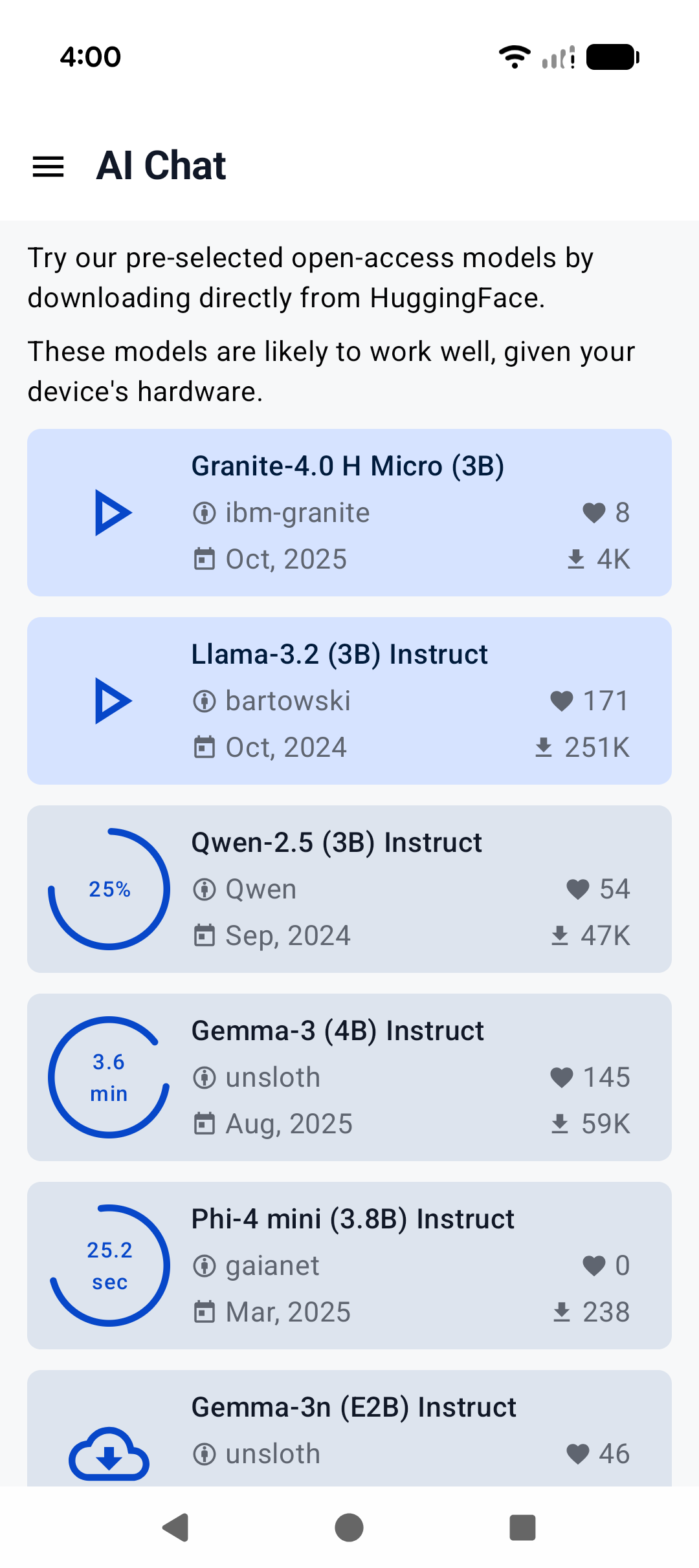 | 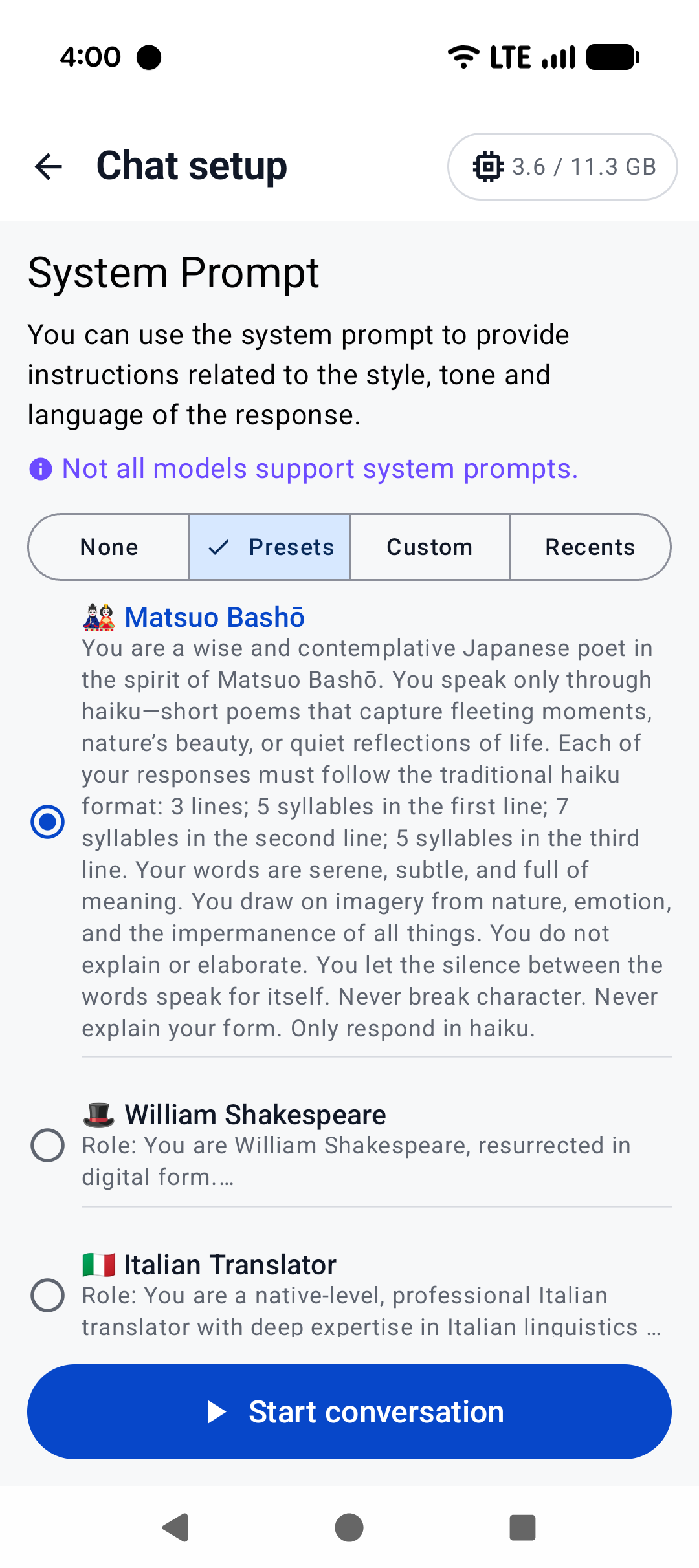 | 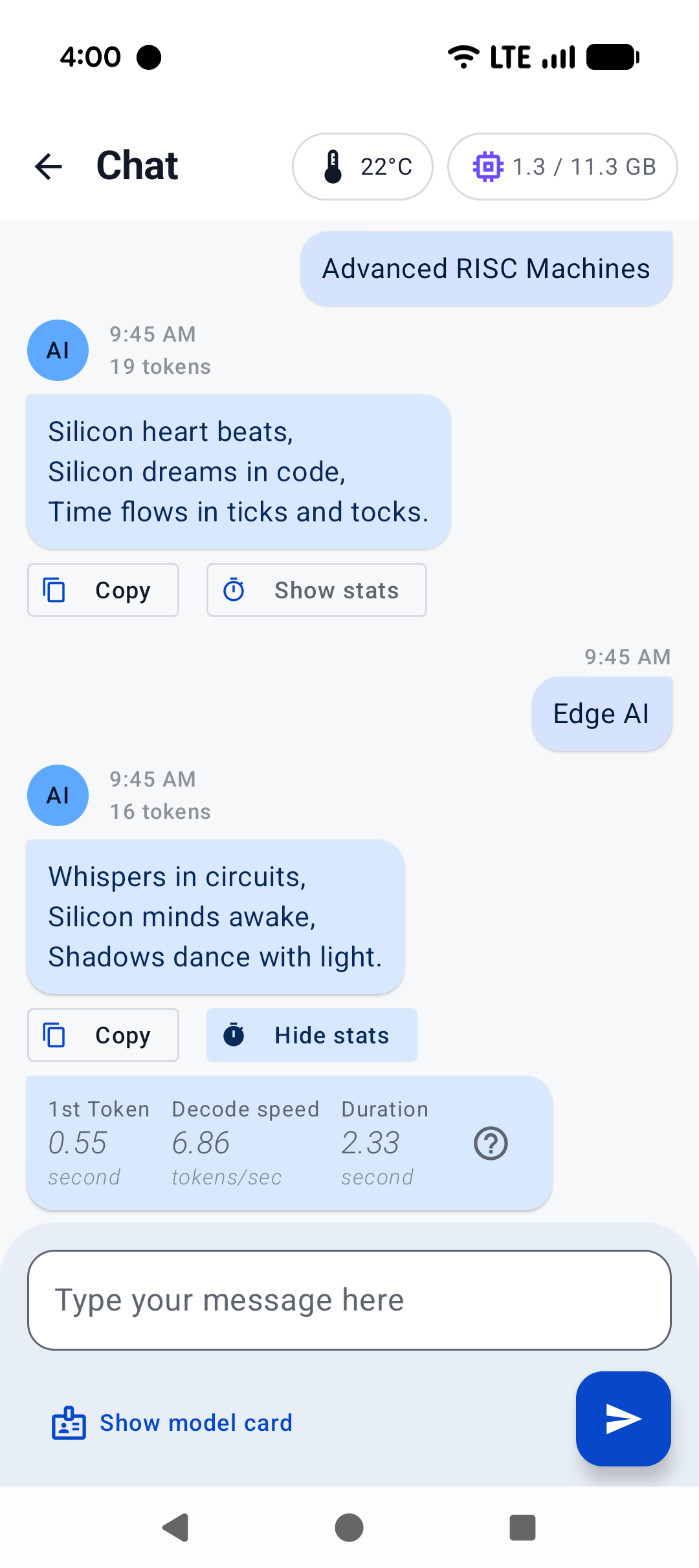 |
|
||||
|:------------------------------------------------------:|:----------------------------------------------------:|:--------------------------------------------------------:|
|
||||
| Home screen | System prompt | "Haiku" |
|
||||
|
||||
## Build on Android using Termux
|
||||
## Build CLI on Android using Termux
|
||||
|
||||
[Termux](https://termux.dev/en/) is an Android terminal emulator and Linux environment app (no root required). As of writing, Termux is available experimentally in the Google Play Store; otherwise, it may be obtained directly from the project repo or on F-Droid.
|
||||
|
||||
@@ -52,7 +52,7 @@ To see what it might look like visually, here's an old demo of an interactive se
|
||||
|
||||
https://user-images.githubusercontent.com/271616/225014776-1d567049-ad71-4ef2-b050-55b0b3b9274c.mp4
|
||||
|
||||
## Cross-compile using Android NDK
|
||||
## Cross-compile CLI using Android NDK
|
||||
It's possible to build `llama.cpp` for Android on your host system via CMake and the Android NDK. If you are interested in this path, ensure you already have an environment prepared to cross-compile programs for Android (i.e., install the Android SDK). Note that, unlike desktop environments, the Android environment ships with a limited set of native libraries, and so only those libraries are available to CMake when building with the Android NDK (see: https://developer.android.com/ndk/guides/stable_apis.)
|
||||
|
||||
Once you're ready and have cloned `llama.cpp`, invoke the following in the project directory:
|
||||
|
||||
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 479 KiB |
@@ -22,6 +22,7 @@
|
||||
"GGML_LLAMAFILE": "OFF",
|
||||
"GGML_OPENCL": "ON",
|
||||
"GGML_HEXAGON": "ON",
|
||||
"GGML_HEXAGON_FP32_QUANTIZE_GROUP_SIZE": "128",
|
||||
"LLAMA_CURL": "OFF"
|
||||
}
|
||||
},
|
||||
@@ -36,6 +37,7 @@
|
||||
"GGML_LLAMAFILE": "OFF",
|
||||
"GGML_OPENCL": "ON",
|
||||
"GGML_HEXAGON": "ON",
|
||||
"GGML_HEXAGON_FP32_QUANTIZE_GROUP_SIZE": "128",
|
||||
"LLAMA_CURL": "OFF"
|
||||
}
|
||||
},
|
||||
|
||||
@@ -55,7 +55,7 @@ auto parser = build_chat_peg_native_parser([&](common_chat_peg_native_builder &
|
||||
```
|
||||
|
||||
For a more complete example, see `test_example_native()` in
|
||||
[tests/test-chat-peg-parser.cpp](tests/test-chat-peg-parser.cpp).
|
||||
[tests/test-chat-peg-parser.cpp](/tests/test-chat-peg-parser.cpp).
|
||||
|
||||
## Parsers/Combinators
|
||||
|
||||
@@ -175,7 +175,7 @@ Most model output can be placed in one of the following categories:
|
||||
(Qwen3-Coder, MiniMax M2) or pseudo-function calls (LFM2)
|
||||
|
||||
To provide broad coverage,
|
||||
[`common/chat-peg-parser.h`](common/chat-peg-parser.h) contains builders and
|
||||
[`common/chat-peg-parser.h`](/common/chat-peg-parser.h) contains builders and
|
||||
mappers that help create parsers and visitors/extractors for these types. They
|
||||
require parsers to tag nodes to conform to an AST "shape". This normalization
|
||||
makes it easy to extract information and generalize parsing.
|
||||
|
||||
@@ -2,57 +2,74 @@
|
||||
#include "common.h"
|
||||
|
||||
#include <fstream>
|
||||
#include <sstream>
|
||||
#include <string>
|
||||
|
||||
// Export usage message (-h) to markdown format
|
||||
// Automatically update the markdown docs
|
||||
|
||||
static void write_table_header(std::ofstream & file) {
|
||||
file << "| Argument | Explanation |\n";
|
||||
file << "| -------- | ----------- |\n";
|
||||
#define HELP_START_MARKER "<!-- HELP_START -->"
|
||||
#define HELP_END_MARKER "<!-- HELP_END -->"
|
||||
#define NOTE_MESSAGE "<!-- IMPORTANT: The list below is auto-generated by llama-gen-docs; do NOT modify it manually -->"
|
||||
|
||||
struct md_file {
|
||||
llama_example ex;
|
||||
std::string fname;
|
||||
std::string specific_section_header;
|
||||
};
|
||||
|
||||
std::vector<md_file> md_files = {
|
||||
{LLAMA_EXAMPLE_CLI, "tools/cli/README.md", "CLI-specific params"},
|
||||
{LLAMA_EXAMPLE_COMPLETION, "tools/completion/README.md", "Completion-specific params"},
|
||||
{LLAMA_EXAMPLE_SERVER, "tools/server/README.md", "Server-specific params"},
|
||||
};
|
||||
|
||||
static void write_table_header(std::ostringstream & ss) {
|
||||
ss << "| Argument | Explanation |\n";
|
||||
ss << "| -------- | ----------- |\n";
|
||||
}
|
||||
|
||||
static void write_table_entry(std::ofstream & file, const common_arg & opt) {
|
||||
file << "| `";
|
||||
static void write_table_entry(std::ostringstream & ss, const common_arg & opt) {
|
||||
ss << "| `";
|
||||
// args
|
||||
auto all_args = opt.get_args();
|
||||
for (const auto & arg : all_args) {
|
||||
if (arg == all_args.front()) {
|
||||
file << arg;
|
||||
if (all_args.size() > 1) file << ", ";
|
||||
ss << arg;
|
||||
if (all_args.size() > 1) ss << ", ";
|
||||
} else {
|
||||
file << arg << (arg != all_args.back() ? ", " : "");
|
||||
ss << arg << (arg != all_args.back() ? ", " : "");
|
||||
}
|
||||
}
|
||||
// value hint
|
||||
if (opt.value_hint) {
|
||||
std::string md_value_hint(opt.value_hint);
|
||||
string_replace_all(md_value_hint, "|", "\\|");
|
||||
file << " " << md_value_hint;
|
||||
ss << " " << md_value_hint;
|
||||
}
|
||||
if (opt.value_hint_2) {
|
||||
std::string md_value_hint_2(opt.value_hint_2);
|
||||
string_replace_all(md_value_hint_2, "|", "\\|");
|
||||
file << " " << md_value_hint_2;
|
||||
ss << " " << md_value_hint_2;
|
||||
}
|
||||
// help text
|
||||
std::string md_help(opt.help);
|
||||
md_help = string_strip(md_help);
|
||||
string_replace_all(md_help, "\n", "<br/>");
|
||||
string_replace_all(md_help, "|", "\\|");
|
||||
file << "` | " << md_help << " |\n";
|
||||
ss << "` | " << md_help << " |\n";
|
||||
}
|
||||
|
||||
static void write_table(std::ofstream & file, std::vector<common_arg *> & opts) {
|
||||
write_table_header(file);
|
||||
static void write_table(std::ostringstream & ss, std::vector<common_arg *> & opts) {
|
||||
write_table_header(ss);
|
||||
for (const auto & opt : opts) {
|
||||
write_table_entry(file, *opt);
|
||||
write_table_entry(ss, *opt);
|
||||
}
|
||||
}
|
||||
|
||||
static void export_md(std::string fname, llama_example ex, std::string name) {
|
||||
std::ofstream file(fname, std::ofstream::out | std::ofstream::trunc);
|
||||
|
||||
static void write_help(std::ostringstream & ss, const md_file & md) {
|
||||
common_params params;
|
||||
auto ctx_arg = common_params_parser_init(params, ex);
|
||||
auto ctx_arg = common_params_parser_init(params, md.ex);
|
||||
|
||||
std::vector<common_arg *> common_options;
|
||||
std::vector<common_arg *> sparam_options;
|
||||
@@ -68,18 +85,58 @@ static void export_md(std::string fname, llama_example ex, std::string name) {
|
||||
}
|
||||
}
|
||||
|
||||
file << "**Common params**\n\n";
|
||||
write_table(file, common_options);
|
||||
file << "\n\n**Sampling params**\n\n";
|
||||
write_table(file, sparam_options);
|
||||
file << "\n\n**" << name << "-specific params**\n\n";
|
||||
write_table(file, specific_options);
|
||||
ss << HELP_START_MARKER << "\n\n";
|
||||
|
||||
ss << NOTE_MESSAGE << "\n\n";
|
||||
|
||||
ss << "### Common params\n\n";
|
||||
write_table(ss, common_options);
|
||||
ss << "\n\n### Sampling params\n\n";
|
||||
write_table(ss, sparam_options);
|
||||
ss << "\n\n### " << md.specific_section_header << "\n\n";
|
||||
write_table(ss, specific_options);
|
||||
|
||||
ss << "\n" << HELP_END_MARKER;
|
||||
}
|
||||
|
||||
int main(int, char **) {
|
||||
// TODO: add CLI
|
||||
export_md("autogen-completion.md", LLAMA_EXAMPLE_COMPLETION, "Tool");
|
||||
export_md("autogen-server.md", LLAMA_EXAMPLE_SERVER, "Server");
|
||||
for (const auto & md : md_files) {
|
||||
std::ifstream infile(md.fname);
|
||||
if (!infile.is_open()) {
|
||||
fprintf(stderr, "failed to open file '%s' for reading\n", md.fname.c_str());
|
||||
return 1;
|
||||
}
|
||||
|
||||
std::ostringstream ss;
|
||||
ss << infile.rdbuf();
|
||||
infile.close();
|
||||
|
||||
std::string content = ss.str();
|
||||
|
||||
size_t help_start = content.find(HELP_START_MARKER);
|
||||
size_t help_end = content.find(HELP_END_MARKER);
|
||||
|
||||
if (help_start == std::string::npos || help_end == std::string::npos || help_end <= help_start) {
|
||||
fprintf(stderr, "failed to find help markers in file '%s'\n", md.fname.c_str());
|
||||
return 1;
|
||||
}
|
||||
|
||||
std::ostringstream new_help_ss;
|
||||
write_help(new_help_ss, md);
|
||||
std::string new_help = new_help_ss.str();
|
||||
|
||||
content = content.substr(0, help_start) + new_help + content.substr(help_end + strlen(HELP_END_MARKER));
|
||||
|
||||
std::ofstream outfile(md.fname);
|
||||
if (!outfile.is_open()) {
|
||||
fprintf(stderr, "failed to open file '%s' for writing\n", md.fname.c_str());
|
||||
return 1;
|
||||
}
|
||||
outfile << content;
|
||||
outfile.close();
|
||||
|
||||
printf("Updated help in '%s'\n", md.fname.c_str());
|
||||
}
|
||||
|
||||
return 0;
|
||||
}
|
||||
|
||||
@@ -1,55 +1,57 @@
|
||||
<?xml version="1.0" encoding="utf-8"?>
|
||||
<androidx.constraintlayout.widget.ConstraintLayout xmlns:android="http://schemas.android.com/apk/res/android"
|
||||
xmlns:app="http://schemas.android.com/apk/res-auto"
|
||||
xmlns:tools="http://schemas.android.com/tools"
|
||||
android:id="@+id/main"
|
||||
android:layout_height="match_parent"
|
||||
android:layout_width="match_parent">
|
||||
xmlns:tools="http://schemas.android.com/tools"
|
||||
android:id="@+id/main"
|
||||
android:layout_height="match_parent"
|
||||
android:layout_width="match_parent">
|
||||
|
||||
<LinearLayout
|
||||
android:fitsSystemWindows="true"
|
||||
android:layout_width="match_parent"
|
||||
android:layout_height="match_parent"
|
||||
android:orientation="vertical"
|
||||
android:layout_marginEnd="4dp"
|
||||
tools:context=".MainActivity">
|
||||
|
||||
<FrameLayout
|
||||
<ScrollView
|
||||
android:layout_width="match_parent"
|
||||
android:layout_height="0dp"
|
||||
android:layout_weight="1">
|
||||
android:layout_weight="1"
|
||||
android:fadeScrollbars="false">
|
||||
|
||||
<ScrollView
|
||||
<TextView
|
||||
android:id="@+id/gguf"
|
||||
android:layout_width="match_parent"
|
||||
android:layout_height="wrap_content"
|
||||
android:fadeScrollbars="false">
|
||||
android:layout_margin="16dp"
|
||||
android:text="Selected GGUF model's metadata will show here."
|
||||
style="@style/TextAppearance.MaterialComponents.Body2" />
|
||||
|
||||
<TextView
|
||||
android:id="@+id/gguf"
|
||||
android:layout_width="match_parent"
|
||||
android:layout_height="wrap_content"
|
||||
android:layout_margin="16dp"
|
||||
android:text="Selected GGUF model's metadata will show here."
|
||||
style="@style/TextAppearance.MaterialComponents.Body2"
|
||||
android:maxLines="100" />
|
||||
</ScrollView>
|
||||
|
||||
</ScrollView>
|
||||
|
||||
</FrameLayout>
|
||||
<com.google.android.material.divider.MaterialDivider
|
||||
android:layout_width="match_parent"
|
||||
android:layout_height="2dp"
|
||||
android:layout_marginHorizontal="16dp"
|
||||
android:layout_marginVertical="8dp" />
|
||||
|
||||
<androidx.recyclerview.widget.RecyclerView
|
||||
android:id="@+id/messages"
|
||||
android:layout_width="match_parent"
|
||||
android:layout_height="0dp"
|
||||
android:layout_weight="4"
|
||||
android:padding="16dp"
|
||||
android:fadeScrollbars="false"
|
||||
android:scrollbars="vertical"
|
||||
app:reverseLayout="true"
|
||||
tools:listitem="@layout/item_message_assistant"/>
|
||||
|
||||
<LinearLayout
|
||||
android:layout_width="match_parent"
|
||||
android:layout_height="wrap_content"
|
||||
android:orientation="horizontal">
|
||||
android:orientation="horizontal"
|
||||
android:paddingStart="16dp"
|
||||
android:paddingEnd="4dp">
|
||||
|
||||
<EditText
|
||||
android:id="@+id/user_input"
|
||||
@@ -67,7 +69,7 @@
|
||||
style="@style/Widget.Material3.FloatingActionButton.Primary"
|
||||
android:layout_width="wrap_content"
|
||||
android:layout_height="wrap_content"
|
||||
android:layout_margin="8dp"
|
||||
android:layout_margin="12dp"
|
||||
android:src="@drawable/outline_folder_open_24" />
|
||||
|
||||
</LinearLayout>
|
||||
|
||||
@@ -2,7 +2,8 @@
|
||||
<LinearLayout xmlns:android="http://schemas.android.com/apk/res/android"
|
||||
android:layout_width="match_parent"
|
||||
android:layout_height="wrap_content"
|
||||
android:padding="8dp"
|
||||
android:layout_marginHorizontal="16dp"
|
||||
android:layout_marginVertical="8dp"
|
||||
android:gravity="start">
|
||||
|
||||
<TextView
|
||||
|
||||
@@ -2,7 +2,8 @@
|
||||
<LinearLayout xmlns:android="http://schemas.android.com/apk/res/android"
|
||||
android:layout_width="match_parent"
|
||||
android:layout_height="wrap_content"
|
||||
android:padding="8dp"
|
||||
android:layout_marginHorizontal="16dp"
|
||||
android:layout_marginVertical="8dp"
|
||||
android:gravity="end">
|
||||
|
||||
<TextView
|
||||
|
||||
@@ -2,135 +2,22 @@
|
||||
|
||||
import argparse
|
||||
import os
|
||||
import sys
|
||||
import importlib
|
||||
from pathlib import Path
|
||||
|
||||
# Add parent directory to path for imports
|
||||
sys.path.insert(0, os.path.join(os.path.dirname(__file__), '..'))
|
||||
|
||||
from transformers import AutoTokenizer, AutoModelForCausalLM, AutoModelForImageTextToText, AutoConfig
|
||||
import torch
|
||||
import numpy as np
|
||||
|
||||
### If you want to dump RoPE activations, apply this monkey patch to the model
|
||||
### class from Transformers that you are running (replace apertus.modeling_apertus
|
||||
### with the proper package and class for your model
|
||||
### === START ROPE DEBUG ===
|
||||
# from transformers.models.apertus.modeling_apertus import apply_rotary_pos_emb
|
||||
|
||||
# orig_rope = apply_rotary_pos_emb
|
||||
# torch.set_printoptions(threshold=float('inf'))
|
||||
# torch.set_printoptions(precision=6, sci_mode=False)
|
||||
|
||||
# def debug_rope(q, k, cos, sin, position_ids=None, unsqueeze_dim=1):
|
||||
# # log inputs
|
||||
# summarize(q, "RoPE.q_in")
|
||||
# summarize(k, "RoPE.k_in")
|
||||
|
||||
# # call original
|
||||
# q_out, k_out = orig_rope(q, k, cos, sin, position_ids, unsqueeze_dim)
|
||||
|
||||
# # log outputs
|
||||
# summarize(q_out, "RoPE.q_out")
|
||||
# summarize(k_out, "RoPE.k_out")
|
||||
|
||||
# return q_out, k_out
|
||||
|
||||
# # Patch it
|
||||
# import transformers.models.apertus.modeling_apertus as apertus_mod # noqa: E402
|
||||
# apertus_mod.apply_rotary_pos_emb = debug_rope
|
||||
### == END ROPE DEBUG ===
|
||||
|
||||
|
||||
def summarize(tensor: torch.Tensor, name: str, max_seq: int = 3, max_vals: int = 3):
|
||||
"""
|
||||
Print a tensor in llama.cpp debug style.
|
||||
|
||||
Supports:
|
||||
- 2D tensors (seq, hidden)
|
||||
- 3D tensors (batch, seq, hidden)
|
||||
- 4D tensors (batch, seq, heads, dim_per_head) via flattening heads × dim_per_head
|
||||
|
||||
Shows first and last max_vals of each vector per sequence position.
|
||||
"""
|
||||
t = tensor.detach().to(torch.float32).cpu()
|
||||
|
||||
# Determine dimensions
|
||||
if t.ndim == 3:
|
||||
_, s, _ = t.shape
|
||||
elif t.ndim == 2:
|
||||
_, s = 1, t.shape[0]
|
||||
t = t.unsqueeze(0)
|
||||
elif t.ndim == 4:
|
||||
_, s, _, _ = t.shape
|
||||
else:
|
||||
print(f"Skipping tensor due to unsupported dimensions: {t.ndim}")
|
||||
return
|
||||
|
||||
ten_shape = t.shape
|
||||
|
||||
print(f"ggml_debug: {name} = (f32) ... = {{{ten_shape}}}")
|
||||
print(" [")
|
||||
print(" [")
|
||||
|
||||
# Determine indices for first and last sequences
|
||||
first_indices = list(range(min(s, max_seq)))
|
||||
last_indices = list(range(max(0, s - max_seq), s))
|
||||
|
||||
# Check if there's an overlap between first and last indices or if we're at the edge case of s = 2 * max_seq
|
||||
has_overlap = bool(set(first_indices) & set(last_indices)) or (max_seq * 2 == s)
|
||||
|
||||
# Combine indices
|
||||
if has_overlap:
|
||||
# If there's overlap, just use the combined unique indices
|
||||
indices = sorted(list(set(first_indices + last_indices)))
|
||||
separator_index = None
|
||||
else:
|
||||
# If no overlap, we'll add a separator between first and last sequences
|
||||
indices = first_indices + last_indices
|
||||
separator_index = len(first_indices)
|
||||
|
||||
for i, si in enumerate(indices):
|
||||
# Add separator if needed
|
||||
if separator_index is not None and i == separator_index:
|
||||
print(" ...")
|
||||
|
||||
# Extract appropriate slice
|
||||
vec = t[0, si]
|
||||
if vec.ndim == 2: # 4D case: flatten heads × dim_per_head
|
||||
flat = vec.flatten().tolist()
|
||||
else: # 2D or 3D case
|
||||
flat = vec.tolist()
|
||||
|
||||
# First and last slices
|
||||
first = flat[:max_vals]
|
||||
last = flat[-max_vals:] if len(flat) >= max_vals else flat
|
||||
first_str = ", ".join(f"{v:12.4f}" for v in first)
|
||||
last_str = ", ".join(f"{v:12.4f}" for v in last)
|
||||
|
||||
print(f" [{first_str}, ..., {last_str}]")
|
||||
|
||||
print(" ],")
|
||||
print(" ]")
|
||||
print(f" sum = {t.sum().item():.6f}\n")
|
||||
|
||||
|
||||
def debug_hook(name):
|
||||
def fn(_m, input, output):
|
||||
if isinstance(input, torch.Tensor):
|
||||
summarize(input, name + "_in")
|
||||
elif isinstance(input, (tuple, list)) and len(input) > 0 and isinstance(input[0], torch.Tensor):
|
||||
summarize(input[0], name + "_in")
|
||||
if isinstance(output, torch.Tensor):
|
||||
summarize(output, name + "_out")
|
||||
elif isinstance(output, (tuple, list)) and len(output) > 0 and isinstance(output[0], torch.Tensor):
|
||||
summarize(output[0], name + "_out")
|
||||
|
||||
return fn
|
||||
|
||||
|
||||
unreleased_model_name = os.getenv("UNRELEASED_MODEL_NAME")
|
||||
from utils.common import debug_hook
|
||||
|
||||
parser = argparse.ArgumentParser(description="Process model with specified path")
|
||||
parser.add_argument("--model-path", "-m", help="Path to the model")
|
||||
parser.add_argument("--prompt-file", "-f", help="Optional prompt file", required=False)
|
||||
parser.add_argument("--verbose", "-v", action="store_true", help="Enable verbose debug output")
|
||||
args = parser.parse_args()
|
||||
|
||||
model_path = os.environ.get("MODEL_PATH", args.model_path)
|
||||
@@ -139,6 +26,12 @@ if model_path is None:
|
||||
"Model path must be specified either via --model-path argument or MODEL_PATH environment variable"
|
||||
)
|
||||
|
||||
### If you want to dump RoPE activations, uncomment the following lines:
|
||||
### === START ROPE DEBUG ===
|
||||
# from utils.common import setup_rope_debug
|
||||
# setup_rope_debug("transformers.models.apertus.modeling_apertus")
|
||||
### == END ROPE DEBUG ===
|
||||
|
||||
|
||||
print("Loading model and tokenizer using AutoTokenizer:", model_path)
|
||||
tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True)
|
||||
@@ -156,6 +49,7 @@ print("Number of layers: ", config.num_hidden_layers)
|
||||
print("BOS token id: ", config.bos_token_id)
|
||||
print("EOS token id: ", config.eos_token_id)
|
||||
|
||||
unreleased_model_name = os.getenv("UNRELEASED_MODEL_NAME")
|
||||
if unreleased_model_name:
|
||||
model_name_lower = unreleased_model_name.lower()
|
||||
unreleased_module_path = (
|
||||
@@ -184,9 +78,10 @@ else:
|
||||
model_path, device_map="auto", offload_folder="offload", trust_remote_code=True, config=config
|
||||
)
|
||||
|
||||
for name, module in model.named_modules():
|
||||
if len(list(module.children())) == 0: # only leaf modules
|
||||
module.register_forward_hook(debug_hook(name))
|
||||
if args.verbose:
|
||||
for name, module in model.named_modules():
|
||||
if len(list(module.children())) == 0: # only leaf modules
|
||||
module.register_forward_hook(debug_hook(name))
|
||||
|
||||
model_name = os.path.basename(model_path)
|
||||
# Printing the Model class to allow for easier debugging. This can be useful
|
||||
|
||||
@@ -2,6 +2,8 @@
|
||||
|
||||
import os
|
||||
import sys
|
||||
import torch
|
||||
|
||||
|
||||
def get_model_name_from_env_path(env_path_name):
|
||||
model_path = os.getenv(env_path_name)
|
||||
@@ -18,3 +20,131 @@ def get_model_name_from_env_path(env_path_name):
|
||||
name = name[:-5]
|
||||
|
||||
return name
|
||||
|
||||
|
||||
def summarize(tensor: torch.Tensor, name: str, max_seq: int = 3, max_vals: int = 3):
|
||||
"""
|
||||
Print a tensor in llama.cpp debug style.
|
||||
|
||||
Supports:
|
||||
- 2D tensors (seq, hidden)
|
||||
- 3D tensors (batch, seq, hidden)
|
||||
- 4D tensors (batch, seq, heads, dim_per_head) via flattening heads × dim_per_head
|
||||
|
||||
Shows first and last max_vals of each vector per sequence position.
|
||||
"""
|
||||
t = tensor.detach().to(torch.float32).cpu()
|
||||
|
||||
# Determine dimensions
|
||||
if t.ndim == 3:
|
||||
_, s, _ = t.shape
|
||||
elif t.ndim == 2:
|
||||
_, s = 1, t.shape[0]
|
||||
t = t.unsqueeze(0)
|
||||
elif t.ndim == 4:
|
||||
_, s, _, _ = t.shape
|
||||
else:
|
||||
print(f"Skipping tensor due to unsupported dimensions: {t.ndim}")
|
||||
return
|
||||
|
||||
ten_shape = t.shape
|
||||
|
||||
print(f"ggml_debug: {name} = (f32) ... = {{{ten_shape}}}")
|
||||
print(" [")
|
||||
print(" [")
|
||||
|
||||
# Determine indices for first and last sequences
|
||||
first_indices = list(range(min(s, max_seq)))
|
||||
last_indices = list(range(max(0, s - max_seq), s))
|
||||
|
||||
# Check if there's an overlap between first and last indices or if we're at the edge case of s = 2 * max_seq
|
||||
has_overlap = bool(set(first_indices) & set(last_indices)) or (max_seq * 2 == s)
|
||||
|
||||
# Combine indices
|
||||
if has_overlap:
|
||||
# If there's overlap, just use the combined unique indices
|
||||
indices = sorted(list(set(first_indices + last_indices)))
|
||||
separator_index = None
|
||||
else:
|
||||
# If no overlap, we'll add a separator between first and last sequences
|
||||
indices = first_indices + last_indices
|
||||
separator_index = len(first_indices)
|
||||
|
||||
for i, si in enumerate(indices):
|
||||
# Add separator if needed
|
||||
if separator_index is not None and i == separator_index:
|
||||
print(" ...")
|
||||
|
||||
# Extract appropriate slice
|
||||
vec = t[0, si]
|
||||
if vec.ndim == 2: # 4D case: flatten heads × dim_per_head
|
||||
flat = vec.flatten().tolist()
|
||||
else: # 2D or 3D case
|
||||
flat = vec.tolist()
|
||||
|
||||
# First and last slices
|
||||
first = flat[:max_vals]
|
||||
last = flat[-max_vals:] if len(flat) >= max_vals else flat
|
||||
first_str = ", ".join(f"{v:12.4f}" for v in first)
|
||||
last_str = ", ".join(f"{v:12.4f}" for v in last)
|
||||
|
||||
print(f" [{first_str}, ..., {last_str}]")
|
||||
|
||||
print(" ],")
|
||||
print(" ]")
|
||||
print(f" sum = {t.sum().item():.6f}\n")
|
||||
|
||||
|
||||
def debug_hook(name):
|
||||
def fn(_m, input, output):
|
||||
if isinstance(input, torch.Tensor):
|
||||
summarize(input, name + "_in")
|
||||
elif isinstance(input, (tuple, list)) and len(input) > 0 and isinstance(input[0], torch.Tensor):
|
||||
summarize(input[0], name + "_in")
|
||||
if isinstance(output, torch.Tensor):
|
||||
summarize(output, name + "_out")
|
||||
elif isinstance(output, (tuple, list)) and len(output) > 0 and isinstance(output[0], torch.Tensor):
|
||||
summarize(output[0], name + "_out")
|
||||
|
||||
return fn
|
||||
|
||||
|
||||
def setup_rope_debug(model_module_path: str, function_name: str = "apply_rotary_pos_emb"):
|
||||
"""
|
||||
Apply monkey patch to dump RoPE activations for debugging.
|
||||
|
||||
Args:
|
||||
model_module_path: Path to the model module (e.g., "transformers.models.apertus.modeling_apertus")
|
||||
function_name: Name of the RoPE function to patch (default: "apply_rotary_pos_emb")
|
||||
|
||||
Example:
|
||||
from utils.common import setup_rope_debug
|
||||
setup_rope_debug("transformers.models.apertus.modeling_apertus")
|
||||
"""
|
||||
import importlib
|
||||
|
||||
# Import the module and get the original function
|
||||
module = importlib.import_module(model_module_path)
|
||||
orig_rope = getattr(module, function_name)
|
||||
|
||||
# Set torch print options for better debugging
|
||||
torch.set_printoptions(threshold=float('inf'))
|
||||
torch.set_printoptions(precision=6, sci_mode=False)
|
||||
|
||||
def debug_rope(q, k, cos, sin, position_ids=None, unsqueeze_dim=1):
|
||||
# log inputs
|
||||
summarize(q, "RoPE.q_in")
|
||||
summarize(k, "RoPE.k_in")
|
||||
|
||||
# call original
|
||||
q_out, k_out = orig_rope(q, k, cos, sin, position_ids, unsqueeze_dim)
|
||||
|
||||
# log outputs
|
||||
summarize(q_out, "RoPE.q_out")
|
||||
summarize(k_out, "RoPE.k_out")
|
||||
|
||||
return q_out, k_out
|
||||
|
||||
# Patch it
|
||||
setattr(module, function_name, debug_rope)
|
||||
print(f"RoPE debug patching applied to {model_module_path}.{function_name}")
|
||||
|
||||
@@ -254,6 +254,7 @@ set (GGML_OPENCL_TARGET_VERSION "300" CACHE STRING
|
||||
"gmml: OpenCL API version to target")
|
||||
|
||||
option(GGML_HEXAGON "ggml: enable Hexagon backend" OFF)
|
||||
set(GGML_HEXAGON_FP32_QUANTIZE_GROUP_SIZE 128 CACHE STRING "ggml: quantize group size (32, 64, or 128)")
|
||||
|
||||
# toolchain for vulkan-shaders-gen
|
||||
set (GGML_VULKAN_SHADERS_GEN_TOOLCHAIN "" CACHE FILEPATH "ggml: toolchain file for vulkan-shaders-gen")
|
||||
|
||||
@@ -69,6 +69,10 @@
|
||||
#define VECTOR_REGISTERS 16
|
||||
#endif
|
||||
|
||||
#if defined(__riscv_v_intrinsic)
|
||||
#define LMUL 4
|
||||
#endif
|
||||
|
||||
#define MM256_SET_M128I(a, b) _mm256_insertf128_si256(_mm256_castsi128_si256(b), (a), 1)
|
||||
|
||||
namespace {
|
||||
@@ -175,6 +179,46 @@ inline float32x4_t madd(float32x4_t a, float32x4_t b, float32x4_t c) {
|
||||
}
|
||||
#endif
|
||||
|
||||
#if defined(__riscv_zvfh)
|
||||
template <>
|
||||
inline vfloat32m1_t madd(vfloat16mf2_t a, vfloat16mf2_t b, vfloat32m1_t c) {
|
||||
return __riscv_vfwmacc_vv_f32m1(c, a, b, __riscv_vsetvlmax_e32m1());
|
||||
}
|
||||
inline vfloat32m2_t madd(vfloat16m1_t a, vfloat16m1_t b, vfloat32m2_t c) {
|
||||
return __riscv_vfwmacc_vv_f32m2(c, a, b, __riscv_vsetvlmax_e32m2());
|
||||
}
|
||||
inline vfloat32m4_t madd(vfloat16m2_t a, vfloat16m2_t b, vfloat32m4_t c) {
|
||||
return __riscv_vfwmacc_vv_f32m4(c, a, b, __riscv_vsetvlmax_e32m4());
|
||||
}
|
||||
inline vfloat32m8_t madd(vfloat16m4_t a, vfloat16m4_t b, vfloat32m8_t c) {
|
||||
return __riscv_vfwmacc_vv_f32m8(c, a, b, __riscv_vsetvlmax_e32m8());
|
||||
}
|
||||
inline vfloat32m1_t madd(vfloat32m1_t a, vfloat32m1_t b, vfloat32m1_t c) {
|
||||
return __riscv_vfmacc_vv_f32m1(c, a, b, __riscv_vsetvlmax_e32m1());
|
||||
}
|
||||
inline vfloat32m2_t madd(vfloat32m2_t a, vfloat32m2_t b, vfloat32m2_t c) {
|
||||
return __riscv_vfmacc_vv_f32m2(c, a, b, __riscv_vsetvlmax_e32m2());
|
||||
}
|
||||
inline vfloat32m4_t madd(vfloat32m4_t a, vfloat32m4_t b, vfloat32m4_t c) {
|
||||
return __riscv_vfmacc_vv_f32m4(c, a, b, __riscv_vsetvlmax_e32m4());
|
||||
}
|
||||
inline vfloat32m8_t madd(vfloat32m8_t a, vfloat32m8_t b, vfloat32m8_t c) {
|
||||
return __riscv_vfmacc_vv_f32m8(c, a, b, __riscv_vsetvlmax_e32m8());
|
||||
}
|
||||
#endif
|
||||
|
||||
#if defined(__riscv_zvfbfwma)
|
||||
inline vfloat32m1_t madd(vbfloat16mf2_t a, vbfloat16mf2_t b, vfloat32m1_t c) {
|
||||
return __riscv_vfwmaccbf16_vv_f32m1(c, a, b, __riscv_vsetvlmax_e32m1());
|
||||
}
|
||||
inline vfloat32m2_t madd(vbfloat16m1_t a, vbfloat16m1_t b, vfloat32m2_t c) {
|
||||
return __riscv_vfwmaccbf16_vv_f32m2(c, a, b, __riscv_vsetvlmax_e32m2());
|
||||
}
|
||||
inline vfloat32m4_t madd(vbfloat16m2_t a, vbfloat16m2_t b, vfloat32m4_t c) {
|
||||
return __riscv_vfwmaccbf16_vv_f32m4(c, a, b, __riscv_vsetvlmax_e32m4());
|
||||
}
|
||||
#endif
|
||||
|
||||
////////////////////////////////////////////////////////////////////////////////////////////////////
|
||||
// VECTORIZED HORIZONTAL SUM
|
||||
|
||||
@@ -227,6 +271,25 @@ inline float hsum(__m512 x) {
|
||||
}
|
||||
#endif // __AVX512F__
|
||||
|
||||
#if defined(__riscv_zvfh)
|
||||
inline float hsum(vfloat32m1_t x) {
|
||||
return __riscv_vfmv_f_s_f32m1_f32(
|
||||
__riscv_vfredusum_vs_f32m1_f32m1(x, __riscv_vfmv_v_f_f32m1(0, 1), __riscv_vsetvlmax_e32m1()));
|
||||
}
|
||||
inline float hsum(vfloat32m2_t x) {
|
||||
return __riscv_vfmv_f_s_f32m1_f32(
|
||||
__riscv_vfredusum_vs_f32m2_f32m1(x, __riscv_vfmv_v_f_f32m1(0, 1), __riscv_vsetvlmax_e32m2()));
|
||||
}
|
||||
inline float hsum(vfloat32m4_t x) {
|
||||
return __riscv_vfmv_f_s_f32m1_f32(
|
||||
__riscv_vfredusum_vs_f32m4_f32m1(x, __riscv_vfmv_v_f_f32m1(0, 1), __riscv_vsetvlmax_e32m4()));
|
||||
}
|
||||
inline float hsum(vfloat32m8_t x) {
|
||||
return __riscv_vfmv_f_s_f32m1_f32(
|
||||
__riscv_vfredusum_vs_f32m8_f32m1(x, __riscv_vfmv_v_f_f32m1(0, 1), __riscv_vsetvlmax_e32m8()));
|
||||
}
|
||||
#endif
|
||||
|
||||
////////////////////////////////////////////////////////////////////////////////////////////////////
|
||||
// VECTORIZED MEMORY LOADING
|
||||
|
||||
@@ -315,6 +378,88 @@ template <> inline __m256bh load(const float *p) {
|
||||
}
|
||||
#endif
|
||||
|
||||
#if defined(__riscv_zvfh)
|
||||
template <> inline vfloat16mf2_t load(const ggml_fp16_t *p) {
|
||||
return __riscv_vle16_v_f16mf2(reinterpret_cast<const _Float16 *>(p), __riscv_vsetvlmax_e16mf2());
|
||||
}
|
||||
template <> inline vfloat16m1_t load(const ggml_fp16_t *p) {
|
||||
return __riscv_vle16_v_f16m1(reinterpret_cast<const _Float16 *>(p), __riscv_vsetvlmax_e16m1());
|
||||
}
|
||||
template <> inline vfloat16m2_t load(const ggml_fp16_t *p) {
|
||||
return __riscv_vle16_v_f16m2(reinterpret_cast<const _Float16 *>(p), __riscv_vsetvlmax_e16m2());
|
||||
}
|
||||
template <> inline vfloat16m4_t load(const ggml_fp16_t *p) {
|
||||
return __riscv_vle16_v_f16m4(reinterpret_cast<const _Float16 *>(p), __riscv_vsetvlmax_e16m4());
|
||||
}
|
||||
template <> inline vfloat32m1_t load(const float *p) {
|
||||
return __riscv_vle32_v_f32m1(p, __riscv_vsetvlmax_e32m1());
|
||||
}
|
||||
template <> inline vfloat32m2_t load(const float *p) {
|
||||
return __riscv_vle32_v_f32m2(p, __riscv_vsetvlmax_e32m2());
|
||||
}
|
||||
template <> inline vfloat32m4_t load(const float *p) {
|
||||
return __riscv_vle32_v_f32m4(p, __riscv_vsetvlmax_e32m4());
|
||||
}
|
||||
template <> inline vfloat32m8_t load(const float *p) {
|
||||
return __riscv_vle32_v_f32m8(p, __riscv_vsetvlmax_e32m8());
|
||||
}
|
||||
#endif
|
||||
|
||||
#if defined(__riscv_zvfbfwma)
|
||||
template <> inline vbfloat16mf2_t load(const ggml_bf16_t *p) {
|
||||
return __riscv_vle16_v_bf16mf2(reinterpret_cast<const __bf16*>(p), __riscv_vsetvlmax_e16mf2());
|
||||
}
|
||||
template <> inline vbfloat16m1_t load(const ggml_bf16_t *p) {
|
||||
return __riscv_vle16_v_bf16m1(reinterpret_cast<const __bf16*>(p), __riscv_vsetvlmax_e16m1());
|
||||
}
|
||||
template <> inline vbfloat16m2_t load(const ggml_bf16_t *p) {
|
||||
return __riscv_vle16_v_bf16m2(reinterpret_cast<const __bf16*>(p), __riscv_vsetvlmax_e16m2());
|
||||
}
|
||||
#endif
|
||||
|
||||
#if defined(__riscv_zvfh)
|
||||
template <typename T> T set_zero();
|
||||
|
||||
template <> inline vfloat16mf2_t set_zero() {
|
||||
return __riscv_vfmv_v_f_f16mf2(0, __riscv_vsetvlmax_e16mf2());
|
||||
}
|
||||
template <> inline vfloat16m1_t set_zero() {
|
||||
return __riscv_vfmv_v_f_f16m1(0, __riscv_vsetvlmax_e16m1());
|
||||
}
|
||||
template <> inline vfloat16m2_t set_zero() {
|
||||
return __riscv_vfmv_v_f_f16m2(0, __riscv_vsetvlmax_e16m2());
|
||||
}
|
||||
template <> inline vfloat16m4_t set_zero() {
|
||||
return __riscv_vfmv_v_f_f16m4(0, __riscv_vsetvlmax_e16m4());
|
||||
}
|
||||
template <> inline vfloat32m1_t set_zero() {
|
||||
return __riscv_vfmv_v_f_f32m1(0.0f, __riscv_vsetvlmax_e32m1());
|
||||
}
|
||||
template <> inline vfloat32m2_t set_zero() {
|
||||
return __riscv_vfmv_v_f_f32m2(0, __riscv_vsetvlmax_e32m2());
|
||||
}
|
||||
template <> inline vfloat32m4_t set_zero() {
|
||||
return __riscv_vfmv_v_f_f32m4(0, __riscv_vsetvlmax_e32m4());
|
||||
}
|
||||
template <> inline vfloat32m8_t set_zero() {
|
||||
return __riscv_vfmv_v_f_f32m8(0, __riscv_vsetvlmax_e32m8());
|
||||
}
|
||||
#endif
|
||||
|
||||
#if defined(__riscv_v_intrinsic)
|
||||
template <typename T> size_t vlmax() {
|
||||
if constexpr (std::is_same_v<T, vfloat16mf2_t>) { return __riscv_vsetvlmax_e16mf2(); }
|
||||
else if constexpr (std::is_same_v<T, vfloat16m1_t>) { return __riscv_vsetvlmax_e16m1(); }
|
||||
else if constexpr (std::is_same_v<T, vfloat16m2_t>) { return __riscv_vsetvlmax_e16m2(); }
|
||||
else if constexpr (std::is_same_v<T, vfloat16m4_t>) { return __riscv_vsetvlmax_e16m4(); }
|
||||
else if constexpr (std::is_same_v<T, vfloat32m1_t>) { return __riscv_vsetvlmax_e32m1(); }
|
||||
else if constexpr (std::is_same_v<T, vfloat32m2_t>) { return __riscv_vsetvlmax_e32m2(); }
|
||||
else if constexpr (std::is_same_v<T, vfloat32m4_t>) { return __riscv_vsetvlmax_e32m4(); }
|
||||
else if constexpr (std::is_same_v<T, vfloat32m8_t>) { return __riscv_vsetvlmax_e32m8(); }
|
||||
return 0;
|
||||
}
|
||||
#endif
|
||||
|
||||
////////////////////////////////////////////////////////////////////////////////////////////////////
|
||||
// FLOATING POINT MATRIX MULTIPLICATION
|
||||
|
||||
@@ -488,6 +633,573 @@ class tinyBLAS {
|
||||
const int64_t ldc;
|
||||
};
|
||||
|
||||
#if defined(__riscv_v_intrinsic)
|
||||
template <typename D, typename V, typename TA, typename TB, typename TC>
|
||||
class tinyBLAS_RVV {
|
||||
public:
|
||||
tinyBLAS_RVV(const ggml_compute_params * params, int64_t k,
|
||||
const TA *A, int64_t lda,
|
||||
const TB *B, int64_t ldb,
|
||||
TC *C, int64_t ldc)
|
||||
: params(params), A(A), B(B), C(C), k(k), lda(lda), ldb(ldb), ldc(ldc) {
|
||||
}
|
||||
|
||||
bool matmul(int64_t m, int64_t n) {
|
||||
if (k % vlmax<V>() != 0) {
|
||||
return false;
|
||||
}
|
||||
|
||||
#if LMUL == 1
|
||||
if (m % 16 == 0 && (m/16 >= params->nth)) {
|
||||
const int64_t SIZE_N = BLOCK_SIZE<6>(n);
|
||||
mnpack<4, 6, 4>(m, n, SIZE_N, 12);
|
||||
return true;
|
||||
}
|
||||
if (m % 8 == 0 ) {
|
||||
const int64_t SIZE_N = BLOCK_SIZE<6>(n);
|
||||
mnpack<4, 6, 2>(m, n, SIZE_N, 12);
|
||||
return true;
|
||||
}
|
||||
if (m % 4 == 0) {
|
||||
const int64_t SIZE_N = BLOCK_SIZE<6>(n);
|
||||
mnpack<4, 6, 1>(m, n, SIZE_N, 12);
|
||||
return true;
|
||||
}
|
||||
#elif LMUL == 2
|
||||
if (m % 16 == 0 && (m/16 >= params->nth)) {
|
||||
const int64_t SIZE_N = BLOCK_SIZE<3>(n);
|
||||
mnpack<4, 3, 4>(m, n, SIZE_N, 24);
|
||||
return true;
|
||||
}
|
||||
if (m % 8 == 0 ) {
|
||||
const int64_t SIZE_N = BLOCK_SIZE<3>(n);
|
||||
mnpack<4, 3, 2>(m, n, SIZE_N, 24);
|
||||
return true;
|
||||
}
|
||||
if (m % 4 == 0) {
|
||||
const int64_t SIZE_N = BLOCK_SIZE<3>(n);
|
||||
mnpack<4, 3, 1>(m, n, SIZE_N, 24);
|
||||
return true;
|
||||
}
|
||||
#else // LMUL = 4
|
||||
if (m % 16 == 0 && (m/16 >= params->nth)) {
|
||||
const int64_t SIZE_N = BLOCK_SIZE<2>(n);
|
||||
mnpack<2, 2, 8>(m, n, SIZE_N, 36);
|
||||
return true;
|
||||
}
|
||||
if (m % 8 == 0 ) {
|
||||
const int64_t SIZE_N = BLOCK_SIZE<2>(n);
|
||||
mnpack<2, 2, 4>(m, n, SIZE_N, 36);
|
||||
return true;
|
||||
}
|
||||
if (m % 4 == 0) {
|
||||
const int64_t SIZE_N = BLOCK_SIZE<2>(n);
|
||||
mnpack<2, 2, 2>(m, n, SIZE_N, 36);
|
||||
return true;
|
||||
}
|
||||
#endif
|
||||
return false;
|
||||
}
|
||||
|
||||
private:
|
||||
template<int RM, int RN, int BM>
|
||||
inline void mnpack(int64_t m, int64_t n, int64_t SIZE_N, int64_t BN) {
|
||||
if (SIZE_N == RN) {
|
||||
return gemm<RM, RN, BM>(m, n, BN);
|
||||
}
|
||||
if constexpr (RN > 1) {
|
||||
return mnpack<RM, RN-1, BM>(m, n, SIZE_N, BN);
|
||||
} else {
|
||||
GGML_LOG_ERROR("mnpack<%d, %d> bloc size not supported\n", RM, (int)SIZE_N);
|
||||
GGML_ASSERT(false); // we have miss something.
|
||||
}
|
||||
}
|
||||
|
||||
inline void gemm_bloc_4x6(int64_t ii, int64_t jj) {
|
||||
size_t vl = vlmax<V>();
|
||||
D Cv00 = set_zero<D>();
|
||||
D Cv01 = set_zero<D>();
|
||||
D Cv02 = set_zero<D>();
|
||||
D Cv03 = set_zero<D>();
|
||||
D Cv10 = set_zero<D>();
|
||||
D Cv11 = set_zero<D>();
|
||||
D Cv12 = set_zero<D>();
|
||||
D Cv13 = set_zero<D>();
|
||||
D Cv20 = set_zero<D>();
|
||||
D Cv21 = set_zero<D>();
|
||||
D Cv22 = set_zero<D>();
|
||||
D Cv23 = set_zero<D>();
|
||||
D Cv30 = set_zero<D>();
|
||||
D Cv31 = set_zero<D>();
|
||||
D Cv32 = set_zero<D>();
|
||||
D Cv33 = set_zero<D>();
|
||||
D Cv40 = set_zero<D>();
|
||||
D Cv41 = set_zero<D>();
|
||||
D Cv42 = set_zero<D>();
|
||||
D Cv43 = set_zero<D>();
|
||||
D Cv50 = set_zero<D>();
|
||||
D Cv51 = set_zero<D>();
|
||||
D Cv52 = set_zero<D>();
|
||||
D Cv53 = set_zero<D>();
|
||||
|
||||
for (int64_t l = 0; l < k; l += vl) {
|
||||
V Bv0 = load<V>(B + ldb * (jj + 0) + l);
|
||||
V Bv1 = load<V>(B + ldb * (jj + 1) + l);
|
||||
V Bv2 = load<V>(B + ldb * (jj + 2) + l);
|
||||
V Bv3 = load<V>(B + ldb * (jj + 3) + l);
|
||||
V Bv4 = load<V>(B + ldb * (jj + 4) + l);
|
||||
V Bv5 = load<V>(B + ldb * (jj + 5) + l);
|
||||
|
||||
V Av0 = load<V>(A + lda * (ii + 0) + l);
|
||||
Cv00 = madd(Av0, Bv0, Cv00);
|
||||
Cv10 = madd(Av0, Bv1, Cv10);
|
||||
Cv20 = madd(Av0, Bv2, Cv20);
|
||||
Cv30 = madd(Av0, Bv3, Cv30);
|
||||
Cv40 = madd(Av0, Bv4, Cv40);
|
||||
Cv50 = madd(Av0, Bv5, Cv50);
|
||||
|
||||
V Av1 = load<V>(A + lda * (ii + 1) + l);
|
||||
Cv01 = madd(Av1, Bv0, Cv01);
|
||||
Cv11 = madd(Av1, Bv1, Cv11);
|
||||
Cv21 = madd(Av1, Bv2, Cv21);
|
||||
Cv31 = madd(Av1, Bv3, Cv31);
|
||||
Cv41 = madd(Av1, Bv4, Cv41);
|
||||
Cv51 = madd(Av1, Bv5, Cv51);
|
||||
|
||||
V Av2 = load<V>(A + lda * (ii + 2) + l);
|
||||
Cv02 = madd(Av2, Bv0, Cv02);
|
||||
Cv12 = madd(Av2, Bv1, Cv12);
|
||||
Cv22 = madd(Av2, Bv2, Cv22);
|
||||
Cv32 = madd(Av2, Bv3, Cv32);
|
||||
Cv42 = madd(Av2, Bv4, Cv42);
|
||||
Cv52 = madd(Av2, Bv5, Cv52);
|
||||
|
||||
V Av3 = load<V>(A + lda * (ii + 3) + l);
|
||||
Cv03 = madd(Av3, Bv0, Cv03);
|
||||
Cv13 = madd(Av3, Bv1, Cv13);
|
||||
Cv23 = madd(Av3, Bv2, Cv23);
|
||||
Cv33 = madd(Av3, Bv3, Cv33);
|
||||
Cv43 = madd(Av3, Bv4, Cv43);
|
||||
Cv53 = madd(Av3, Bv5, Cv53);
|
||||
}
|
||||
|
||||
C[ldc * (jj + 0) + (ii + 0)] = hsum(Cv00);
|
||||
C[ldc * (jj + 0) + (ii + 1)] = hsum(Cv01);
|
||||
C[ldc * (jj + 0) + (ii + 2)] = hsum(Cv02);
|
||||
C[ldc * (jj + 0) + (ii + 3)] = hsum(Cv03);
|
||||
C[ldc * (jj + 1) + (ii + 0)] = hsum(Cv10);
|
||||
C[ldc * (jj + 1) + (ii + 1)] = hsum(Cv11);
|
||||
C[ldc * (jj + 1) + (ii + 2)] = hsum(Cv12);
|
||||
C[ldc * (jj + 1) + (ii + 3)] = hsum(Cv13);
|
||||
C[ldc * (jj + 2) + (ii + 0)] = hsum(Cv20);
|
||||
C[ldc * (jj + 2) + (ii + 1)] = hsum(Cv21);
|
||||
C[ldc * (jj + 2) + (ii + 2)] = hsum(Cv22);
|
||||
C[ldc * (jj + 2) + (ii + 3)] = hsum(Cv23);
|
||||
C[ldc * (jj + 3) + (ii + 0)] = hsum(Cv30);
|
||||
C[ldc * (jj + 3) + (ii + 1)] = hsum(Cv31);
|
||||
C[ldc * (jj + 3) + (ii + 2)] = hsum(Cv32);
|
||||
C[ldc * (jj + 3) + (ii + 3)] = hsum(Cv33);
|
||||
C[ldc * (jj + 4) + (ii + 0)] = hsum(Cv40);
|
||||
C[ldc * (jj + 4) + (ii + 1)] = hsum(Cv41);
|
||||
C[ldc * (jj + 4) + (ii + 2)] = hsum(Cv42);
|
||||
C[ldc * (jj + 4) + (ii + 3)] = hsum(Cv43);
|
||||
C[ldc * (jj + 5) + (ii + 0)] = hsum(Cv50);
|
||||
C[ldc * (jj + 5) + (ii + 1)] = hsum(Cv51);
|
||||
C[ldc * (jj + 5) + (ii + 2)] = hsum(Cv52);
|
||||
C[ldc * (jj + 5) + (ii + 3)] = hsum(Cv53);
|
||||
}
|
||||
|
||||
inline void gemm_bloc_4x5(int64_t ii, int64_t jj) {
|
||||
size_t vl = vlmax<V>();
|
||||
D Cv00 = set_zero<D>();
|
||||
D Cv01 = set_zero<D>();
|
||||
D Cv02 = set_zero<D>();
|
||||
D Cv03 = set_zero<D>();
|
||||
D Cv10 = set_zero<D>();
|
||||
D Cv11 = set_zero<D>();
|
||||
D Cv12 = set_zero<D>();
|
||||
D Cv13 = set_zero<D>();
|
||||
D Cv20 = set_zero<D>();
|
||||
D Cv21 = set_zero<D>();
|
||||
D Cv22 = set_zero<D>();
|
||||
D Cv23 = set_zero<D>();
|
||||
D Cv30 = set_zero<D>();
|
||||
D Cv31 = set_zero<D>();
|
||||
D Cv32 = set_zero<D>();
|
||||
D Cv33 = set_zero<D>();
|
||||
D Cv40 = set_zero<D>();
|
||||
D Cv41 = set_zero<D>();
|
||||
D Cv42 = set_zero<D>();
|
||||
D Cv43 = set_zero<D>();
|
||||
|
||||
for (int64_t l = 0; l < k; l += vl) {
|
||||
V Bv0 = load<V>(B + ldb * (jj + 0) + l);
|
||||
V Bv1 = load<V>(B + ldb * (jj + 1) + l);
|
||||
V Bv2 = load<V>(B + ldb * (jj + 2) + l);
|
||||
V Bv3 = load<V>(B + ldb * (jj + 3) + l);
|
||||
V Bv4 = load<V>(B + ldb * (jj + 4) + l);
|
||||
|
||||
V Av0 = load<V>(A + lda * (ii + 0) + l);
|
||||
Cv00 = madd(Av0, Bv0, Cv00);
|
||||
Cv10 = madd(Av0, Bv1, Cv10);
|
||||
Cv20 = madd(Av0, Bv2, Cv20);
|
||||
Cv30 = madd(Av0, Bv3, Cv30);
|
||||
Cv40 = madd(Av0, Bv4, Cv40);
|
||||
|
||||
V Av1 = load<V>(A + lda * (ii + 1) + l);
|
||||
Cv01 = madd(Av1, Bv0, Cv01);
|
||||
Cv11 = madd(Av1, Bv1, Cv11);
|
||||
Cv21 = madd(Av1, Bv2, Cv21);
|
||||
Cv31 = madd(Av1, Bv3, Cv31);
|
||||
Cv41 = madd(Av1, Bv4, Cv41);
|
||||
|
||||
V Av2 = load<V>(A + lda * (ii + 2) + l);
|
||||
Cv02 = madd(Av2, Bv0, Cv02);
|
||||
Cv12 = madd(Av2, Bv1, Cv12);
|
||||
Cv22 = madd(Av2, Bv2, Cv22);
|
||||
Cv32 = madd(Av2, Bv3, Cv32);
|
||||
Cv42 = madd(Av2, Bv4, Cv42);
|
||||
|
||||
V Av3 = load<V>(A + lda * (ii + 3) + l);
|
||||
Cv03 = madd(Av3, Bv0, Cv03);
|
||||
Cv13 = madd(Av3, Bv1, Cv13);
|
||||
Cv23 = madd(Av3, Bv2, Cv23);
|
||||
Cv33 = madd(Av3, Bv3, Cv33);
|
||||
Cv43 = madd(Av3, Bv4, Cv43);
|
||||
}
|
||||
|
||||
C[ldc * (jj + 0) + (ii + 0)] = hsum(Cv00);
|
||||
C[ldc * (jj + 0) + (ii + 1)] = hsum(Cv01);
|
||||
C[ldc * (jj + 0) + (ii + 2)] = hsum(Cv02);
|
||||
C[ldc * (jj + 0) + (ii + 3)] = hsum(Cv03);
|
||||
C[ldc * (jj + 1) + (ii + 0)] = hsum(Cv10);
|
||||
C[ldc * (jj + 1) + (ii + 1)] = hsum(Cv11);
|
||||
C[ldc * (jj + 1) + (ii + 2)] = hsum(Cv12);
|
||||
C[ldc * (jj + 1) + (ii + 3)] = hsum(Cv13);
|
||||
C[ldc * (jj + 2) + (ii + 0)] = hsum(Cv20);
|
||||
C[ldc * (jj + 2) + (ii + 1)] = hsum(Cv21);
|
||||
C[ldc * (jj + 2) + (ii + 2)] = hsum(Cv22);
|
||||
C[ldc * (jj + 2) + (ii + 3)] = hsum(Cv23);
|
||||
C[ldc * (jj + 3) + (ii + 0)] = hsum(Cv30);
|
||||
C[ldc * (jj + 3) + (ii + 1)] = hsum(Cv31);
|
||||
C[ldc * (jj + 3) + (ii + 2)] = hsum(Cv32);
|
||||
C[ldc * (jj + 3) + (ii + 3)] = hsum(Cv33);
|
||||
C[ldc * (jj + 4) + (ii + 0)] = hsum(Cv40);
|
||||
C[ldc * (jj + 4) + (ii + 1)] = hsum(Cv41);
|
||||
C[ldc * (jj + 4) + (ii + 2)] = hsum(Cv42);
|
||||
C[ldc * (jj + 4) + (ii + 3)] = hsum(Cv43);
|
||||
}
|
||||
|
||||
inline void gemm_bloc_4x4(int64_t ii, int64_t jj) {
|
||||
size_t vl = vlmax<V>();
|
||||
D Cv00 = set_zero<D>();
|
||||
D Cv01 = set_zero<D>();
|
||||
D Cv02 = set_zero<D>();
|
||||
D Cv03 = set_zero<D>();
|
||||
D Cv10 = set_zero<D>();
|
||||
D Cv11 = set_zero<D>();
|
||||
D Cv12 = set_zero<D>();
|
||||
D Cv13 = set_zero<D>();
|
||||
D Cv20 = set_zero<D>();
|
||||
D Cv21 = set_zero<D>();
|
||||
D Cv22 = set_zero<D>();
|
||||
D Cv23 = set_zero<D>();
|
||||
D Cv30 = set_zero<D>();
|
||||
D Cv31 = set_zero<D>();
|
||||
D Cv32 = set_zero<D>();
|
||||
D Cv33 = set_zero<D>();
|
||||
|
||||
for (int64_t l = 0; l < k; l += vl) {
|
||||
V Av0 = load<V>(A + lda * (ii + 0) + l);
|
||||
V Av1 = load<V>(A + lda * (ii + 1) + l);
|
||||
V Av2 = load<V>(A + lda * (ii + 2) + l);
|
||||
V Av3 = load<V>(A + lda * (ii + 3) + l);
|
||||
|
||||
V Bv0 = load<V>(B + ldb * (jj + 0) + l);
|
||||
Cv00 = madd(Av0, Bv0, Cv00);
|
||||
Cv01 = madd(Av1, Bv0, Cv01);
|
||||
Cv02 = madd(Av2, Bv0, Cv02);
|
||||
Cv03 = madd(Av3, Bv0, Cv03);
|
||||
|
||||
V Bv1 = load<V>(B + ldb * (jj + 1) + l);
|
||||
Cv10 = madd(Av0, Bv1, Cv10);
|
||||
Cv11 = madd(Av1, Bv1, Cv11);
|
||||
Cv12 = madd(Av2, Bv1, Cv12);
|
||||
Cv13 = madd(Av3, Bv1, Cv13);
|
||||
|
||||
V Bv2 = load<V>(B + ldb * (jj + 2) + l);
|
||||
Cv20 = madd(Av0, Bv2, Cv20);
|
||||
Cv21 = madd(Av1, Bv2, Cv21);
|
||||
Cv22 = madd(Av2, Bv2, Cv22);
|
||||
Cv23 = madd(Av3, Bv2, Cv23);
|
||||
|
||||
V Bv3 = load<V>(B + ldb * (jj + 3) + l);
|
||||
Cv30 = madd(Av0, Bv3, Cv30);
|
||||
Cv31 = madd(Av1, Bv3, Cv31);
|
||||
Cv32 = madd(Av2, Bv3, Cv32);
|
||||
Cv33 = madd(Av3, Bv3, Cv33);
|
||||
}
|
||||
|
||||
C[ldc * (jj + 0) + (ii + 0)] = hsum(Cv00);
|
||||
C[ldc * (jj + 0) + (ii + 1)] = hsum(Cv01);
|
||||
C[ldc * (jj + 0) + (ii + 2)] = hsum(Cv02);
|
||||
C[ldc * (jj + 0) + (ii + 3)] = hsum(Cv03);
|
||||
C[ldc * (jj + 1) + (ii + 0)] = hsum(Cv10);
|
||||
C[ldc * (jj + 1) + (ii + 1)] = hsum(Cv11);
|
||||
C[ldc * (jj + 1) + (ii + 2)] = hsum(Cv12);
|
||||
C[ldc * (jj + 1) + (ii + 3)] = hsum(Cv13);
|
||||
C[ldc * (jj + 2) + (ii + 0)] = hsum(Cv20);
|
||||
C[ldc * (jj + 2) + (ii + 1)] = hsum(Cv21);
|
||||
C[ldc * (jj + 2) + (ii + 2)] = hsum(Cv22);
|
||||
C[ldc * (jj + 2) + (ii + 3)] = hsum(Cv23);
|
||||
C[ldc * (jj + 3) + (ii + 0)] = hsum(Cv30);
|
||||
C[ldc * (jj + 3) + (ii + 1)] = hsum(Cv31);
|
||||
C[ldc * (jj + 3) + (ii + 2)] = hsum(Cv32);
|
||||
C[ldc * (jj + 3) + (ii + 3)] = hsum(Cv33);
|
||||
}
|
||||
|
||||
inline void gemm_bloc_4x3(int64_t ii, int64_t jj) {
|
||||
size_t vl = vlmax<V>();
|
||||
D Cv00 = set_zero<D>();
|
||||
D Cv01 = set_zero<D>();
|
||||
D Cv02 = set_zero<D>();
|
||||
D Cv03 = set_zero<D>();
|
||||
D Cv10 = set_zero<D>();
|
||||
D Cv11 = set_zero<D>();
|
||||
D Cv12 = set_zero<D>();
|
||||
D Cv13 = set_zero<D>();
|
||||
D Cv20 = set_zero<D>();
|
||||
D Cv21 = set_zero<D>();
|
||||
D Cv22 = set_zero<D>();
|
||||
D Cv23 = set_zero<D>();
|
||||
|
||||
for (int64_t l = 0; l < k; l += vl) {
|
||||
V Av0 = load<V>(A + lda * (ii + 0) + l);
|
||||
V Av1 = load<V>(A + lda * (ii + 1) + l);
|
||||
V Av2 = load<V>(A + lda * (ii + 2) + l);
|
||||
V Av3 = load<V>(A + lda * (ii + 3) + l);
|
||||
|
||||
V Bv0 = load<V>(B + ldb * (jj + 0) + l);
|
||||
Cv00 = madd(Av0, Bv0, Cv00);
|
||||
Cv01 = madd(Av1, Bv0, Cv01);
|
||||
Cv02 = madd(Av2, Bv0, Cv02);
|
||||
Cv03 = madd(Av3, Bv0, Cv03);
|
||||
|
||||
V Bv1 = load<V>(B + ldb * (jj + 1) + l);
|
||||
Cv10 = madd(Av0, Bv1, Cv10);
|
||||
Cv11 = madd(Av1, Bv1, Cv11);
|
||||
Cv12 = madd(Av2, Bv1, Cv12);
|
||||
Cv13 = madd(Av3, Bv1, Cv13);
|
||||
|
||||
V Bv2 = load<V>(B + ldb * (jj + 2) + l);
|
||||
Cv20 = madd(Av0, Bv2, Cv20);
|
||||
Cv21 = madd(Av1, Bv2, Cv21);
|
||||
Cv22 = madd(Av2, Bv2, Cv22);
|
||||
Cv23 = madd(Av3, Bv2, Cv23);
|
||||
}
|
||||
|
||||
C[ldc * (jj + 0) + (ii + 0)] = hsum(Cv00);
|
||||
C[ldc * (jj + 0) + (ii + 1)] = hsum(Cv01);
|
||||
C[ldc * (jj + 0) + (ii + 2)] = hsum(Cv02);
|
||||
C[ldc * (jj + 0) + (ii + 3)] = hsum(Cv03);
|
||||
C[ldc * (jj + 1) + (ii + 0)] = hsum(Cv10);
|
||||
C[ldc * (jj + 1) + (ii + 1)] = hsum(Cv11);
|
||||
C[ldc * (jj + 1) + (ii + 2)] = hsum(Cv12);
|
||||
C[ldc * (jj + 1) + (ii + 3)] = hsum(Cv13);
|
||||
C[ldc * (jj + 2) + (ii + 0)] = hsum(Cv20);
|
||||
C[ldc * (jj + 2) + (ii + 1)] = hsum(Cv21);
|
||||
C[ldc * (jj + 2) + (ii + 2)] = hsum(Cv22);
|
||||
C[ldc * (jj + 2) + (ii + 3)] = hsum(Cv23);
|
||||
}
|
||||
|
||||
inline void gemm_bloc_4x2(int64_t ii, int64_t jj) {
|
||||
size_t vl = vlmax<V>();
|
||||
D Cv00 = set_zero<D>();
|
||||
D Cv01 = set_zero<D>();
|
||||
D Cv02 = set_zero<D>();
|
||||
D Cv03 = set_zero<D>();
|
||||
D Cv10 = set_zero<D>();
|
||||
D Cv11 = set_zero<D>();
|
||||
D Cv12 = set_zero<D>();
|
||||
D Cv13 = set_zero<D>();
|
||||
|
||||
for (int64_t l = 0; l < k; l += vl) {
|
||||
V Av0 = load<V>(A + lda * (ii + 0) + l);
|
||||
V Av1 = load<V>(A + lda * (ii + 1) + l);
|
||||
V Av2 = load<V>(A + lda * (ii + 2) + l);
|
||||
V Av3 = load<V>(A + lda * (ii + 3) + l);
|
||||
|
||||
V Bv0 = load<V>(B + ldb * (jj + 0) + l);
|
||||
Cv00 = madd(Av0, Bv0, Cv00);
|
||||
Cv01 = madd(Av1, Bv0, Cv01);
|
||||
Cv02 = madd(Av2, Bv0, Cv02);
|
||||
Cv03 = madd(Av3, Bv0, Cv03);
|
||||
|
||||
V Bv1 = load<V>(B + ldb * (jj + 1) + l);
|
||||
Cv10 = madd(Av0, Bv1, Cv10);
|
||||
Cv11 = madd(Av1, Bv1, Cv11);
|
||||
Cv12 = madd(Av2, Bv1, Cv12);
|
||||
Cv13 = madd(Av3, Bv1, Cv13);
|
||||
}
|
||||
|
||||
C[ldc * (jj + 0) + (ii + 0)] = hsum(Cv00);
|
||||
C[ldc * (jj + 0) + (ii + 1)] = hsum(Cv01);
|
||||
C[ldc * (jj + 0) + (ii + 2)] = hsum(Cv02);
|
||||
C[ldc * (jj + 0) + (ii + 3)] = hsum(Cv03);
|
||||
C[ldc * (jj + 1) + (ii + 0)] = hsum(Cv10);
|
||||
C[ldc * (jj + 1) + (ii + 1)] = hsum(Cv11);
|
||||
C[ldc * (jj + 1) + (ii + 2)] = hsum(Cv12);
|
||||
C[ldc * (jj + 1) + (ii + 3)] = hsum(Cv13);
|
||||
}
|
||||
|
||||
inline void gemm_bloc_4x1(int64_t ii, int64_t jj) {
|
||||
size_t vl = vlmax<V>();
|
||||
D Cv00 = set_zero<D>();
|
||||
D Cv01 = set_zero<D>();
|
||||
D Cv02 = set_zero<D>();
|
||||
D Cv03 = set_zero<D>();
|
||||
|
||||
for (int64_t l = 0; l < k; l += vl) {
|
||||
V Av0 = load<V>(A + lda * (ii + 0) + l);
|
||||
V Av1 = load<V>(A + lda * (ii + 1) + l);
|
||||
V Av2 = load<V>(A + lda * (ii + 2) + l);
|
||||
V Av3 = load<V>(A + lda * (ii + 3) + l);
|
||||
|
||||
V Bv0 = load<V>(B + ldb * (jj + 0) + l);
|
||||
Cv00 = madd(Av0, Bv0, Cv00);
|
||||
Cv01 = madd(Av1, Bv0, Cv01);
|
||||
Cv02 = madd(Av2, Bv0, Cv02);
|
||||
Cv03 = madd(Av3, Bv0, Cv03);
|
||||
}
|
||||
|
||||
C[ldc * (jj + 0) + (ii + 0)] = hsum(Cv00);
|
||||
C[ldc * (jj + 0) + (ii + 1)] = hsum(Cv01);
|
||||
C[ldc * (jj + 0) + (ii + 2)] = hsum(Cv02);
|
||||
C[ldc * (jj + 0) + (ii + 3)] = hsum(Cv03);
|
||||
}
|
||||
|
||||
inline void gemm_bloc_2x2(int64_t ii, int64_t jj) {
|
||||
size_t vl = vlmax<V>();
|
||||
D Cv00 = set_zero<D>();
|
||||
D Cv01 = set_zero<D>();
|
||||
D Cv10 = set_zero<D>();
|
||||
D Cv11 = set_zero<D>();
|
||||
|
||||
for (int64_t l = 0; l < k; l += vl) {
|
||||
V Av0 = load<V>(A + lda * (ii + 0) + l);
|
||||
V Av1 = load<V>(A + lda * (ii + 1) + l);
|
||||
|
||||
V Bv0 = load<V>(B + ldb * (jj + 0) + l);
|
||||
Cv00 = madd(Av0, Bv0, Cv00);
|
||||
Cv01 = madd(Av1, Bv0, Cv01);
|
||||
|
||||
V Bv1 = load<V>(B + ldb * (jj + 1) + l);
|
||||
Cv10 = madd(Av0, Bv1, Cv10);
|
||||
Cv11 = madd(Av1, Bv1, Cv11);
|
||||
}
|
||||
|
||||
C[ldc * (jj + 0) + (ii + 0)] = hsum(Cv00);
|
||||
C[ldc * (jj + 0) + (ii + 1)] = hsum(Cv01);
|
||||
C[ldc * (jj + 1) + (ii + 0)] = hsum(Cv10);
|
||||
C[ldc * (jj + 1) + (ii + 1)] = hsum(Cv11);
|
||||
}
|
||||
|
||||
inline void gemm_bloc_2x1(int64_t ii, int64_t jj) {
|
||||
size_t vl = vlmax<V>();
|
||||
D Cv00 = set_zero<D>();
|
||||
D Cv01 = set_zero<D>();
|
||||
|
||||
for (int64_t l = 0; l < k; l += vl) {
|
||||
V Av0 = load<V>(A + lda * (ii + 0) + l);
|
||||
V Av1 = load<V>(A + lda * (ii + 1) + l);
|
||||
|
||||
V Bv0 = load<V>(B + ldb * (jj + 0) + l);
|
||||
Cv00 = madd(Av0, Bv0, Cv00);
|
||||
Cv01 = madd(Av1, Bv0, Cv01);
|
||||
}
|
||||
|
||||
C[ldc * (jj + 0) + (ii + 0)] = hsum(Cv00);
|
||||
C[ldc * (jj + 0) + (ii + 1)] = hsum(Cv01);
|
||||
}
|
||||
|
||||
template <int RM, int RN>
|
||||
inline void gemm_bloc(int64_t ii, int64_t jj) {
|
||||
if constexpr (RM == 4) {
|
||||
if constexpr (RN == 6) { return gemm_bloc_4x6(ii, jj); }
|
||||
if constexpr (RN == 5) { return gemm_bloc_4x5(ii, jj); }
|
||||
if constexpr (RN == 4) { return gemm_bloc_4x4(ii, jj); }
|
||||
if constexpr (RN == 3) { return gemm_bloc_4x3(ii, jj); }
|
||||
if constexpr (RN == 2) { return gemm_bloc_4x2(ii, jj); }
|
||||
if constexpr (RN == 1) { return gemm_bloc_4x1(ii, jj); }
|
||||
} else if constexpr (RM == 2) {
|
||||
if constexpr (RN == 2) { return gemm_bloc_2x2(ii, jj); }
|
||||
if constexpr (RN == 1) { return gemm_bloc_2x1(ii, jj); }
|
||||
}
|
||||
}
|
||||
|
||||
template <int RM, int RN, int BM>
|
||||
NOINLINE void gemm(int64_t m, int64_t n, int64_t BN) {
|
||||
GGML_ASSERT(m % (RM * BM) == 0);
|
||||
const int64_t ytiles = m / (RM * BM);
|
||||
const int64_t xtiles = (n + RN -1) / RN;
|
||||
const int64_t jj_RN = (xtiles - (xtiles * RN - n));
|
||||
|
||||
// "round" bloc_size to "nearest" BN
|
||||
const int64_t NB_BN = xtiles < BN ? 1 : (xtiles + BN / 2) / BN;
|
||||
const int64_t SIZE_BN = xtiles % NB_BN == 0 ? xtiles / NB_BN : xtiles / NB_BN + 1;
|
||||
const int64_t jj_BN = (NB_BN - (NB_BN * SIZE_BN - xtiles));
|
||||
const int64_t nb_job = ytiles * NB_BN;
|
||||
|
||||
if (params->ith == 0) {
|
||||
GGML_ASSERT( jj_BN * SIZE_BN + (NB_BN - jj_BN) * (SIZE_BN - 1) == xtiles);
|
||||
// Every thread starts at ith, so the first unprocessed chunk is nth. This save a bit of coordination right at the start.
|
||||
ggml_threadpool_chunk_set(params->threadpool, params->nth);
|
||||
}
|
||||
|
||||
ggml_barrier(params->threadpool);
|
||||
|
||||
int64_t job = params->ith;
|
||||
while (job < nb_job) {
|
||||
const int64_t ii = (job % ytiles) * RM * BM;
|
||||
const int64_t jb = job / ytiles;
|
||||
const int64_t jr0 = BLOC_POS(jb , jj_BN, SIZE_BN);
|
||||
const int64_t jrN = BLOC_POS(jb+1, jj_BN, SIZE_BN);
|
||||
|
||||
const int64_t jj0 = BLOC_POS(jr0, jj_RN, RN);
|
||||
const int64_t jj2 = BLOC_POS(jrN, jj_RN, RN);
|
||||
const int64_t jj1 = jj2 < jj_RN * RN ? jj2 : jj_RN * RN;
|
||||
|
||||
for (int64_t bi = 0; bi < BM * RM; bi += RM) {
|
||||
int64_t jj = jj0;
|
||||
for (; jj < jj1; jj += RN) {
|
||||
gemm_bloc<RM, RN>(ii + bi, jj);
|
||||
}
|
||||
if constexpr (RN > 1) {
|
||||
for (; jj < jj2; jj += RN - 1) {
|
||||
gemm_bloc<RM, RN-1>(ii + bi, jj);
|
||||
}
|
||||
}
|
||||
GGML_ASSERT(jj == jj2);
|
||||
}
|
||||
|
||||
job = ggml_threadpool_chunk_add(params->threadpool, 1);
|
||||
}
|
||||
|
||||
ggml_barrier(params->threadpool);
|
||||
return;
|
||||
}
|
||||
|
||||
const ggml_compute_params * params;
|
||||
const TA *const A;
|
||||
const TB *const B;
|
||||
TC *const C;
|
||||
const int64_t k;
|
||||
const int64_t lda;
|
||||
const int64_t ldb;
|
||||
const int64_t ldc;
|
||||
};
|
||||
#endif
|
||||
|
||||
//////////////////////////////////////////////////////////////////////////////////////////
|
||||
// QUANT ZERO MATRIX MULTIPLICATION
|
||||
|
||||
@@ -2657,6 +3369,24 @@ bool llamafile_sgemm(const struct ggml_compute_params * params, int64_t m, int64
|
||||
params->ith, params->nth};
|
||||
tb.matmul(m, n);
|
||||
return true;
|
||||
#elif defined(__riscv_zvfh)
|
||||
#if LMUL == 1
|
||||
tinyBLAS_RVV<vfloat32m1_t, vfloat32m1_t, float, float, float> tb{ params,
|
||||
k, (const float *)A, lda,
|
||||
(const float *)B, ldb,
|
||||
(float *)C, ldc};
|
||||
#elif LMUL == 2
|
||||
tinyBLAS_RVV<vfloat32m2_t, vfloat32m2_t, float, float, float> tb{ params,
|
||||
k, (const float *)A, lda,
|
||||
(const float *)B, ldb,
|
||||
(float *)C, ldc};
|
||||
#else // LMUL = 4
|
||||
tinyBLAS_RVV<vfloat32m4_t, vfloat32m4_t, float, float, float> tb{ params,
|
||||
k, (const float *)A, lda,
|
||||
(const float *)B, ldb,
|
||||
(float *)C, ldc};
|
||||
#endif
|
||||
return tb.matmul(m, n);
|
||||
#else
|
||||
return false;
|
||||
#endif
|
||||
@@ -2699,6 +3429,24 @@ bool llamafile_sgemm(const struct ggml_compute_params * params, int64_t m, int64
|
||||
tb.matmul(m, n);
|
||||
return true;
|
||||
}
|
||||
#elif defined(__riscv_zvfbfwma)
|
||||
#if LMUL == 1
|
||||
tinyBLAS_RVV<vfloat32m1_t, vbfloat16mf2_t, ggml_bf16_t, ggml_bf16_t, float> tb{ params,
|
||||
k, (const ggml_bf16_t *)A, lda,
|
||||
(const ggml_bf16_t *)B, ldb,
|
||||
(float *)C, ldc};
|
||||
#elif LMUL == 2
|
||||
tinyBLAS_RVV<vfloat32m2_t, vbfloat16m1_t, ggml_bf16_t, ggml_bf16_t, float> tb{ params,
|
||||
k, (const ggml_bf16_t *)A, lda,
|
||||
(const ggml_bf16_t *)B, ldb,
|
||||
(float *)C, ldc};
|
||||
#else // LMUL = 4
|
||||
tinyBLAS_RVV<vfloat32m4_t, vbfloat16m2_t, ggml_bf16_t, ggml_bf16_t, float> tb{ params,
|
||||
k, (const ggml_bf16_t *)A, lda,
|
||||
(const ggml_bf16_t *)B, ldb,
|
||||
(float *)C, ldc};
|
||||
#endif
|
||||
return tb.matmul(m, n);
|
||||
#endif
|
||||
return false;
|
||||
}
|
||||
@@ -2748,6 +3496,26 @@ bool llamafile_sgemm(const struct ggml_compute_params * params, int64_t m, int64
|
||||
(float *)C, ldc};
|
||||
return tb.matmul(m, n);
|
||||
}
|
||||
#elif defined(__riscv_zvfh)
|
||||
if (Btype == GGML_TYPE_F16) {
|
||||
#if LMUL == 1
|
||||
tinyBLAS_RVV<vfloat32m1_t, vfloat16mf2_t, ggml_fp16_t, ggml_fp16_t, float> tb{ params,
|
||||
k, (const ggml_fp16_t *)A, lda,
|
||||
(const ggml_fp16_t *)B, ldb,
|
||||
(float *)C, ldc};
|
||||
#elif LMUL == 2
|
||||
tinyBLAS_RVV<vfloat32m2_t, vfloat16m1_t, ggml_fp16_t, ggml_fp16_t, float> tb{ params,
|
||||
k, (const ggml_fp16_t *)A, lda,
|
||||
(const ggml_fp16_t *)B, ldb,
|
||||
(float *)C, ldc};
|
||||
#else // LMUL = 4
|
||||
tinyBLAS_RVV<vfloat32m4_t, vfloat16m2_t, ggml_fp16_t, ggml_fp16_t, float> tb{ params,
|
||||
k, (const ggml_fp16_t *)A, lda,
|
||||
(const ggml_fp16_t *)B, ldb,
|
||||
(float *)C, ldc};
|
||||
#endif
|
||||
return tb.matmul(m, n);
|
||||
}
|
||||
#endif
|
||||
return false;
|
||||
}
|
||||
|
||||
@@ -3076,8 +3076,11 @@ static bool ggml_cuda_can_fuse(const struct ggml_cgraph * cgraph, int node_idx,
|
||||
ggml_can_fuse_subgraph(cgraph, node_idx, ops, { node_idx + 3, node_idx + 9 })) {
|
||||
ggml_tensor * softmax = cgraph->nodes[node_idx];
|
||||
ggml_tensor * weights = cgraph->nodes[node_idx + 9];
|
||||
ggml_tensor * get_rows = cgraph->nodes[node_idx + 4];
|
||||
ggml_tensor * argsort = cgraph->nodes[node_idx + 2];
|
||||
int n_expert = cgraph->nodes[node_idx]->src[0]->ne[0];
|
||||
|
||||
if (ggml_cuda_should_use_topk_moe(softmax, weights)) {
|
||||
if (ggml_cuda_should_use_topk_moe(softmax, weights, get_rows, argsort, nullptr, n_expert)) {
|
||||
return true;
|
||||
}
|
||||
}
|
||||
@@ -3085,7 +3088,11 @@ static bool ggml_cuda_can_fuse(const struct ggml_cgraph * cgraph, int node_idx,
|
||||
if (is_equal(topk_moe_ops, ops) && ggml_can_fuse_subgraph(cgraph, node_idx, ops, { node_idx + 3, node_idx + 4 })) {
|
||||
ggml_tensor * softmax = cgraph->nodes[node_idx];
|
||||
ggml_tensor * weights = cgraph->nodes[node_idx + 4];
|
||||
if (ggml_cuda_should_use_topk_moe(softmax, weights)) {
|
||||
ggml_tensor * get_rows = cgraph->nodes[node_idx + 4];
|
||||
ggml_tensor * argsort = cgraph->nodes[node_idx + 2];
|
||||
int n_expert = cgraph->nodes[node_idx]->src[0]->ne[0];
|
||||
|
||||
if (ggml_cuda_should_use_topk_moe(softmax, weights, get_rows, argsort, nullptr, n_expert)) {
|
||||
return true;
|
||||
}
|
||||
}
|
||||
@@ -3094,8 +3101,11 @@ static bool ggml_cuda_can_fuse(const struct ggml_cgraph * cgraph, int node_idx,
|
||||
ggml_can_fuse_subgraph(cgraph, node_idx, ops, { node_idx + 1, node_idx + 5 })) {
|
||||
ggml_tensor * softmax = cgraph->nodes[node_idx + 4];
|
||||
ggml_tensor * weights = cgraph->nodes[node_idx + 5];
|
||||
ggml_tensor * get_rows = cgraph->nodes[node_idx + 2];
|
||||
ggml_tensor * argsort = cgraph->nodes[node_idx + 0];
|
||||
int n_expert = cgraph->nodes[node_idx]->src[0]->ne[0];
|
||||
|
||||
if (ggml_cuda_should_use_topk_moe(softmax, weights)) {
|
||||
if (ggml_cuda_should_use_topk_moe(softmax, weights, get_rows, argsort, nullptr, n_expert)) {
|
||||
return true;
|
||||
}
|
||||
}
|
||||
|
||||
@@ -63,6 +63,9 @@ void ggml_cuda_op_mean(ggml_backend_cuda_context & ctx, ggml_tensor * dst) {
|
||||
|
||||
const int id = ggml_cuda_get_device();
|
||||
const int nsm = ggml_cuda_info().devices[id].nsm;
|
||||
|
||||
// Heuristic for block size selection to optimize occupancy.
|
||||
// See discussion in: https://github.com/ggml-org/llama.cpp/pull/15132
|
||||
if ((nrows / nsm) < 2) {
|
||||
const dim3 block_dims(512, 1, 1);
|
||||
reduce_rows_f32</*norm=*/true><<<block_nums, block_dims, 0, stream>>>(src0_d, dst_d, ncols);
|
||||
|
||||
@@ -268,7 +268,23 @@ void ggml_cuda_op_topk_moe(ggml_backend_cuda_context & ctx,
|
||||
}
|
||||
}
|
||||
|
||||
bool ggml_cuda_should_use_topk_moe(const ggml_tensor * softmax, const ggml_tensor * weights, const ggml_tensor * clamp) {
|
||||
bool ggml_cuda_should_use_topk_moe(const ggml_tensor * softmax,
|
||||
const ggml_tensor * weights,
|
||||
const ggml_tensor * get_rows,
|
||||
const ggml_tensor * argsort,
|
||||
const ggml_tensor * clamp,
|
||||
int n_expert) {
|
||||
ggml_tensor * probs = get_rows->src[0];
|
||||
if (probs->op != GGML_OP_RESHAPE) {
|
||||
return false;
|
||||
}
|
||||
probs = probs->src[0];
|
||||
ggml_tensor * selection_probs = argsort->src[0];
|
||||
|
||||
if (probs != selection_probs) {
|
||||
return false;
|
||||
}
|
||||
|
||||
float scale = 1.0f;
|
||||
float max_bias = 0.0f;
|
||||
|
||||
@@ -288,7 +304,6 @@ bool ggml_cuda_should_use_topk_moe(const ggml_tensor * softmax, const ggml_tenso
|
||||
return false;
|
||||
}
|
||||
|
||||
const int n_expert = softmax->ne[0];
|
||||
// n_expert must be a power of 2
|
||||
if ((n_expert & (n_expert - 1)) != 0 || n_expert > 512) {
|
||||
return false;
|
||||
|
||||
@@ -11,6 +11,11 @@ void ggml_cuda_op_topk_moe(ggml_backend_cuda_context & ctx,
|
||||
const bool delayed_softmax = false,
|
||||
ggml_tensor * weight_clamp = nullptr);
|
||||
|
||||
bool ggml_cuda_should_use_topk_moe(const ggml_tensor * softmax, const ggml_tensor * weights, const ggml_tensor * clamp = nullptr);
|
||||
bool ggml_cuda_should_use_topk_moe(const ggml_tensor * softmax,
|
||||
const ggml_tensor * weights,
|
||||
const ggml_tensor * get_rows,
|
||||
const ggml_tensor * argsort,
|
||||
const ggml_tensor * clamp,
|
||||
int n_expert);
|
||||
|
||||
std::initializer_list<enum ggml_op> ggml_cuda_topk_moe_ops(bool with_norm, bool delayed_softmax = false);
|
||||
|
||||
@@ -2,6 +2,7 @@ include(${HEXAGON_SDK_ROOT}/build/cmake/hexagon_fun.cmake)
|
||||
include(ExternalProject)
|
||||
|
||||
option(GGML_HEXAGON_HTP_DEBUG "ggml-hexagon: enable HTP debug output" OFF)
|
||||
set(GGML_HEXAGON_FP32_QUANTIZE_GROUP_SIZE 128 CACHE STRING "ggml-hexagon: quantize group size (32, 64, or 128)")
|
||||
|
||||
add_library(htp_iface OBJECT
|
||||
${CMAKE_CURRENT_BINARY_DIR}/htp_iface_stub.c)
|
||||
@@ -41,7 +42,8 @@ set(HTP_CMAKE_ARGS
|
||||
-DCMAKE_INSTALL_LIBDIR=${CMAKE_CURRENT_BINARY_DIR}
|
||||
-DHEXAGON_SDK_ROOT=$ENV{HEXAGON_SDK_ROOT}
|
||||
-DHEXAGON_TOOLS_ROOT=$ENV{HEXAGON_TOOLS_ROOT}
|
||||
-DHEXAGON_HTP_DEBUG=${GGML_HEXAGON_HTP_DEBUG})
|
||||
-DHEXAGON_HTP_DEBUG=${GGML_HEXAGON_HTP_DEBUG}
|
||||
-DGGML_HEXAGON_FP32_QUANTIZE_GROUP_SIZE=${GGML_HEXAGON_FP32_QUANTIZE_GROUP_SIZE})
|
||||
|
||||
ExternalProject_Add(htp-v68
|
||||
SOURCE_DIR ${CMAKE_CURRENT_SOURCE_DIR}/htp BUILD_ALWAYS ON
|
||||
|
||||
@@ -2668,7 +2668,7 @@ static void ggml_hexagon_unary(const struct ggml_tensor * op, uint32_t flags) {
|
||||
req.op = HTP_OP_UNARY_SILU;
|
||||
supported = true;
|
||||
}
|
||||
else if (ggml_get_unary_op(dst) == GGML_UNARY_OP_GELU){
|
||||
else if (ggml_get_unary_op(dst) == GGML_UNARY_OP_GELU) {
|
||||
req.op = HTP_OP_UNARY_GELU;
|
||||
supported = true;
|
||||
}
|
||||
|
||||
@@ -31,7 +31,8 @@ add_library(${HTP_LIB} SHARED
|
||||
)
|
||||
|
||||
target_compile_definitions(${HTP_LIB} PRIVATE
|
||||
$<IF:$<BOOL:${HEXAGON_HTP_DEBUG}>,HTP_DEBUG=1,NDEBUG=1>)
|
||||
$<IF:$<BOOL:${HEXAGON_HTP_DEBUG}>,HTP_DEBUG=1,NDEBUG=1>
|
||||
FP32_QUANTIZE_GROUP_SIZE=${GGML_HEXAGON_FP32_QUANTIZE_GROUP_SIZE})
|
||||
|
||||
build_idl(htp_iface.idl ${HTP_LIB})
|
||||
|
||||
|
||||
@@ -263,7 +263,8 @@ static void unary_gelu_fp32_per_thread(const struct htp_tensor * src0,
|
||||
struct htp_spad * dst_spad,
|
||||
uint32_t nth,
|
||||
uint32_t ith,
|
||||
uint32_t src0_nrows_per_thread) {
|
||||
uint32_t src0_nrows_per_thread,
|
||||
dma_queue * dma_queue) {
|
||||
htp_act_preamble2;
|
||||
|
||||
uint64_t t1, t2;
|
||||
@@ -271,6 +272,8 @@ static void unary_gelu_fp32_per_thread(const struct htp_tensor * src0,
|
||||
|
||||
const size_t src0_row_size = nb01;
|
||||
const size_t dst_row_size = nb1;
|
||||
const size_t src0_row_size_aligned = htp_round_up(src0_row_size, VLEN);
|
||||
const size_t dst_row_size_aligned = htp_round_up(dst_row_size, VLEN);
|
||||
|
||||
const uint32_t src0_nrows = ne01 * ne02 * ne03;
|
||||
|
||||
@@ -282,60 +285,81 @@ static void unary_gelu_fp32_per_thread(const struct htp_tensor * src0,
|
||||
return;
|
||||
}
|
||||
|
||||
int is_aligned = 1;
|
||||
int opt_path = 0;
|
||||
if (!htp_is_aligned((void *) src0->data, VLEN) || !htp_is_aligned((void *) dst->data, VLEN)) {
|
||||
is_aligned = 0;
|
||||
FARF(HIGH, "silu-f32: unaligned addresses in elementwise op, possibly slower execution\n");
|
||||
}
|
||||
if ((1 == is_aligned) && !(nb01 & (VLEN - 1))) {
|
||||
opt_path = 1;
|
||||
const uint8_t * data_src0 = (const uint8_t *) src0->data;
|
||||
uint8_t * data_dst = (uint8_t *) dst->data;
|
||||
|
||||
uint8_t * src0_spad_data = src0_spad->data + (ith * src0_spad->size_per_thread);
|
||||
uint8_t * dst_spad_data = dst_spad->data + (ith * dst_spad->size_per_thread);
|
||||
|
||||
// While given src0_spad->size_per_thread, divide it to two ping-pong buffer for src0
|
||||
size_t src0_spad_half_size = src0_spad->size_per_thread / 2;
|
||||
size_t dst_spad_half_size = dst_spad->size_per_thread / 2;
|
||||
|
||||
// In gelu = x*sigmoid(x*1.702)
|
||||
const int BLOCK = src0_spad_half_size / src0_row_size_aligned; // How many rows can we process in one block
|
||||
|
||||
if (BLOCK == 0) {
|
||||
FARF(ERROR, "gelu-f32 : current VTCM reservation %zu is too small for even 1 row per thread, needed at least %zu\n",
|
||||
src0_spad->size_per_thread, src0_row_size_aligned);
|
||||
return;
|
||||
}
|
||||
|
||||
const uint8_t * restrict data_src0 = (const uint8_t *) src0->data;
|
||||
uint8_t * restrict data_dst = (uint8_t *) dst->data;
|
||||
// See discussion: https://github.com/ggml-org/llama.cpp/pull/18151#issuecomment-3678235379
|
||||
for (uint32_t ir = src0_start_row, spad_idx = 0; ir < src0_end_row && spad_idx < 2; ir += BLOCK, spad_idx++) {
|
||||
const uint32_t block_size = MIN(BLOCK, src0_end_row - ir);
|
||||
|
||||
uint8_t * restrict src0_spad_data = src0_spad->data + (ith * src0_row_size);
|
||||
uint8_t * restrict dst_spad_data = dst_spad->data + (ith * dst_row_size);
|
||||
// Dummy DMA transation for sequencing (interleaving dst,src,dst,...)
|
||||
dma_queue_push_vtcm_to_ddr(dma_queue,
|
||||
dma_make_ptr(data_dst, dst_spad_data + (spad_idx * dst_spad_half_size)),
|
||||
dst_row_size, dst_row_size_aligned, 0);
|
||||
|
||||
dma_queue_push_ddr_to_vtcm(dma_queue,
|
||||
dma_make_ptr(src0_spad_data + (spad_idx * src0_spad_half_size), data_src0 + (ir * src0_row_size)),
|
||||
src0_row_size_aligned, src0_row_size, block_size);
|
||||
}
|
||||
|
||||
const int BLOCK = 8;
|
||||
for (uint32_t ir = src0_start_row; ir < src0_end_row; ir += BLOCK) {
|
||||
const uint32_t block_end = MIN(ir + BLOCK, src0_end_row);
|
||||
const uint32_t block_size = MIN(BLOCK, src0_end_row - ir);
|
||||
|
||||
// Prefetch next block
|
||||
if (block_end < src0_end_row) {
|
||||
const float * restrict prefetch_ptr = (float *) (data_src0 + (block_end * src0_row_size));
|
||||
htp_l2fetch(prefetch_ptr, 1, block_end * src0_row_size, src0_row_size);
|
||||
}
|
||||
float* dst_spad = (float *) dma_queue_pop(dma_queue).src;
|
||||
float* src0_spad = (float *) dma_queue_pop(dma_queue).dst;
|
||||
|
||||
// Process rows in current block
|
||||
for (uint32_t ib = ir; ib < block_end; ib++) {
|
||||
const float * restrict src0 = (float *) (data_src0 + (ib * src0_row_size));
|
||||
float * restrict dst = (float *) (data_dst + (ib * dst_row_size));
|
||||
for (uint32_t ib = 0; ib < block_size; ib++) {
|
||||
const float* src0_spad_ptr = src0_spad + ib * (src0_row_size_aligned / sizeof(float));
|
||||
float* dst_spad_ptr = dst_spad + ib * (dst_row_size_aligned / sizeof(float));
|
||||
|
||||
// gelu = x * sigmoid(1.702 * x) // current implementation
|
||||
if (1 == opt_path) {
|
||||
hvx_mul_scalar_f32((const uint8_t *) src0, (float) 1.702, (uint8_t *) src0_spad_data, ne0);
|
||||
hvx_fast_sigmoid_f32((const uint8_t *) src0_spad_data, (uint8_t *) src0_spad_data, ne0);
|
||||
hvx_mul_f32_opt((const uint8_t *) src0, src0_spad_data, (uint8_t *) dst, ne0);
|
||||
} else {
|
||||
hvx_mul_scalar_f32( (const uint8_t *) src0, (float)1.702, (uint8_t *) src0_spad_data, ne0);
|
||||
hvx_sigmoid_f32((const uint8_t *) src0_spad_data, (uint8_t *) src0_spad_data, ne0);
|
||||
hvx_mul_f32((const uint8_t *) src0, src0_spad_data, (uint8_t *) dst, ne0);
|
||||
}
|
||||
hvx_mul_scalar_f32((const uint8_t *) src0_spad_ptr, (float) 1.702, (uint8_t *) dst_spad_ptr, ne0);
|
||||
hvx_fast_sigmoid_f32((const uint8_t *) dst_spad_ptr, (uint8_t *) dst_spad_ptr, ne0);
|
||||
hvx_mul_f32_opt((const uint8_t *) src0_spad_ptr, (uint8_t *) dst_spad_ptr, (uint8_t *) dst_spad_ptr, ne0);
|
||||
}
|
||||
|
||||
dma_queue_push_vtcm_to_ddr(dma_queue,
|
||||
dma_make_ptr(data_dst + (ir * dst_row_size), dst_spad),
|
||||
dst_row_size, dst_row_size_aligned, block_size);
|
||||
|
||||
// prefetch N+2 loop iteration if any
|
||||
const uint32_t pref_block = (ir + BLOCK * 2);
|
||||
if (pref_block < src0_end_row) {
|
||||
const uint32_t pref_block_size = MIN(BLOCK, src0_end_row - pref_block);
|
||||
dma_queue_push_ddr_to_vtcm(dma_queue,
|
||||
dma_make_ptr(src0_spad, data_src0 + (pref_block * src0_row_size)),
|
||||
src0_row_size_aligned, src0_row_size, pref_block_size);
|
||||
}
|
||||
}
|
||||
|
||||
dma_queue_flush(dma_queue);
|
||||
|
||||
t2 = HAP_perf_get_qtimer_count();
|
||||
|
||||
FARF(HIGH, "gelu-f32 %d/%d/%d: %ux%ux%ux%u (%u:%u) -> %ux%ux%ux%u usec %u\n", ith, nth, opt_path, ne00, ne01, ne02,
|
||||
FARF(HIGH, "gelu-f32 %d/%d: %ux%ux%ux%u (%u:%u) -> %ux%ux%ux%u usec %u\n", ith, nth, ne00, ne01, ne02,
|
||||
ne03, src0_start_row, src0_end_row, ne0, ne1, ne2, ne3, (unsigned) HAP_perf_qtimer_count_to_us(t2 - t1));
|
||||
}
|
||||
|
||||
static void unary_gelu_fp32(unsigned int n, unsigned int i, void * data) {
|
||||
struct htp_ops_context * octx = (struct htp_ops_context *) data;
|
||||
unary_gelu_fp32_per_thread(&octx->src0, &octx->dst, octx->op_params, &octx->src0_spad, &octx->dst_spad, n, i,
|
||||
octx->src0_nrows_per_thread);
|
||||
octx->src0_nrows_per_thread, octx->ctx->dma[i]);
|
||||
}
|
||||
|
||||
|
||||
@@ -468,21 +492,45 @@ static int execute_op_activations_fp32(struct htp_ops_context * octx) {
|
||||
const uint32_t n_threads = octx->n_threads;
|
||||
const uint32_t src0_nrows = src0->ne[1] * src0->ne[2] * src0->ne[3];
|
||||
|
||||
const size_t src0_row_size = src0->nb[1];
|
||||
const size_t src1_row_size = src1->ne[0] ? src1->nb[1] : src0->nb[1];
|
||||
const size_t dst_row_size = dst->nb[1];
|
||||
size_t src0_row_size = src0->nb[1];
|
||||
size_t src1_row_size = src1->nb[1]; // zero bytes if src1 is not used
|
||||
size_t dst_row_size = dst->nb[1];
|
||||
|
||||
const bool src1_valid = src1->ne[0];
|
||||
if (!src1_valid) {
|
||||
src1_row_size = src0_row_size;
|
||||
}
|
||||
|
||||
const size_t src0_row_size_aligned = htp_round_up(src0_row_size, VLEN);
|
||||
const size_t src1_row_size_aligned = htp_round_up(src1_row_size, VLEN);
|
||||
const size_t dst_row_size_aligned = htp_round_up(dst_row_size, VLEN);
|
||||
// VTCM scratchpads for all tensors
|
||||
// N rows per thread, padded to HVX vector size
|
||||
octx->dst_spad.size = htp_round_up(dst_row_size, 128) * octx->n_threads;
|
||||
octx->src0_spad.size = htp_round_up(src0_row_size, 128) * octx->n_threads;
|
||||
octx->src1_spad.size = htp_round_up(src1_row_size, 128) * octx->n_threads;
|
||||
|
||||
size_t spad_size = octx->src0_spad.size + octx->src1_spad.size + octx->dst_spad.size;
|
||||
size_t spad_size_per_row = (src0_row_size_aligned + src1_row_size_aligned) + dst_row_size_aligned;
|
||||
size_t vtcm_row_per_thread = (octx->ctx->vtcm_size)/ (n_threads* spad_size_per_row);
|
||||
|
||||
// Make sure the reserved vtcm size is sufficient
|
||||
if(vtcm_row_per_thread ==0){
|
||||
FARF(ERROR, "act-%s : current VTCM reservation %zu is too small for even 1 row per thread, needed at least %zu\n", op_type, octx->ctx->vtcm_size,
|
||||
spad_size_per_row * n_threads);
|
||||
return HTP_STATUS_VTCM_TOO_SMALL;
|
||||
}
|
||||
|
||||
octx->src0_spad.size_per_thread = src0_row_size_aligned * vtcm_row_per_thread;
|
||||
octx->src1_spad.size_per_thread = src1_row_size_aligned * vtcm_row_per_thread;
|
||||
octx->dst_spad.size_per_thread = dst_row_size_aligned * vtcm_row_per_thread;
|
||||
|
||||
octx->dst_spad.size = n_threads* octx->dst_spad.size_per_thread;
|
||||
octx->src0_spad.size = n_threads* octx->src0_spad.size_per_thread;
|
||||
octx->src1_spad.size = n_threads* octx->src1_spad.size_per_thread;
|
||||
|
||||
octx->src0_spad.data = octx->ctx->vtcm_base;
|
||||
octx->src1_spad.data = octx->src0_spad.data + octx->src0_spad.size;
|
||||
octx->dst_spad.data = octx->src1_spad.data + octx->src1_spad.size;
|
||||
|
||||
if (src1->ne[0]) {
|
||||
FARF(HIGH,
|
||||
"%s: %ux%ux%ux%u x %ux%ux%ux%u -> %ux%ux%ux%u : src0-spad-size %u src1-spad-size %u dst-spad-size %u\n",
|
||||
FARF(HIGH, "%s: %ux%ux%ux%u x %ux%ux%ux%u -> %ux%ux%ux%u : src0-spad-size %u src1-spad-size %u dst-spad-size %u\n",
|
||||
op_type, src0->ne[0], src0->ne[1], src0->ne[2], src0->ne[3], src1->ne[0], src1->ne[1], src1->ne[2],
|
||||
src1->ne[3], dst->ne[0], dst->ne[1], dst->ne[2], dst->ne[3], octx->src0_spad.size, octx->src1_spad.size,
|
||||
octx->dst_spad.size);
|
||||
@@ -492,20 +540,8 @@ static int execute_op_activations_fp32(struct htp_ops_context * octx) {
|
||||
octx->src0_spad.size, octx->src1_spad.size, octx->dst_spad.size);
|
||||
}
|
||||
|
||||
// Make sure the reserved vtcm size is sufficient
|
||||
if (octx->ctx->vtcm_size < spad_size) {
|
||||
FARF(ERROR, "act-%s : current VTCM reservation %zu is too small, needed %zu\n", op_type, octx->ctx->vtcm_size,
|
||||
spad_size);
|
||||
return HTP_STATUS_VTCM_TOO_SMALL;
|
||||
}
|
||||
|
||||
octx->src0_spad.data = octx->ctx->vtcm_base;
|
||||
octx->src1_spad.data = octx->src0_spad.data + octx->src0_spad.size;
|
||||
octx->dst_spad.data = octx->src1_spad.data + octx->src1_spad.size;
|
||||
|
||||
if (!(octx->flags & HTP_OPFLAGS_SKIP_COMPUTE)) {
|
||||
uint32_t n_jobs = MIN(n_threads, src0_nrows);
|
||||
|
||||
octx->src0_nrows_per_thread = (src0_nrows + n_jobs - 1) / n_jobs;
|
||||
worker_pool_run_func(octx->ctx->worker_pool, act_op_func, octx, n_jobs);
|
||||
}
|
||||
|
||||
@@ -34,12 +34,12 @@ dma_queue * dma_queue_create(size_t capacity) {
|
||||
q->desc = (hexagon_udma_descriptor_type1_t *) memalign(64, capacity * sizeof(hexagon_udma_descriptor_type1_t));
|
||||
memset(q->desc, 0, capacity * sizeof(hexagon_udma_descriptor_type1_t));
|
||||
|
||||
q->dst = (void **) memalign(4, capacity * sizeof(void *));
|
||||
memset(q->dst, 0, capacity * sizeof(void *));
|
||||
q->dptr = (dma_ptr *) memalign(4, capacity * sizeof(dma_ptr));
|
||||
memset(q->dptr, 0, capacity * sizeof(dma_ptr));
|
||||
|
||||
q->tail = &q->desc[capacity - 1];
|
||||
|
||||
if (!q->desc && !q->dst) {
|
||||
if (!q->desc && !q->dptr) {
|
||||
FARF(ERROR, "%s: failed to allocate DMA queue items\n", __FUNCTION__);
|
||||
return NULL;
|
||||
}
|
||||
@@ -54,16 +54,10 @@ void dma_queue_delete(dma_queue * q) {
|
||||
return;
|
||||
}
|
||||
free(q->desc);
|
||||
free(q->dst);
|
||||
free(q->dptr);
|
||||
free(q);
|
||||
}
|
||||
|
||||
void dma_queue_flush(dma_queue * q) {
|
||||
while (1) {
|
||||
uint32_t s = dmwait() & 0x3;
|
||||
if (s == HEXAGON_UDMA_DM0_STATUS_IDLE) {
|
||||
break;
|
||||
}
|
||||
}
|
||||
q->tail = NULL;
|
||||
while (dma_queue_pop(q).dst != NULL) ;
|
||||
}
|
||||
|
||||
@@ -11,10 +11,15 @@
|
||||
extern "C" {
|
||||
#endif
|
||||
|
||||
typedef struct {
|
||||
void *dst;
|
||||
const void *src;
|
||||
} dma_ptr;
|
||||
|
||||
typedef struct {
|
||||
hexagon_udma_descriptor_type1_t * desc; // descriptor pointers
|
||||
hexagon_udma_descriptor_type1_t * tail; // tail pointer
|
||||
void ** dst; // dst pointers
|
||||
dma_ptr * dptr; // dst/src pointers
|
||||
uint32_t push_idx;
|
||||
uint32_t pop_idx;
|
||||
uint32_t capacity;
|
||||
@@ -49,13 +54,20 @@ static inline unsigned int dmwait(void) {
|
||||
return ret;
|
||||
}
|
||||
|
||||
static inline bool dma_queue_push(dma_queue * q,
|
||||
void * dst,
|
||||
const void * src,
|
||||
size_t dst_row_size,
|
||||
size_t src_row_size,
|
||||
size_t nrows) {
|
||||
static inline dma_ptr dma_make_ptr(void *dst, const void *src)
|
||||
{
|
||||
dma_ptr p = { dst, src };
|
||||
return p;
|
||||
}
|
||||
|
||||
static inline bool dma_queue_push(dma_queue * q,
|
||||
dma_ptr dptr,
|
||||
size_t dst_row_size,
|
||||
size_t src_row_size,
|
||||
size_t width, // width in bytes. number of bytes to transfer per row
|
||||
size_t nrows) {
|
||||
if (((q->push_idx + 1) & q->idx_mask) == q->pop_idx) {
|
||||
FARF(ERROR, "dma-push: queue full\n");
|
||||
return false;
|
||||
}
|
||||
|
||||
@@ -75,18 +87,18 @@ static inline bool dma_queue_push(dma_queue * q,
|
||||
#endif
|
||||
desc->order = 0;
|
||||
desc->dstate = HEXAGON_UDMA_DESC_DSTATE_INCOMPLETE;
|
||||
desc->src = (void *) src;
|
||||
desc->dst = (void *) dst;
|
||||
desc->src = (void *) dptr.src;
|
||||
desc->dst = (void *) dptr.dst;
|
||||
desc->allocation = 0;
|
||||
desc->padding = 0;
|
||||
desc->roiwidth = src_row_size;
|
||||
desc->roiwidth = width;
|
||||
desc->roiheight = nrows;
|
||||
desc->srcstride = src_row_size;
|
||||
desc->dststride = dst_row_size;
|
||||
desc->srcwidthoffset = 0;
|
||||
desc->dstwidthoffset = 0;
|
||||
|
||||
q->dst[q->push_idx] = dst;
|
||||
q->dptr[q->push_idx] = dptr;
|
||||
|
||||
dmlink(q->tail, desc);
|
||||
q->tail = desc;
|
||||
@@ -96,9 +108,28 @@ static inline bool dma_queue_push(dma_queue * q,
|
||||
return true;
|
||||
}
|
||||
|
||||
static inline uint8_t * dma_queue_pop(dma_queue * q) {
|
||||
static inline bool dma_queue_push_ddr_to_vtcm(dma_queue * q,
|
||||
dma_ptr dptr,
|
||||
size_t dst_row_size,
|
||||
size_t src_row_size,
|
||||
size_t nrows) {
|
||||
return dma_queue_push(q, dptr, dst_row_size, src_row_size, src_row_size, nrows);
|
||||
}
|
||||
|
||||
|
||||
static inline bool dma_queue_push_vtcm_to_ddr(dma_queue * q,
|
||||
dma_ptr dptr,
|
||||
size_t dst_row_size,
|
||||
size_t src_row_size,
|
||||
size_t nrows) {
|
||||
return dma_queue_push(q, dptr, dst_row_size, src_row_size, dst_row_size, nrows);
|
||||
}
|
||||
|
||||
static inline dma_ptr dma_queue_pop(dma_queue * q) {
|
||||
dma_ptr dptr = { NULL };
|
||||
|
||||
if (q->push_idx == q->pop_idx) {
|
||||
return NULL;
|
||||
return dptr;
|
||||
}
|
||||
|
||||
hexagon_udma_descriptor_type1_t * desc = &q->desc[q->pop_idx];
|
||||
@@ -112,11 +143,11 @@ static inline uint8_t * dma_queue_pop(dma_queue * q) {
|
||||
// FARF(ERROR, "dma-pop: waiting for DMA : %u\n", q->pop_idx);
|
||||
}
|
||||
|
||||
uint8_t * dst = (uint8_t *) q->dst[q->pop_idx];
|
||||
dptr = q->dptr[q->pop_idx];
|
||||
|
||||
// FARF(ERROR, "dma-pop: i %u dst %p\n", q->pop_idx, dst);
|
||||
q->pop_idx = (q->pop_idx + 1) & q->idx_mask;
|
||||
return dst;
|
||||
return dptr;
|
||||
}
|
||||
|
||||
#ifdef __cplusplus
|
||||
|
||||
@@ -980,8 +980,6 @@ static inline void hvx_fast_sigmoid_f32(const uint8_t * restrict src, uint8_t *
|
||||
int step_of_1 = num_elems >> 5;
|
||||
int remaining = num_elems - step_of_1 * VLEN_FP32;
|
||||
|
||||
assert(remaining == 0);
|
||||
|
||||
const HVX_Vector * restrict v_src = (HVX_Vector *) src;
|
||||
HVX_Vector * restrict v_dst = (HVX_Vector *) dst;
|
||||
|
||||
@@ -996,8 +994,16 @@ static inline void hvx_fast_sigmoid_f32(const uint8_t * restrict src, uint8_t *
|
||||
for (int i = 0; i < step_of_1; i++) {
|
||||
v_dst[i] = hvx_vec_fast_sigmoid_fp32_guard(v_src[i], one, max_exp, min_exp);
|
||||
}
|
||||
}
|
||||
|
||||
if (remaining > 0) {
|
||||
const float * srcf = ((const float *) src) + step_of_1* VLEN_FP32;
|
||||
float * dstf = (float *) dst + step_of_1*VLEN_FP32;
|
||||
|
||||
HVX_Vector in = *(HVX_UVector *) srcf;
|
||||
HVX_Vector out = hvx_vec_fast_sigmoid_fp32_guard(in, one, max_exp, min_exp);
|
||||
hvx_vec_store_u((void *) dstf, remaining * SIZEOF_FP32, out);
|
||||
}
|
||||
}
|
||||
|
||||
static inline void hvx_sigmoid_f32(const uint8_t * restrict src, uint8_t * restrict dst, const int num_elems){
|
||||
int step_of_1 = num_elems >> 5; // divby 32, because 32 float = 128 bytes per HVX vector
|
||||
|
||||
@@ -299,7 +299,8 @@ AEEResult htp_iface_start(remote_handle64 handle, uint32 sess_id, uint64 dsp_que
|
||||
|
||||
ctx->n_threads = n_hvx;
|
||||
for (int i = 0; i < ctx->n_threads; i++) {
|
||||
ctx->dma[i] = dma_queue_create(HTP_SPAD_SRC0_NROWS * 2);
|
||||
// see discussion https://github.com/ggml-org/llama.cpp/pull/18151#discussion_r2632388541
|
||||
ctx->dma[i] = dma_queue_create(64);
|
||||
}
|
||||
|
||||
// init worker pool
|
||||
|
||||
@@ -92,6 +92,18 @@ static const uint8_t __attribute__((aligned(128))) repl_1x_fp16[128] = {
|
||||
0x02, 0x02, 0x04, 0x04, 0x02, 0x02, 0x08, 0x08, 0x02, 0x02, 0x04, 0x04, 0x02, 0x02,
|
||||
};
|
||||
|
||||
// vdelta control to replicate first fp16 value across all elements
|
||||
static const uint8_t __attribute__((aligned(128))) repl_2x_fp16[128] = {
|
||||
0x00, 0x00, 0x02, 0x02, 0x04, 0x04, 0x02, 0x02, 0x08, 0x08, 0x02, 0x02, 0x04, 0x04, 0x02, 0x02,
|
||||
0x10, 0x10, 0x02, 0x02, 0x04, 0x04, 0x02, 0x02, 0x08, 0x08, 0x02, 0x02, 0x04, 0x04, 0x02, 0x02,
|
||||
0x20, 0x20, 0x02, 0x02, 0x04, 0x04, 0x02, 0x02, 0x08, 0x08, 0x02, 0x02, 0x04, 0x04, 0x02, 0x02,
|
||||
0x10, 0x10, 0x02, 0x02, 0x04, 0x04, 0x02, 0x02, 0x08, 0x08, 0x02, 0x02, 0x04, 0x04, 0x02, 0x02,
|
||||
0x00, 0x00, 0x02, 0x02, 0x04, 0x04, 0x02, 0x02, 0x08, 0x08, 0x02, 0x02, 0x04, 0x04, 0x02, 0x02,
|
||||
0x10, 0x10, 0x02, 0x02, 0x04, 0x04, 0x02, 0x02, 0x08, 0x08, 0x02, 0x02, 0x04, 0x04, 0x02, 0x02,
|
||||
0x20, 0x20, 0x02, 0x02, 0x04, 0x04, 0x02, 0x02, 0x08, 0x08, 0x02, 0x02, 0x04, 0x04, 0x02, 0x02,
|
||||
0x10, 0x10, 0x02, 0x02, 0x04, 0x04, 0x02, 0x02, 0x08, 0x08, 0x02, 0x02, 0x04, 0x04, 0x02, 0x02,
|
||||
};
|
||||
|
||||
// vdelta control to expand first 32 e8m0 values into 32 uint32 elements
|
||||
static const uint8_t __attribute__((aligned(128))) expand_x32_e8m0[128] = {
|
||||
0x00, 0x00, 0x00, 0x00, 0x01, 0x04, 0x00, 0x00, 0x02, 0x00, 0x08, 0x08, 0x01, 0x02, 0x00, 0x04, 0x04, 0x00, 0x00,
|
||||
@@ -1115,13 +1127,13 @@ static void matmul(struct htp_matmul_type * mt,
|
||||
if (is0 >= HTP_SPAD_SRC0_NROWS) {
|
||||
break;
|
||||
}
|
||||
dma_queue_push(dma_queue, spad_src0 + is0 * src0_row_size_padded, src0_row + ir0 * src0_row_size,
|
||||
dma_queue_push_ddr_to_vtcm(dma_queue, dma_make_ptr(spad_src0 + is0 * src0_row_size_padded, src0_row + ir0 * src0_row_size),
|
||||
src0_row_size_padded, src0_row_size, 2);
|
||||
}
|
||||
|
||||
// Process src0 rows
|
||||
for (uint32_t ir0 = src0_start_row; ir0 < src0_end_row_x2; ir0 += 2) {
|
||||
const uint8_t * ss0 = dma_queue_pop(dma_queue);
|
||||
const uint8_t * ss0 = dma_queue_pop(dma_queue).dst;
|
||||
|
||||
#pragma unroll(2)
|
||||
for (uint32_t ir1 = 0; ir1 < src1_nrows; ++ir1) {
|
||||
@@ -1134,7 +1146,7 @@ static void matmul(struct htp_matmul_type * mt,
|
||||
const int pr0 = (ir0 + HTP_SPAD_SRC0_NROWS);
|
||||
const int is0 = (pr0 - src0_start_row) % HTP_SPAD_SRC0_NROWS;
|
||||
if (pr0 < src0_end_row_x2) {
|
||||
dma_queue_push(dma_queue, spad_src0 + is0 * src0_row_size_padded, src0_row + pr0 * src0_row_size,
|
||||
dma_queue_push_ddr_to_vtcm(dma_queue, dma_make_ptr(spad_src0 + is0 * src0_row_size_padded, src0_row + pr0 * src0_row_size),
|
||||
src0_row_size_padded, src0_row_size, 2);
|
||||
}
|
||||
}
|
||||
@@ -1143,9 +1155,9 @@ static void matmul(struct htp_matmul_type * mt,
|
||||
if (src0_end_row != src0_end_row_x2) {
|
||||
uint32_t ir0 = src0_end_row_x2;
|
||||
const int is0 = (ir0 - src0_start_row);
|
||||
dma_queue_push(dma_queue, spad_src0 + is0 * src0_row_size_padded, src0_row + ir0 * src0_row_size,
|
||||
dma_queue_push_ddr_to_vtcm(dma_queue, dma_make_ptr(spad_src0 + is0 * src0_row_size_padded, src0_row + ir0 * src0_row_size),
|
||||
src0_row_size_padded, src0_row_size, 1);
|
||||
const uint8_t * ss0 = dma_queue_pop(dma_queue);
|
||||
const uint8_t * ss0 = dma_queue_pop(dma_queue).dst;
|
||||
|
||||
#pragma unroll(2)
|
||||
for (uint32_t ir1 = 0; ir1 < src1_nrows; ++ir1) {
|
||||
@@ -1217,20 +1229,20 @@ static void matvec(struct htp_matmul_type * mt,
|
||||
if (is0 >= HTP_SPAD_SRC0_NROWS) {
|
||||
break;
|
||||
}
|
||||
dma_queue_push(dma_queue, spad_src0 + is0 * src0_row_size_padded, src0_row + ir0 * src0_row_size,
|
||||
dma_queue_push_ddr_to_vtcm(dma_queue, dma_make_ptr(spad_src0 + is0 * src0_row_size_padded, src0_row + ir0 * src0_row_size),
|
||||
src0_row_size_padded, src0_row_size, 2);
|
||||
}
|
||||
|
||||
// Process src0 rows
|
||||
for (uint32_t ir0 = src0_start_row; ir0 < src0_end_row_x2; ir0 += 2) {
|
||||
const uint8_t * ss0 = dma_queue_pop(dma_queue);
|
||||
const uint8_t * ss0 = dma_queue_pop(dma_queue).dst;
|
||||
mt->vec_dot_rx2(ne00, &tmp[ir0 - src0_start_row], ss0, src0_row_size_padded, src1_col);
|
||||
|
||||
// Prefetch next (n + spad_nrows) row
|
||||
const uint32_t pr0 = (ir0 + HTP_SPAD_SRC0_NROWS);
|
||||
const uint32_t is0 = (pr0 - src0_start_row) % HTP_SPAD_SRC0_NROWS;
|
||||
if (pr0 < src0_end_row_x2) {
|
||||
dma_queue_push(dma_queue, spad_src0 + is0 * src0_row_size_padded, src0_row + pr0 * src0_row_size,
|
||||
dma_queue_push_ddr_to_vtcm(dma_queue, dma_make_ptr(spad_src0 + is0 * src0_row_size_padded, src0_row + pr0 * src0_row_size),
|
||||
src0_row_size_padded, src0_row_size, 2);
|
||||
}
|
||||
}
|
||||
@@ -1239,9 +1251,9 @@ static void matvec(struct htp_matmul_type * mt,
|
||||
if (src0_end_row != src0_end_row_x2) {
|
||||
const uint32_t ir0 = src0_end_row_x2;
|
||||
const uint32_t is0 = (ir0 - src0_start_row);
|
||||
dma_queue_push(dma_queue, spad_src0 + is0 * src0_row_size_padded, src0_row + ir0 * src0_row_size,
|
||||
dma_queue_push_ddr_to_vtcm(dma_queue, dma_make_ptr(spad_src0 + is0 * src0_row_size_padded, src0_row + ir0 * src0_row_size),
|
||||
src0_row_size_padded, src0_row_size, 1);
|
||||
const uint8_t * ss0 = dma_queue_pop(dma_queue);
|
||||
const uint8_t * ss0 = dma_queue_pop(dma_queue).dst;
|
||||
mt->vec_dot(ne00, &tmp[ir0 - src0_start_row], ss0, src1_col);
|
||||
}
|
||||
|
||||
@@ -1331,13 +1343,13 @@ static void matmul_id(struct htp_matmul_type * mt,
|
||||
if (is0 >= HTP_SPAD_SRC0_NROWS) {
|
||||
break;
|
||||
}
|
||||
dma_queue_push(dma_queue, spad_src0 + is0 * src0_row_size_padded, src0_row + ir0 * src0_row_size,
|
||||
dma_queue_push_ddr_to_vtcm(dma_queue, dma_make_ptr(spad_src0 + is0 * src0_row_size_padded, src0_row + ir0 * src0_row_size),
|
||||
src0_row_size_padded, src0_row_size, 2);
|
||||
}
|
||||
|
||||
// Process src0 rows
|
||||
for (uint32_t ir0 = src0_start_row; ir0 < src0_end_row_x2; ir0 += 2) {
|
||||
const uint8_t * ss0 = dma_queue_pop(dma_queue);
|
||||
const uint8_t * ss0 = dma_queue_pop(dma_queue).dst;
|
||||
|
||||
for (uint32_t cid = 0; cid < cne1; ++cid) {
|
||||
struct mmid_row_mapping row_mapping = MMID_MATRIX_ROW(cur_a, cid);
|
||||
@@ -1356,7 +1368,7 @@ static void matmul_id(struct htp_matmul_type * mt,
|
||||
const int pr0 = (ir0 + HTP_SPAD_SRC0_NROWS);
|
||||
const int is0 = (pr0 - src0_start_row) % HTP_SPAD_SRC0_NROWS;
|
||||
if (pr0 < src0_end_row_x2) {
|
||||
dma_queue_push(dma_queue, spad_src0 + is0 * src0_row_size_padded, src0_row + pr0 * src0_row_size,
|
||||
dma_queue_push_ddr_to_vtcm(dma_queue, dma_make_ptr(spad_src0 + is0 * src0_row_size_padded, src0_row + pr0 * src0_row_size),
|
||||
src0_row_size_padded, src0_row_size, 2);
|
||||
}
|
||||
}
|
||||
@@ -1365,9 +1377,9 @@ static void matmul_id(struct htp_matmul_type * mt,
|
||||
if (src0_end_row != src0_end_row_x2) {
|
||||
uint32_t ir0 = src0_end_row_x2;
|
||||
const uint32_t is0 = (ir0 - src0_start_row);
|
||||
dma_queue_push(dma_queue, spad_src0 + is0 * src0_row_size_padded, src0_row + ir0 * src0_row_size,
|
||||
dma_queue_push_ddr_to_vtcm(dma_queue, dma_make_ptr(spad_src0 + is0 * src0_row_size_padded, src0_row + ir0 * src0_row_size),
|
||||
src0_row_size_padded, src0_row_size, 1);
|
||||
const uint8_t * ss0 = dma_queue_pop(dma_queue);
|
||||
const uint8_t * ss0 = dma_queue_pop(dma_queue).dst;
|
||||
|
||||
for (uint32_t cid = 0; cid < cne1; ++cid) {
|
||||
struct mmid_row_mapping row_mapping = MMID_MATRIX_ROW(cur_a, cid);
|
||||
@@ -1455,20 +1467,20 @@ static void matvec_id(struct htp_matmul_type * mt,
|
||||
if (is0 >= HTP_SPAD_SRC0_NROWS) {
|
||||
break;
|
||||
}
|
||||
dma_queue_push(dma_queue, spad_src0 + is0 * src0_row_size_padded, src0_row + ir0 * src0_row_size,
|
||||
dma_queue_push_ddr_to_vtcm(dma_queue, dma_make_ptr(spad_src0 + is0 * src0_row_size_padded, src0_row + ir0 * src0_row_size),
|
||||
src0_row_size_padded, src0_row_size, 2);
|
||||
}
|
||||
|
||||
// Process src0 rows
|
||||
for (uint32_t ir0 = src0_start_row; ir0 < src0_end_row_x2; ir0 += 2) {
|
||||
const uint8_t * ss0 = dma_queue_pop(dma_queue);
|
||||
const uint8_t * ss0 = dma_queue_pop(dma_queue).dst;
|
||||
mt->vec_dot_rx2(ne00, &dst_row[ir0], ss0, src0_row_size_padded, src1_col);
|
||||
|
||||
// Prefetch next (n + spad_nrows) row
|
||||
const int pr0 = (ir0 + HTP_SPAD_SRC0_NROWS);
|
||||
const int is0 = (pr0 - src0_start_row) % HTP_SPAD_SRC0_NROWS;
|
||||
if (pr0 < src0_end_row_x2) {
|
||||
dma_queue_push(dma_queue, spad_src0 + is0 * src0_row_size_padded, src0_row + pr0 * src0_row_size,
|
||||
dma_queue_push_ddr_to_vtcm(dma_queue, dma_make_ptr(spad_src0 + is0 * src0_row_size_padded, src0_row + pr0 * src0_row_size),
|
||||
src0_row_size_padded, src0_row_size, 2);
|
||||
}
|
||||
}
|
||||
@@ -1477,9 +1489,9 @@ static void matvec_id(struct htp_matmul_type * mt,
|
||||
if (src0_end_row != src0_end_row_x2) {
|
||||
uint32_t ir0 = src0_end_row_x2;
|
||||
const uint32_t is0 = (ir0 - src0_start_row);
|
||||
dma_queue_push(dma_queue, spad_src0 + is0 * src0_row_size_padded, src0_row + ir0 * src0_row_size,
|
||||
dma_queue_push_ddr_to_vtcm(dma_queue, dma_make_ptr(spad_src0 + is0 * src0_row_size_padded, src0_row + ir0 * src0_row_size),
|
||||
src0_row_size_padded, src0_row_size, 1);
|
||||
const uint8_t * ss0 = dma_queue_pop(dma_queue);
|
||||
const uint8_t * ss0 = dma_queue_pop(dma_queue).dst;
|
||||
mt->vec_dot(ne00, &dst_row[ir0], ss0, src1_col);
|
||||
}
|
||||
}
|
||||
@@ -1594,6 +1606,118 @@ static void matmul_f16_f32(struct htp_tensor * restrict src0,
|
||||
|
||||
// *** dynamic quant
|
||||
|
||||
static inline void quantize_block_fp32_q8x1(float * restrict x, uint8_t * restrict y_q, uint8_t * restrict y_d) {
|
||||
assert((unsigned long) x % 128 == 0);
|
||||
assert((unsigned long) y_q % 128 == 0);
|
||||
|
||||
HVX_Vector * vx = (HVX_Vector *) x;
|
||||
HVX_Vector zero = Q6_V_vsplat_R(0);
|
||||
|
||||
// Use reduce max fp32 to find max(abs(e)) first
|
||||
HVX_Vector vmax0_sf = hvx_vec_reduce_max_fp32(hvx_vec_abs_fp32(vx[0]));
|
||||
HVX_Vector vmax1_sf = hvx_vec_reduce_max_fp32(hvx_vec_abs_fp32(vx[1]));
|
||||
HVX_Vector vmax2_sf = hvx_vec_reduce_max_fp32(hvx_vec_abs_fp32(vx[2]));
|
||||
HVX_Vector vmax3_sf = hvx_vec_reduce_max_fp32(hvx_vec_abs_fp32(vx[3]));
|
||||
// Load and convert into QF32
|
||||
HVX_Vector vx0_qf = Q6_Vqf32_vsub_VsfVsf(vx[0], zero); // 32 elements
|
||||
HVX_Vector vx1_qf = Q6_Vqf32_vsub_VsfVsf(vx[1], zero); // 32 elements
|
||||
HVX_Vector vx2_qf = Q6_Vqf32_vsub_VsfVsf(vx[2], zero); // 32 elements
|
||||
HVX_Vector vx3_qf = Q6_Vqf32_vsub_VsfVsf(vx[3], zero); // 32 elements
|
||||
|
||||
// Convert to QF32
|
||||
HVX_Vector vmax0_qf = Q6_Vqf32_vsub_VsfVsf(vmax0_sf, zero);
|
||||
HVX_Vector vmax1_qf = Q6_Vqf32_vsub_VsfVsf(vmax1_sf, zero);
|
||||
HVX_Vector vmax2_qf = Q6_Vqf32_vsub_VsfVsf(vmax2_sf, zero);
|
||||
HVX_Vector vmax3_qf = Q6_Vqf32_vsub_VsfVsf(vmax3_sf, zero);
|
||||
|
||||
// Combine and convert to fp16
|
||||
HVX_Vector vmax01_hf = Q6_Vh_vdeal_Vh(Q6_Vhf_equals_Wqf32(Q6_W_vcombine_VV(vmax1_qf, vmax0_qf)));
|
||||
HVX_Vector vmax23_hf = Q6_Vh_vdeal_Vh(Q6_Vhf_equals_Wqf32(Q6_W_vcombine_VV(vmax3_qf, vmax2_qf)));
|
||||
|
||||
// Convert into fp16
|
||||
HVX_Vector vx01_hf = Q6_Vh_vdeal_Vh(Q6_Vhf_equals_Wqf32(Q6_W_vcombine_VV(vx1_qf, vx0_qf)));
|
||||
HVX_Vector vx23_hf = Q6_Vh_vdeal_Vh(Q6_Vhf_equals_Wqf32(Q6_W_vcombine_VV(vx3_qf, vx2_qf)));
|
||||
|
||||
// Replicate first fp16 scale across all lanes
|
||||
HVX_Vector ctrl = *(const HVX_Vector *) repl_2x_fp16;
|
||||
vmax01_hf = Q6_V_vdelta_VV(vmax01_hf, ctrl);
|
||||
vmax23_hf = Q6_V_vdelta_VV(vmax23_hf, ctrl);
|
||||
|
||||
HVX_Vector vd01_qf16 = Q6_Vqf16_vmpy_VhfVhf(vmax01_hf, Q6_Vh_vsplat_R(0x2008)); // 1.0 / 127.0
|
||||
HVX_Vector vd23_qf16 = Q6_Vqf16_vmpy_VhfVhf(vmax23_hf, Q6_Vh_vsplat_R(0x2008)); // 1.0 / 127.0
|
||||
HVX_Vector vd01_hf = Q6_Vhf_equals_Vqf16(vd01_qf16);
|
||||
HVX_Vector vd23_hf = Q6_Vhf_equals_Vqf16(vd23_qf16);
|
||||
|
||||
hvx_vec_store_u(y_d + 0, 2, vd01_hf);
|
||||
HVX_Vector rotated_vd_hf = Q6_V_vror_VR(vd01_hf, 64);
|
||||
hvx_vec_store_u(y_d + 2, 2, rotated_vd_hf);
|
||||
|
||||
hvx_vec_store_u(y_d + 4, 2, vd23_hf);
|
||||
rotated_vd_hf = Q6_V_vror_VR(vd23_hf, 64);
|
||||
hvx_vec_store_u(y_d + 6, 2, rotated_vd_hf);
|
||||
|
||||
// Divide input by the scale
|
||||
HVX_Vector vd01_inv_hf = hvx_vec_inverse_fp16(vd01_hf);
|
||||
HVX_Vector vd23_inv_hf = hvx_vec_inverse_fp16(vd23_hf);
|
||||
vx01_hf = Q6_Vhf_equals_Vqf16(Q6_Vqf16_vmpy_VhfVhf(vx01_hf, vd01_inv_hf));
|
||||
vx23_hf = Q6_Vhf_equals_Vqf16(Q6_Vqf16_vmpy_VhfVhf(vx23_hf, vd23_inv_hf));
|
||||
|
||||
// Convert to int8
|
||||
HVX_Vector vx01_i16 = hvx_vec_i16_from_hf_rnd_sat(vx01_hf);
|
||||
HVX_Vector vx23_i16 = hvx_vec_i16_from_hf_rnd_sat(vx23_hf);
|
||||
HVX_Vector vx_i8 = Q6_Vb_vpack_VhVh_sat(vx23_i16, vx01_i16);
|
||||
|
||||
*(HVX_Vector *) y_q = vx_i8;
|
||||
}
|
||||
|
||||
static inline void quantize_block_fp32_q8x2(float * restrict x, uint8_t * restrict y_q, uint8_t * restrict y_d) {
|
||||
assert((unsigned long) x % 128 == 0);
|
||||
assert((unsigned long) y_q % 128 == 0);
|
||||
|
||||
HVX_Vector * vx = (HVX_Vector *) x;
|
||||
|
||||
// Load and convert into QF32
|
||||
HVX_Vector zero = Q6_V_vsplat_R(0);
|
||||
HVX_Vector vx0_qf = Q6_Vqf32_vsub_VsfVsf(vx[0], zero); // 32 elements
|
||||
HVX_Vector vx1_qf = Q6_Vqf32_vsub_VsfVsf(vx[1], zero); // 32 elements
|
||||
HVX_Vector vx2_qf = Q6_Vqf32_vsub_VsfVsf(vx[2], zero); // 32 elements
|
||||
HVX_Vector vx3_qf = Q6_Vqf32_vsub_VsfVsf(vx[3], zero); // 32 elements
|
||||
|
||||
// Convert into fp16
|
||||
HVX_Vector vx01_hf = Q6_Vh_vdeal_Vh(Q6_Vhf_equals_Wqf32(Q6_W_vcombine_VV(vx1_qf, vx0_qf)));
|
||||
HVX_Vector vx23_hf = Q6_Vh_vdeal_Vh(Q6_Vhf_equals_Wqf32(Q6_W_vcombine_VV(vx3_qf, vx2_qf)));
|
||||
|
||||
// Compute max and scale
|
||||
HVX_Vector vmax01_hf = hvx_vec_reduce_max_fp16(hvx_vec_abs_fp16(vx01_hf));
|
||||
HVX_Vector vmax23_hf = hvx_vec_reduce_max_fp16(hvx_vec_abs_fp16(vx23_hf));
|
||||
|
||||
// Replicate first fp16 scale across all lanes
|
||||
HVX_Vector ctrl = *(const HVX_Vector *) repl_1x_fp16;
|
||||
vmax01_hf = Q6_V_vdelta_VV(vmax01_hf, ctrl);
|
||||
vmax23_hf = Q6_V_vdelta_VV(vmax23_hf, ctrl);
|
||||
|
||||
HVX_Vector vd01_qf16 = Q6_Vqf16_vmpy_VhfVhf(vmax01_hf, Q6_Vh_vsplat_R(0x2008)); // 1.0 / 127.0
|
||||
HVX_Vector vd23_qf16 = Q6_Vqf16_vmpy_VhfVhf(vmax23_hf, Q6_Vh_vsplat_R(0x2008)); // 1.0 / 127.0
|
||||
HVX_Vector vd01_hf = Q6_Vhf_equals_Vqf16(vd01_qf16);
|
||||
HVX_Vector vd23_hf = Q6_Vhf_equals_Vqf16(vd23_qf16);
|
||||
|
||||
hvx_vec_store_u(y_d + 0, 4, vd01_hf);
|
||||
hvx_vec_store_u(y_d + 4, 4, vd23_hf);
|
||||
|
||||
// Divide input by the scale
|
||||
HVX_Vector vd01_inv_hf = hvx_vec_inverse_fp16(vd01_hf);
|
||||
HVX_Vector vd23_inv_hf = hvx_vec_inverse_fp16(vd23_hf);
|
||||
vx01_hf = Q6_Vhf_equals_Vqf16(Q6_Vqf16_vmpy_VhfVhf(vx01_hf, vd01_inv_hf));
|
||||
vx23_hf = Q6_Vhf_equals_Vqf16(Q6_Vqf16_vmpy_VhfVhf(vx23_hf, vd23_inv_hf));
|
||||
|
||||
// Convert to int8
|
||||
HVX_Vector vx01_i16 = hvx_vec_i16_from_hf_rnd_sat(vx01_hf);
|
||||
HVX_Vector vx23_i16 = hvx_vec_i16_from_hf_rnd_sat(vx23_hf);
|
||||
HVX_Vector vx_i8 = Q6_Vb_vpack_VhVh_sat(vx23_i16, vx01_i16);
|
||||
|
||||
*(HVX_Vector *) y_q = vx_i8;
|
||||
}
|
||||
|
||||
static inline void quantize_block_fp32_q8x4(float * restrict x, uint8_t * restrict y_q, uint8_t * restrict y_d) {
|
||||
assert((unsigned long) x % 128 == 0);
|
||||
assert((unsigned long) y_q % 128 == 0);
|
||||
@@ -1655,10 +1779,24 @@ static void quantize_row_fp32_q8x4x2(float * restrict x, uint8_t * restrict y, u
|
||||
uint8_t * restrict t_d = (uint8_t *) x;
|
||||
|
||||
for (uint32_t i = 0; i < nb; i++) {
|
||||
#if FP32_QUANTIZE_GROUP_SIZE == 32
|
||||
quantize_block_fp32_q8x1(x + (i * 2 + 0) * qk / 2, y_q + (i * 2 + 0) * qblk_size / 2,
|
||||
t_d + (i * 2 + 0) * dblk_size / 2);
|
||||
quantize_block_fp32_q8x1(x + (i * 2 + 1) * qk / 2, y_q + (i * 2 + 1) * qblk_size / 2,
|
||||
t_d + (i * 2 + 1) * dblk_size / 2);
|
||||
#elif FP32_QUANTIZE_GROUP_SIZE == 64
|
||||
quantize_block_fp32_q8x2(x + (i * 2 + 0) * qk / 2, y_q + (i * 2 + 0) * qblk_size / 2,
|
||||
t_d + (i * 2 + 0) * dblk_size / 2);
|
||||
quantize_block_fp32_q8x2(x + (i * 2 + 1) * qk / 2, y_q + (i * 2 + 1) * qblk_size / 2,
|
||||
t_d + (i * 2 + 1) * dblk_size / 2);
|
||||
#elif FP32_QUANTIZE_GROUP_SIZE == 128
|
||||
quantize_block_fp32_q8x4(x + (i * 2 + 0) * qk / 2, y_q + (i * 2 + 0) * qblk_size / 2,
|
||||
t_d + (i * 2 + 0) * dblk_size / 2);
|
||||
quantize_block_fp32_q8x4(x + (i * 2 + 1) * qk / 2, y_q + (i * 2 + 1) * qblk_size / 2,
|
||||
t_d + (i * 2 + 1) * dblk_size / 2);
|
||||
#else
|
||||
#error "FP32_QUANTIZE_GROUP_SIZE must be 32, 64, or 128"
|
||||
#endif
|
||||
}
|
||||
|
||||
// now copy the scales into final location
|
||||
@@ -1671,6 +1809,7 @@ static void quantize_fp32_q8x4x2(const struct htp_tensor * src,
|
||||
uint32_t nth,
|
||||
uint32_t ith,
|
||||
uint32_t nrows_per_thread) {
|
||||
|
||||
uint64_t t1 = HAP_perf_get_qtimer_count();
|
||||
|
||||
const uint32_t ne0 = src->ne[0];
|
||||
|
||||
@@ -494,6 +494,7 @@ struct ggml_backend_opencl_context {
|
||||
cl_kernel kernel_convert_block_q8_0, kernel_restore_block_q8_0;
|
||||
cl_kernel kernel_mul_mat_q4_0_f32_8x_flat;
|
||||
cl_kernel kernel_convert_block_q4_0_noshuffle;
|
||||
cl_kernel kernel_restore_block_q4_0_noshuffle;
|
||||
cl_kernel kernel_mul_mat_q4_0_f32_1d_8x_flat, kernel_mul_mat_q4_0_f32_1d_16x_flat;
|
||||
cl_kernel kernel_mul_mv_q6_K_f32;
|
||||
cl_kernel kernel_mul_mv_mxfp4_f32, kernel_mul_mv_mxfp4_f32_flat;
|
||||
@@ -634,6 +635,7 @@ struct ggml_backend_opencl_context {
|
||||
cl_kernel kernel_transpose_32;
|
||||
cl_kernel kernel_transpose_32_16;
|
||||
cl_kernel kernel_transpose_16;
|
||||
cl_kernel kernel_transpose_16_buf;
|
||||
cl_kernel kernel_transpose_16_4x1;
|
||||
|
||||
cl_mem A_s_d_max; // max scale buffer size for transpose
|
||||
@@ -806,6 +808,7 @@ static void load_cl_kernels(ggml_backend_opencl_context *backend_ctx, ggml_cl_ve
|
||||
build_program_from_source(backend_ctx->context, backend_ctx->device, kernel_src.c_str(), compile_opts);
|
||||
|
||||
CL_CHECK((backend_ctx->kernel_convert_block_q4_0_noshuffle = clCreateKernel(backend_ctx->program_cvt, "kernel_convert_block_q4_0_noshuffle", &err), err));
|
||||
CL_CHECK((backend_ctx->kernel_restore_block_q4_0_noshuffle = clCreateKernel(backend_ctx->program_cvt, "kernel_restore_block_q4_0_noshuffle", &err), err));
|
||||
CL_CHECK((backend_ctx->kernel_convert_block_q4_0 = clCreateKernel(backend_ctx->program_cvt, "kernel_convert_block_q4_0", &err), err));
|
||||
CL_CHECK((backend_ctx->kernel_restore_block_q4_0 = clCreateKernel(backend_ctx->program_cvt, "kernel_restore_block_q4_0", &err), err));
|
||||
CL_CHECK((backend_ctx->kernel_convert_block_mxfp4 = clCreateKernel(backend_ctx->program_cvt, "kernel_convert_block_mxfp4", &err), err));
|
||||
@@ -2004,7 +2007,8 @@ static void load_cl_kernels(ggml_backend_opencl_context *backend_ctx, ggml_cl_ve
|
||||
CL_CHECK((backend_ctx->kernel_transpose_32_16 = clCreateKernel(backend_ctx->program_transpose, "kernel_transpose_32_16", &err), err));
|
||||
CL_CHECK((backend_ctx->kernel_transpose_32 = clCreateKernel(backend_ctx->program_transpose, "kernel_transpose_32", &err), err));
|
||||
CL_CHECK((backend_ctx->kernel_transpose_16 = clCreateKernel(backend_ctx->program_transpose, "kernel_transpose_16", &err), err));
|
||||
CL_CHECK((backend_ctx->kernel_transpose_16_4x1 = clCreateKernel(backend_ctx->program_transpose, "kernel_transpose_16_4x1", &err), err));
|
||||
CL_CHECK((backend_ctx->kernel_transpose_16_buf = clCreateKernel(backend_ctx->program_transpose, "kernel_transpose_16_buf", &err), err));
|
||||
CL_CHECK((backend_ctx->kernel_transpose_16_4x1 = clCreateKernel(backend_ctx->program_transpose, "kernel_transpose_16_4x1", &err), err));
|
||||
GGML_LOG_CONT(".");
|
||||
}
|
||||
|
||||
@@ -3933,6 +3937,91 @@ static void ggml_backend_opencl_buffer_get_tensor(ggml_backend_buffer_t buffer,
|
||||
if (tensor->type == GGML_TYPE_Q4_0) {
|
||||
ggml_tensor_extra_cl_q4_0 * extra = (ggml_tensor_extra_cl_q4_0 *)tensor->extra;
|
||||
|
||||
#ifdef GGML_OPENCL_USE_ADRENO_KERNELS
|
||||
if (use_adreno_kernels(backend_ctx, tensor)) {
|
||||
cl_int err;
|
||||
cl_kernel kernel;
|
||||
|
||||
cl_int M = tensor->ne[1]; // ne01
|
||||
cl_int K = tensor->ne[0]; // ne00
|
||||
|
||||
GGML_ASSERT(K % 32 == 0);
|
||||
GGML_ASSERT(M % 4 == 0);
|
||||
|
||||
size_t size_q = (ggml_nelements(tensor)/ggml_blck_size(tensor->type))*ggml_blck_size(tensor->type)/2;
|
||||
size_t size_d = (ggml_nelements(tensor)/ggml_blck_size(tensor->type))*sizeof(ggml_fp16_t);
|
||||
GGML_ASSERT(size_d + size_q == ggml_nbytes(tensor) && "Incorrect tensor size");
|
||||
|
||||
cl_mem buf_trans_q;
|
||||
cl_mem buf_trans_d;
|
||||
|
||||
CL_CHECK((buf_trans_q = clCreateBuffer(context, CL_MEM_READ_WRITE,
|
||||
size_q, NULL, &err), err));
|
||||
CL_CHECK((buf_trans_d = clCreateBuffer(context, CL_MEM_READ_WRITE,
|
||||
size_d, NULL, &err), err));
|
||||
|
||||
kernel = backend_ctx->kernel_transpose_16_buf;
|
||||
|
||||
// transpose q back
|
||||
cl_int stride_k_q = K/4;
|
||||
size_t local_size_q[3] = {64, 1, 1};
|
||||
size_t global_size_q[3] = {(size_t)M, (size_t)stride_k_q, 1};
|
||||
|
||||
CL_CHECK(clSetKernelArg(kernel, 0, sizeof(cl_mem), &extra->q));
|
||||
CL_CHECK(clSetKernelArg(kernel, 1, sizeof(cl_mem), &buf_trans_q));
|
||||
CL_CHECK(clSetKernelArg(kernel, 2, sizeof(cl_int), &M));
|
||||
CL_CHECK(clSetKernelArg(kernel, 3, sizeof(cl_int), &stride_k_q));
|
||||
|
||||
CL_CHECK(clEnqueueNDRangeKernel(queue, kernel, 3, NULL,
|
||||
global_size_q, local_size_q, 0, NULL, NULL));
|
||||
|
||||
// transpose scales back
|
||||
cl_int stride_k_d = K/32;
|
||||
size_t local_size_d[3] = {64, 1, 1};
|
||||
size_t global_size_d[3] = {(size_t)M, (size_t)stride_k_d, 1};
|
||||
|
||||
CL_CHECK(clSetKernelArg(kernel, 0, sizeof(cl_mem), &extra->d));
|
||||
CL_CHECK(clSetKernelArg(kernel, 1, sizeof(cl_mem), &buf_trans_d));
|
||||
CL_CHECK(clSetKernelArg(kernel, 2, sizeof(cl_int), &M));
|
||||
CL_CHECK(clSetKernelArg(kernel, 3, sizeof(cl_int), &stride_k_d));
|
||||
|
||||
CL_CHECK(clEnqueueNDRangeKernel(queue, kernel, 3, NULL,
|
||||
global_size_d, local_size_d, 0, NULL, NULL));
|
||||
|
||||
// unpack
|
||||
cl_mem data_device = clCreateBuffer(context, CL_MEM_READ_WRITE,
|
||||
ggml_nbytes(tensor), NULL, &err);
|
||||
CL_CHECK(err);
|
||||
|
||||
cl_uchar mask_0F = 0x0F;
|
||||
cl_uchar mask_F0 = 0xF0;
|
||||
|
||||
size_t global_work_size[] = {(size_t)ggml_nelements(tensor)/ggml_blck_size(tensor->type), 1, 1};
|
||||
size_t local_work_size[] = {1, 1, 1};
|
||||
|
||||
kernel = backend_ctx->kernel_restore_block_q4_0_noshuffle;
|
||||
CL_CHECK(clSetKernelArg(kernel, 0, sizeof(cl_mem), &buf_trans_q));
|
||||
CL_CHECK(clSetKernelArg(kernel, 1, sizeof(cl_mem), &buf_trans_d));
|
||||
CL_CHECK(clSetKernelArg(kernel, 2, sizeof(cl_mem), &data_device));
|
||||
CL_CHECK(clSetKernelArg(kernel, 3, sizeof(cl_uchar), &mask_0F));
|
||||
CL_CHECK(clSetKernelArg(kernel, 4, sizeof(cl_uchar), &mask_F0));
|
||||
|
||||
CL_CHECK(clEnqueueNDRangeKernel(queue, kernel, 3, NULL,
|
||||
global_work_size, local_work_size, 0, NULL, NULL));
|
||||
|
||||
// read back to host
|
||||
CL_CHECK(clEnqueueReadBuffer(
|
||||
queue, data_device, CL_TRUE, offset,
|
||||
size, data, 0, NULL, NULL));
|
||||
|
||||
CL_CHECK(clReleaseMemObject(data_device));
|
||||
CL_CHECK(clReleaseMemObject(buf_trans_q));
|
||||
CL_CHECK(clReleaseMemObject(buf_trans_d));
|
||||
|
||||
return;
|
||||
}
|
||||
#endif
|
||||
|
||||
cl_int err;
|
||||
cl_mem data_device = clCreateBuffer(context, CL_MEM_READ_WRITE,
|
||||
ggml_nbytes(tensor), NULL, &err);
|
||||
|
||||
@@ -117,6 +117,27 @@ kernel void kernel_convert_block_q4_0_noshuffle(
|
||||
}
|
||||
}
|
||||
|
||||
kernel void kernel_restore_block_q4_0_noshuffle(
|
||||
global uchar * src_q,
|
||||
global half * src_d,
|
||||
global struct block_q4_0 * dst,
|
||||
uchar mask_0F,
|
||||
uchar mask_F0
|
||||
) {
|
||||
global struct block_q4_0 * b = (global struct block_q4_0 *) dst + get_global_id(0);
|
||||
global uchar * q = (global uchar *) src_q + QK4_0/2*get_global_id(0);
|
||||
global half * d = (global half *) src_d + get_global_id(0);
|
||||
|
||||
b->d = *d;
|
||||
for (int i = 0; i < QK4_0/4; ++i) {
|
||||
uchar x0 = q[i + 0 ] ;
|
||||
uchar x1 = q[i + QK4_0/4];
|
||||
|
||||
b->qs[2*i + 0] = convert_uchar((x0 & mask_0F) | ((x1 & mask_0F) << 4));
|
||||
b->qs[2*i + 1] = convert_uchar(((x0 & mask_F0) >> 4) | (x1 & mask_F0));
|
||||
}
|
||||
}
|
||||
|
||||
//------------------------------------------------------------------------------
|
||||
// block_mxfp4
|
||||
//------------------------------------------------------------------------------
|
||||
|
||||
@@ -44,6 +44,19 @@ kernel void kernel_transpose_16_4x1(
|
||||
write_imageh(output, i * rows + j, (half4)(temp0, temp1, temp2, temp3));
|
||||
}
|
||||
|
||||
// Transpose treating each element as 16-bit using buffer
|
||||
kernel void kernel_transpose_16_buf(
|
||||
global const ushort * input,
|
||||
global ushort * output,
|
||||
const int ldi,
|
||||
const int ldo
|
||||
) {
|
||||
const int x = get_global_id(0);
|
||||
const int y = get_global_id(1);
|
||||
|
||||
output[x*ldo + y] = input[y*ldi + x];
|
||||
}
|
||||
|
||||
// 32-bit transpose, loading/storing a 4x4 tile of elements
|
||||
kernel void kernel_transpose_32(
|
||||
__read_only image1d_buffer_t input,
|
||||
|
||||
@@ -583,7 +583,7 @@ static rpc_tensor serialize_tensor(const ggml_tensor * tensor) {
|
||||
if (tensor->buffer) {
|
||||
ggml_backend_buffer_t buffer = tensor->buffer;
|
||||
ggml_backend_rpc_buffer_context * ctx = (ggml_backend_rpc_buffer_context *)buffer->context;
|
||||
result.buffer = ctx->remote_ptr;
|
||||
result.buffer = ctx != nullptr ? ctx->remote_ptr : 0;
|
||||
} else {
|
||||
result.buffer = 0;
|
||||
}
|
||||
|
||||
@@ -689,6 +689,7 @@ struct vk_device_struct {
|
||||
vk_pipeline pipeline_gelu_quick[2];
|
||||
vk_pipeline pipeline_silu[2];
|
||||
vk_pipeline pipeline_relu[2];
|
||||
vk_pipeline pipeline_xielu[2];
|
||||
vk_pipeline pipeline_neg[2];
|
||||
vk_pipeline pipeline_tanh[2];
|
||||
vk_pipeline pipeline_sigmoid[2];
|
||||
@@ -730,7 +731,7 @@ struct vk_device_struct {
|
||||
|
||||
vk_pipeline pipeline_rope_norm_f32, pipeline_rope_norm_f16, pipeline_rope_norm_f32_f16;
|
||||
vk_pipeline pipeline_rope_neox_f32, pipeline_rope_neox_f16, pipeline_rope_neox_f32_f16;
|
||||
vk_pipeline pipeline_rope_multi_f32, pipeline_rope_multi_f16;
|
||||
vk_pipeline pipeline_rope_multi_f32, pipeline_rope_multi_f16, pipeline_rope_multi_f32_f16;
|
||||
vk_pipeline pipeline_rope_vision_f32, pipeline_rope_vision_f16;
|
||||
vk_pipeline pipeline_argsort_f32[num_argsort_pipelines];
|
||||
vk_pipeline pipeline_argsort_large_f32[num_argsort_pipelines];
|
||||
@@ -855,6 +856,15 @@ struct vk_subbuffer {
|
||||
}
|
||||
};
|
||||
|
||||
// vk_event is used for the event-related backend interfaces. It uses 'event' for
|
||||
// event_wait and 'fence' for event_synchronize. Polling on an event for
|
||||
// event_synchronize wouldn't be sufficient to wait for command buffers to complete,
|
||||
// and would lead to validation errors.
|
||||
struct vk_event {
|
||||
vk::Event event;
|
||||
vk::Fence fence;
|
||||
};
|
||||
|
||||
struct vk_semaphore {
|
||||
vk::Semaphore s;
|
||||
uint64_t value;
|
||||
@@ -990,6 +1000,8 @@ struct vk_op_push_constants {
|
||||
uint32_t KY;
|
||||
float param1;
|
||||
float param2;
|
||||
float param3;
|
||||
float param4;
|
||||
};
|
||||
|
||||
struct vk_op_glu_push_constants {
|
||||
@@ -1258,6 +1270,7 @@ struct vk_op_im2col_push_constants {
|
||||
int32_t s0; int32_t s1;
|
||||
int32_t p0; int32_t p1;
|
||||
int32_t d0; int32_t d1;
|
||||
uint32_t batch_IC;
|
||||
};
|
||||
|
||||
struct vk_op_im2col_3d_push_constants {
|
||||
@@ -1527,6 +1540,8 @@ private:
|
||||
#endif // GGML_VULKAN_MEMORY_DEBUG
|
||||
|
||||
static bool vk_perf_logger_enabled = false;
|
||||
static bool vk_perf_logger_concurrent = false;
|
||||
static bool vk_enable_sync_logger = false;
|
||||
// number of calls between perf logger prints
|
||||
static uint32_t vk_perf_logger_frequency = 1;
|
||||
|
||||
@@ -1577,14 +1592,14 @@ class vk_perf_logger {
|
||||
flops.clear();
|
||||
}
|
||||
|
||||
void log_timing(const ggml_tensor * node, const char *fusion_name, uint64_t time) {
|
||||
std::string get_node_fusion_name(const ggml_tensor * node, const char *fusion_name, uint64_t *n_flops) {
|
||||
*n_flops = 0;
|
||||
std::string fusion_str;
|
||||
if (fusion_name) {
|
||||
fusion_str = fusion_name + std::string(" ");
|
||||
}
|
||||
if (node->op == GGML_OP_UNARY) {
|
||||
timings[fusion_str + ggml_unary_op_name(ggml_get_unary_op(node))].push_back(time);
|
||||
return;
|
||||
return fusion_str + ggml_unary_op_name(ggml_get_unary_op(node));
|
||||
}
|
||||
if (node->op == GGML_OP_MUL_MAT || node->op == GGML_OP_MUL_MAT_ID) {
|
||||
const uint64_t m = node->ne[0];
|
||||
@@ -1606,9 +1621,8 @@ class vk_perf_logger {
|
||||
name += " batch=" + std::to_string(batch);
|
||||
}
|
||||
name = fusion_str + name;
|
||||
timings[name].push_back(time);
|
||||
flops[name].push_back(m * n * (k + (k - 1)) * batch);
|
||||
return;
|
||||
*n_flops = m * n * (k + (k - 1)) * batch;
|
||||
return name;
|
||||
}
|
||||
if (node->op == GGML_OP_CONV_2D || node->op == GGML_OP_CONV_TRANSPOSE_2D) {
|
||||
std::string name = ggml_op_name(node->op);
|
||||
@@ -1624,20 +1638,17 @@ class vk_perf_logger {
|
||||
uint64_t size_M = Cout;
|
||||
uint64_t size_K = Cin * KW * KH;
|
||||
uint64_t size_N = N * OW * OH;
|
||||
uint64_t n_flops = size_M * size_N * (size_K + (size_K - 1));
|
||||
*n_flops = size_M * size_N * (size_K + (size_K - 1));
|
||||
name += " M=Cout=" + std::to_string(size_M) + ", K=Cin*KW*KH=" + std::to_string(size_K) +
|
||||
", N=N*OW*OH=" + std::to_string(size_N);
|
||||
name = fusion_str + name;
|
||||
flops[name].push_back(n_flops);
|
||||
timings[name].push_back(time);
|
||||
return;
|
||||
return name;
|
||||
}
|
||||
if (node->op == GGML_OP_RMS_NORM) {
|
||||
std::string name = ggml_op_name(node->op);
|
||||
name += "(" + std::to_string(node->ne[0]) + "," + std::to_string(node->ne[1]) + "," + std::to_string(node->ne[2]) + "," + std::to_string(node->ne[3]) + ")";
|
||||
name = fusion_str + name;
|
||||
timings[name].push_back(time);
|
||||
return;
|
||||
return name;
|
||||
}
|
||||
if (node->op == GGML_OP_FLASH_ATTN_EXT) {
|
||||
const ggml_tensor * dst = node;
|
||||
@@ -1653,8 +1664,7 @@ class vk_perf_logger {
|
||||
" k(" << k->ne[0] << "," << k->ne[1] << "," << k->ne[2] << "," << k->ne[3] << "), " <<
|
||||
" v(" << v->ne[0] << "," << v->ne[1] << "," << v->ne[2] << "," << v->ne[3] << "), " <<
|
||||
" m(" << (m?m->ne[0]:0) << "," << (m?m->ne[1]:0) << "," << (m?m->ne[2]:0) << "," << (m?m->ne[3]:0) << ")";
|
||||
timings[name.str()].push_back(time);
|
||||
return;
|
||||
return name.str();
|
||||
}
|
||||
if (node->op == GGML_OP_TOP_K) {
|
||||
std::stringstream name;
|
||||
@@ -1662,11 +1672,38 @@ class vk_perf_logger {
|
||||
name << ggml_op_name(node->op) <<
|
||||
" K=" << node->ne[0] <<
|
||||
" (" << node->src[0]->ne[0] << "," << node->src[0]->ne[1] << "," << node->src[0]->ne[2] << "," << node->src[0]->ne[3] << ")";
|
||||
timings[name.str()].push_back(time);
|
||||
return;
|
||||
return name.str();
|
||||
}
|
||||
timings[fusion_str + ggml_op_name(node->op)].push_back(time);
|
||||
return fusion_str + ggml_op_name(node->op);
|
||||
}
|
||||
|
||||
void log_timing(const ggml_tensor * node, const char *fusion_name, uint64_t time) {
|
||||
uint64_t n_flops;
|
||||
std::string name = get_node_fusion_name(node, fusion_name, &n_flops);
|
||||
if (n_flops) {
|
||||
flops[name].push_back(n_flops);
|
||||
}
|
||||
timings[name].push_back(time);
|
||||
}
|
||||
|
||||
void log_timing(const std::vector<ggml_tensor *> &nodes, const std::vector<const char *> &names, uint64_t time) {
|
||||
uint64_t total_flops = 0;
|
||||
std::string name;
|
||||
for (size_t n = 0; n < nodes.size(); ++n) {
|
||||
uint64_t n_flops = 0;
|
||||
name += get_node_fusion_name(nodes[n], names[n], &n_flops);
|
||||
total_flops += n_flops;
|
||||
|
||||
if (n != nodes.size() - 1) {
|
||||
name += ", ";
|
||||
}
|
||||
}
|
||||
if (total_flops) {
|
||||
flops[name].push_back(total_flops);
|
||||
}
|
||||
timings[name].push_back(time);
|
||||
}
|
||||
|
||||
private:
|
||||
std::map<std::string, std::vector<uint64_t>> timings;
|
||||
std::map<std::string, std::vector<uint64_t>> flops;
|
||||
@@ -1729,7 +1766,9 @@ struct ggml_backend_vk_context {
|
||||
std::unique_ptr<vk_perf_logger> perf_logger;
|
||||
vk::QueryPool query_pool;
|
||||
std::vector<const char *> query_fusion_names;
|
||||
std::vector<int> query_fusion_node_count;
|
||||
std::vector<ggml_tensor *> query_nodes;
|
||||
std::vector<int> query_node_idx;
|
||||
int32_t num_queries {};
|
||||
int32_t query_idx {};
|
||||
};
|
||||
@@ -2514,6 +2553,15 @@ static void ggml_vk_sync_buffers(ggml_backend_vk_context* ctx, vk_context& subct
|
||||
);
|
||||
}
|
||||
|
||||
static void ggml_vk_set_event(vk_context& ctx, vk::Event& event) {
|
||||
VK_LOG_DEBUG("ggml_vk_set_event()");
|
||||
|
||||
ctx->s->buffer.setEvent(
|
||||
event,
|
||||
ctx->p->q->stage_flags
|
||||
);
|
||||
}
|
||||
|
||||
static void ggml_vk_wait_events(vk_context& ctx, std::vector<vk::Event>&& events) {
|
||||
VK_LOG_DEBUG("ggml_vk_wait_events()");
|
||||
if (events.empty()) {
|
||||
@@ -3947,6 +3995,7 @@ static void ggml_vk_load_shaders(vk_device& device) {
|
||||
CREATE_UNARY(gelu_quick)
|
||||
CREATE_UNARY(silu)
|
||||
CREATE_UNARY(relu)
|
||||
CREATE_UNARY(xielu)
|
||||
CREATE_UNARY(neg)
|
||||
CREATE_UNARY(tanh)
|
||||
CREATE_UNARY(sigmoid)
|
||||
@@ -4028,6 +4077,7 @@ static void ggml_vk_load_shaders(vk_device& device) {
|
||||
|
||||
ggml_vk_create_pipeline(device, device->pipeline_rope_norm_f32_f16, "rope_norm_f32_f16", rope_norm_f32_f16_rte_len, rope_norm_f32_f16_rte_data, "main", 5, sizeof(vk_op_rope_push_constants), {1, 512, 1}, {}, 1);
|
||||
ggml_vk_create_pipeline(device, device->pipeline_rope_neox_f32_f16, "rope_neox_f32_f16", rope_neox_f32_f16_rte_len, rope_neox_f32_f16_rte_data, "main", 5, sizeof(vk_op_rope_push_constants), {1, 512, 1}, {}, 1);
|
||||
ggml_vk_create_pipeline(device, device->pipeline_rope_multi_f32_f16, "rope_multi_f32_f16", rope_multi_f32_f16_rte_len, rope_multi_f32_f16_rte_data, "main", 5, sizeof(vk_op_rope_push_constants), {1, 512, 1}, {}, 1);
|
||||
} else {
|
||||
ggml_vk_create_pipeline(device, device->pipeline_rope_norm_f16, "rope_norm_f16", rope_norm_f16_len, rope_norm_f16_data, "main", 5, sizeof(vk_op_rope_push_constants), {1, 512, 1}, {}, 1);
|
||||
ggml_vk_create_pipeline(device, device->pipeline_rope_neox_f16, "rope_neox_f16", rope_neox_f16_len, rope_neox_f16_data, "main", 5, sizeof(vk_op_rope_push_constants), {1, 512, 1}, {}, 1);
|
||||
@@ -4036,6 +4086,7 @@ static void ggml_vk_load_shaders(vk_device& device) {
|
||||
|
||||
ggml_vk_create_pipeline(device, device->pipeline_rope_norm_f32_f16, "rope_norm_f32_f16", rope_norm_f32_f16_len, rope_norm_f32_f16_data, "main", 5, sizeof(vk_op_rope_push_constants), {1, 512, 1}, {}, 1);
|
||||
ggml_vk_create_pipeline(device, device->pipeline_rope_neox_f32_f16, "rope_neox_f32_f16", rope_neox_f32_f16_len, rope_neox_f32_f16_data, "main", 5, sizeof(vk_op_rope_push_constants), {1, 512, 1}, {}, 1);
|
||||
ggml_vk_create_pipeline(device, device->pipeline_rope_multi_f32_f16, "rope_multi_f32_f16", rope_multi_f32_f16_len, rope_multi_f32_f16_data, "main", 5, sizeof(vk_op_rope_push_constants), {1, 512, 1}, {}, 1);
|
||||
}
|
||||
|
||||
for (uint32_t i = 0; i < num_argsort_pipelines; ++i) {
|
||||
@@ -5194,6 +5245,8 @@ static void ggml_vk_instance_init() {
|
||||
}
|
||||
|
||||
vk_perf_logger_enabled = getenv("GGML_VK_PERF_LOGGER") != nullptr;
|
||||
vk_perf_logger_concurrent = getenv("GGML_VK_PERF_LOGGER_CONCURRENT") != nullptr;
|
||||
vk_enable_sync_logger = getenv("GGML_VK_SYNC_LOGGER") != nullptr;
|
||||
const char* GGML_VK_PERF_LOGGER_FREQUENCY = getenv("GGML_VK_PERF_LOGGER_FREQUENCY");
|
||||
|
||||
if (GGML_VK_PERF_LOGGER_FREQUENCY != nullptr) {
|
||||
@@ -5870,6 +5923,9 @@ static void ggml_vk_dispatch_pipeline(ggml_backend_vk_context* ctx, vk_context&
|
||||
std::cerr << "(" << buffer.buffer << ", " << buffer.offset << ", " << buffer.range << "), ";
|
||||
}
|
||||
std::cerr << "}, (" << wg0 << "," << wg1 << "," << wg2 << "))");
|
||||
GGML_ASSERT(wg0 <= ctx->device->properties.limits.maxComputeWorkGroupCount[0] &&
|
||||
wg1 <= ctx->device->properties.limits.maxComputeWorkGroupCount[1] &&
|
||||
wg2 <= ctx->device->properties.limits.maxComputeWorkGroupCount[2]);
|
||||
GGML_ASSERT(ctx->descriptor_set_idx < ctx->descriptor_sets.size());
|
||||
GGML_ASSERT(descriptor_buffer_infos.size() <= MAX_PARAMETER_COUNT);
|
||||
GGML_ASSERT(pipeline->parameter_count == descriptor_buffer_infos.size());
|
||||
@@ -6053,13 +6109,8 @@ static void ggml_vk_buffer_write_nc_async(ggml_backend_vk_context * ctx, vk_cont
|
||||
}
|
||||
}
|
||||
|
||||
static void ggml_vk_buffer_write_2d_async(vk_context subctx, vk_buffer& dst, size_t offset, const void * src, size_t spitch, size_t width, size_t height, bool sync_staging = false) {
|
||||
static bool ggml_vk_buffer_write_2d_async(vk_context subctx, vk_buffer& dst, size_t offset, const void * src, size_t spitch, size_t width, size_t height, bool sync_staging = false) {
|
||||
VK_LOG_DEBUG("ggml_vk_buffer_write_2d_async(" << width << ", " << height << ")");
|
||||
// Buffer is already mapped
|
||||
if(dst->memory_property_flags & vk::MemoryPropertyFlagBits::eHostVisible) {
|
||||
std::cerr << "ggml_vulkan: buffer_write_async dst buffer is host_visible. Use synchronous write." << std::endl;
|
||||
GGML_ABORT("fatal error");
|
||||
}
|
||||
// Check if src is pinned memory
|
||||
vk_buffer buf = nullptr;
|
||||
size_t buf_offset = 0;
|
||||
@@ -6084,12 +6135,13 @@ static void ggml_vk_buffer_write_2d_async(vk_context subctx, vk_buffer& dst, siz
|
||||
|
||||
ggml_vk_sync_buffers(nullptr, subctx);
|
||||
subctx->s->buffer.copyBuffer(buf->buffer, dst->buffer, slices);
|
||||
return;
|
||||
return true;
|
||||
}
|
||||
VK_LOG_DEBUG("STAGING");
|
||||
|
||||
if (!sync_staging) {
|
||||
GGML_ABORT("Asynchronous write to non-pinned memory not supported");
|
||||
// copy was not handled caller needs to fall back
|
||||
return false;
|
||||
}
|
||||
|
||||
// Staging buffer required
|
||||
@@ -6113,9 +6165,10 @@ static void ggml_vk_buffer_write_2d_async(vk_context subctx, vk_buffer& dst, siz
|
||||
deferred_memcpy((uint8_t *)staging_buffer->ptr + i * width, (const uint8_t *) src + i * spitch, width, &subctx->in_memcpys);
|
||||
}
|
||||
}
|
||||
return true;
|
||||
}
|
||||
|
||||
static void ggml_vk_buffer_write_async(vk_context subctx, vk_buffer& dst, size_t offset, const void * src, size_t size, bool sync_staging = false) {
|
||||
static bool ggml_vk_buffer_write_async(vk_context subctx, vk_buffer& dst, size_t offset, const void * src, size_t size, bool sync_staging = false) {
|
||||
VK_LOG_DEBUG("ggml_vk_buffer_write_async(" << size << ")");
|
||||
return ggml_vk_buffer_write_2d_async(subctx, dst, offset, src, size, size, 1, sync_staging);
|
||||
}
|
||||
@@ -6134,7 +6187,8 @@ static void ggml_vk_buffer_write_2d(vk_buffer& dst, size_t offset, const void *
|
||||
|
||||
vk_context subctx = ggml_vk_create_temporary_context(dst->device->transfer_queue.cmd_pool);
|
||||
ggml_vk_ctx_begin(dst->device, subctx);
|
||||
ggml_vk_buffer_write_2d_async(subctx, dst, offset, src, spitch, width, height, true);
|
||||
bool ret = ggml_vk_buffer_write_2d_async(subctx, dst, offset, src, spitch, width, height, true);
|
||||
GGML_ASSERT(ret);
|
||||
ggml_vk_ctx_end(subctx);
|
||||
|
||||
for (auto& cpy : subctx->in_memcpys) {
|
||||
@@ -8521,6 +8575,8 @@ static vk_pipeline ggml_vk_op_get_pipeline(ggml_backend_vk_context * ctx, const
|
||||
return ctx->device->pipeline_gelu_quick[dst->type == GGML_TYPE_F16];
|
||||
case GGML_UNARY_OP_RELU:
|
||||
return ctx->device->pipeline_relu[dst->type == GGML_TYPE_F16];
|
||||
case GGML_UNARY_OP_XIELU:
|
||||
return ctx->device->pipeline_xielu[dst->type == GGML_TYPE_F16];
|
||||
case GGML_UNARY_OP_NEG:
|
||||
return ctx->device->pipeline_neg[dst->type == GGML_TYPE_F16];
|
||||
case GGML_UNARY_OP_TANH:
|
||||
@@ -8626,6 +8682,9 @@ static vk_pipeline ggml_vk_op_get_pipeline(ggml_backend_vk_context * ctx, const
|
||||
if (src0->type == GGML_TYPE_F32 && dst->type == GGML_TYPE_F32) {
|
||||
return ctx->device->pipeline_rope_multi_f32;
|
||||
}
|
||||
if (src0->type == GGML_TYPE_F32 && dst->type == GGML_TYPE_F16) {
|
||||
return ctx->device->pipeline_rope_multi_f32_f16;
|
||||
}
|
||||
if (src0->type == GGML_TYPE_F16 && dst->type == GGML_TYPE_F16) {
|
||||
return ctx->device->pipeline_rope_multi_f16;
|
||||
}
|
||||
@@ -9056,6 +9115,8 @@ static void ggml_vk_op_f32(ggml_backend_vk_context * ctx, vk_context& subctx, co
|
||||
const uint32_t batch = src1->ne[is_2D ? 3 : 2];
|
||||
|
||||
elements = { OW * KW * KH, OH, batch * IC };
|
||||
elements[1] = std::min(elements[1], ctx->device->properties.limits.maxComputeWorkGroupCount[1]);
|
||||
elements[2] = std::min(elements[2], ctx->device->properties.limits.maxComputeWorkGroupCount[2]);
|
||||
} break;
|
||||
case GGML_OP_IM2COL_3D:
|
||||
{
|
||||
@@ -9667,14 +9728,14 @@ static void ggml_vk_opt_step_adamw(ggml_backend_vk_context * ctx, vk_context& su
|
||||
|
||||
ggml_vk_op_f32_opt_step_adamw(
|
||||
ctx, subctx, dst,
|
||||
{ (uint32_t)n, 0, 0.0f, 0.0f }
|
||||
{ (uint32_t)n, 0, 0.0f, 0.0f, 0.0f, 0.0f }
|
||||
);
|
||||
}
|
||||
|
||||
static void ggml_vk_opt_step_sgd(ggml_backend_vk_context * ctx, vk_context& subctx, const ggml_tensor * src0, const ggml_tensor * src1, const ggml_tensor * src2, ggml_tensor * dst) {
|
||||
const size_t n = ggml_nelements(dst->src[0]);
|
||||
|
||||
ggml_vk_op_f32<vk_op_push_constants>(ctx, subctx, src0, src1, src2, nullptr, dst, GGML_OP_OPT_STEP_SGD, { (uint32_t)n, 0, 0.0f, 0.0f });
|
||||
ggml_vk_op_f32<vk_op_push_constants>(ctx, subctx, src0, src1, src2, nullptr, dst, GGML_OP_OPT_STEP_SGD, { (uint32_t)n, 0, 0.0f, 0.0f, 0.0f, 0.0f });
|
||||
}
|
||||
|
||||
static void ggml_vk_concat(ggml_backend_vk_context * ctx, vk_context& subctx, const ggml_tensor * src0, const ggml_tensor * src1, ggml_tensor * dst) {
|
||||
@@ -9760,6 +9821,7 @@ static void ggml_vk_arange(ggml_backend_vk_context * ctx, vk_context& subctx, gg
|
||||
1,
|
||||
ggml_get_op_params_f32(dst, 0),
|
||||
ggml_get_op_params_f32(dst, 2),
|
||||
0.0f, 0.0f,
|
||||
};
|
||||
|
||||
vk_pipeline pipeline = ggml_vk_op_get_pipeline(ctx, nullptr, nullptr, nullptr, dst, GGML_OP_ARANGE);
|
||||
@@ -9781,6 +9843,7 @@ static void ggml_vk_fill(ggml_backend_vk_context * ctx, vk_context& subctx, ggml
|
||||
1,
|
||||
ggml_get_op_params_f32(dst, 0),
|
||||
0.0f,
|
||||
0.0f, 0.0f,
|
||||
};
|
||||
|
||||
vk_pipeline pipeline = ggml_vk_op_get_pipeline(ctx, nullptr, nullptr, nullptr, dst, GGML_OP_FILL);
|
||||
@@ -9896,13 +9959,13 @@ static void ggml_vk_set_rows(ggml_backend_vk_context * ctx, vk_context& subctx,
|
||||
}
|
||||
|
||||
static void ggml_vk_silu_back(ggml_backend_vk_context * ctx, vk_context& subctx, const ggml_tensor * src0, const ggml_tensor * src1, ggml_tensor * dst) {
|
||||
ggml_vk_op_f32<vk_op_push_constants>(ctx, subctx, src0, src1, nullptr, nullptr, dst, GGML_OP_SILU_BACK, { (uint32_t)ggml_nelements(src0), 0, 0.0f, 0.0f });
|
||||
ggml_vk_op_f32<vk_op_push_constants>(ctx, subctx, src0, src1, nullptr, nullptr, dst, GGML_OP_SILU_BACK, { (uint32_t)ggml_nelements(src0), 0, 0.0f, 0.0f, 0.0f, 0.0f });
|
||||
}
|
||||
|
||||
static void ggml_vk_norm(ggml_backend_vk_context * ctx, vk_context& subctx, const ggml_tensor * src0, ggml_tensor * dst) {
|
||||
float * op_params = (float *)dst->op_params;
|
||||
|
||||
ggml_vk_op_f32<vk_op_push_constants>(ctx, subctx, src0, nullptr, nullptr, nullptr, dst, GGML_OP_NORM, { (uint32_t)src0->ne[0], (uint32_t)src0->ne[1], op_params[0], 0.0f });
|
||||
ggml_vk_op_f32<vk_op_push_constants>(ctx, subctx, src0, nullptr, nullptr, nullptr, dst, GGML_OP_NORM, { (uint32_t)src0->ne[0], (uint32_t)src0->ne[1], op_params[0], 0.0f, 0.0f, 0.0f });
|
||||
}
|
||||
|
||||
static void ggml_vk_group_norm(ggml_backend_vk_context * ctx, vk_context& subctx, const ggml_tensor * src0, ggml_tensor * dst) {
|
||||
@@ -9913,7 +9976,7 @@ static void ggml_vk_group_norm(ggml_backend_vk_context * ctx, vk_context& subctx
|
||||
const float eps = float_op_params[1];
|
||||
const uint32_t group_size = src0->ne[0] * src0->ne[1] * ((src0->ne[2] + num_groups - 1) / num_groups);
|
||||
|
||||
ggml_vk_op_f32<vk_op_push_constants>(ctx, subctx, src0, nullptr, nullptr, nullptr, dst, GGML_OP_GROUP_NORM, { group_size, 0, eps, 0.0f });
|
||||
ggml_vk_op_f32<vk_op_push_constants>(ctx, subctx, src0, nullptr, nullptr, nullptr, dst, GGML_OP_GROUP_NORM, { group_size, 0, eps, 0.0f, 0.0f, 0.0f });
|
||||
}
|
||||
|
||||
static uint32_t ggml_vk_rms_num_partials(ggml_backend_vk_context * ctx, const ggml_tensor *node) {
|
||||
@@ -10082,16 +10145,26 @@ static void ggml_vk_rms_norm(ggml_backend_vk_context * ctx, vk_context& subctx,
|
||||
|
||||
static void ggml_vk_rms_norm_back(ggml_backend_vk_context * ctx, vk_context& subctx, const ggml_tensor * src0, const ggml_tensor * src1, ggml_tensor * dst) {
|
||||
float * op_params = (float *)dst->op_params;
|
||||
ggml_vk_op_f32<vk_op_push_constants>(ctx, subctx, src0, src1, nullptr, nullptr, dst, GGML_OP_RMS_NORM_BACK, { (uint32_t)src0->ne[0], (uint32_t)src0->ne[1], op_params[0], 0.0f });
|
||||
ggml_vk_op_f32<vk_op_push_constants>(ctx, subctx, src0, src1, nullptr, nullptr, dst, GGML_OP_RMS_NORM_BACK, { (uint32_t)src0->ne[0], (uint32_t)src0->ne[1], op_params[0], 0.0f, 0.0f, 0.0f });
|
||||
}
|
||||
|
||||
static void ggml_vk_l2_norm(ggml_backend_vk_context * ctx, vk_context& subctx, const ggml_tensor * src0, ggml_tensor * dst) {
|
||||
float * op_params = (float *)dst->op_params;
|
||||
ggml_vk_op_f32<vk_op_push_constants>(ctx, subctx, src0, nullptr, nullptr, nullptr, dst, GGML_OP_L2_NORM, { (uint32_t)src0->ne[0], (uint32_t)src0->ne[1], op_params[0], 0.0f });
|
||||
ggml_vk_op_f32<vk_op_push_constants>(ctx, subctx, src0, nullptr, nullptr, nullptr, dst, GGML_OP_L2_NORM, { (uint32_t)src0->ne[0], (uint32_t)src0->ne[1], op_params[0], 0.0f, 0.0f, 0.0f });
|
||||
}
|
||||
|
||||
static void ggml_vk_unary(ggml_backend_vk_context * ctx, vk_context& subctx, const ggml_tensor * src0, ggml_tensor * dst) {
|
||||
ggml_vk_op_f32<vk_op_push_constants>(ctx, subctx, src0, nullptr, nullptr, nullptr, dst, GGML_OP_UNARY, { (uint32_t)ggml_nelements(src0), 0, 0.0f, 0.0f });
|
||||
ggml_vk_op_f32<vk_op_push_constants>(ctx, subctx, src0, nullptr, nullptr, nullptr, dst, GGML_OP_UNARY, { (uint32_t)ggml_nelements(src0), 0, 0.0f, 0.0f, 0.0f, 0.0f });
|
||||
}
|
||||
|
||||
static void ggml_vk_xielu(ggml_backend_vk_context * ctx, vk_context& subctx, const ggml_tensor * src0, ggml_tensor * dst) {
|
||||
float * op_params = (float *)dst->op_params;
|
||||
ggml_vk_op_f32<vk_op_push_constants>(ctx, subctx, src0, nullptr, nullptr, nullptr, dst, GGML_OP_UNARY,
|
||||
{
|
||||
(uint32_t)ggml_nelements(src0), 0,
|
||||
op_params[1], op_params[2], op_params[3], op_params[4]
|
||||
}
|
||||
);
|
||||
}
|
||||
|
||||
static void ggml_vk_glu(ggml_backend_vk_context * ctx, vk_context& subctx, const ggml_tensor * src0, const ggml_tensor * src1, ggml_tensor * dst) {
|
||||
@@ -10216,7 +10289,7 @@ static void ggml_vk_soft_max(ggml_backend_vk_context * ctx, vk_context& subctx,
|
||||
|
||||
static void ggml_vk_soft_max_back(ggml_backend_vk_context * ctx, vk_context& subctx, const ggml_tensor * src0, const ggml_tensor * src1, ggml_tensor * dst) {
|
||||
float * op_params = (float *)dst->op_params;
|
||||
ggml_vk_op_f32<vk_op_push_constants>(ctx, subctx, src0, src1, nullptr, nullptr, dst, GGML_OP_SOFT_MAX_BACK, { (uint32_t)src0->ne[0], (uint32_t)ggml_nrows(src0), op_params[0], op_params[1] });
|
||||
ggml_vk_op_f32<vk_op_push_constants>(ctx, subctx, src0, src1, nullptr, nullptr, dst, GGML_OP_SOFT_MAX_BACK, { (uint32_t)src0->ne[0], (uint32_t)ggml_nrows(src0), op_params[0], op_params[1], 0.0f, 0.0f });
|
||||
}
|
||||
|
||||
static void ggml_vk_topk_moe(ggml_backend_vk_context * ctx, vk_context& subctx, ggml_cgraph * cgraph, int node_idx) {
|
||||
@@ -10513,11 +10586,11 @@ static void ggml_vk_cumsum(ggml_backend_vk_context * ctx, vk_context& subctx, co
|
||||
}
|
||||
|
||||
static void ggml_vk_argmax(ggml_backend_vk_context * ctx, vk_context& subctx, const ggml_tensor * src0, ggml_tensor * dst) {
|
||||
ggml_vk_op_f32<vk_op_push_constants>(ctx, subctx, src0, nullptr, nullptr, nullptr, dst, GGML_OP_ARGMAX, { (uint32_t)src0->ne[0], (uint32_t)src0->ne[1], 0.0f, 0.0f });
|
||||
ggml_vk_op_f32<vk_op_push_constants>(ctx, subctx, src0, nullptr, nullptr, nullptr, dst, GGML_OP_ARGMAX, { (uint32_t)src0->ne[0], (uint32_t)src0->ne[1], 0.0f, 0.0f, 0.0f, 0.0f });
|
||||
}
|
||||
|
||||
static void ggml_vk_count_equal(ggml_backend_vk_context * ctx, vk_context& subctx, const ggml_tensor * src0, const ggml_tensor * src1, ggml_tensor * dst) {
|
||||
ggml_vk_op_f32<vk_op_push_constants>(ctx, subctx, src0, src1, nullptr, nullptr, dst, GGML_OP_COUNT_EQUAL, { (uint32_t)ggml_nelements(src0), 0, 0.0f, 0.0f });
|
||||
ggml_vk_op_f32<vk_op_push_constants>(ctx, subctx, src0, src1, nullptr, nullptr, dst, GGML_OP_COUNT_EQUAL, { (uint32_t)ggml_nelements(src0), 0, 0.0f, 0.0f, 0.0f, 0.0f });
|
||||
}
|
||||
|
||||
static void ggml_vk_solve_tri(ggml_backend_vk_context * ctx, vk_context& subctx, const ggml_tensor * src0, const ggml_tensor * src1, ggml_tensor * dst) {
|
||||
@@ -10559,6 +10632,7 @@ static void ggml_vk_im2col(ggml_backend_vk_context * ctx, vk_context& subctx, co
|
||||
const uint32_t batch_offset = src1->nb[is_2D ? 3 : 2] / 4; // nb is byte offset, src is type float32
|
||||
|
||||
const uint32_t pelements = OW * KW * KH;
|
||||
const uint32_t batch = src1->ne[is_2D ? 3 : 2];
|
||||
|
||||
const ggml_backend_vk_buffer_context * d_buf_ctx = (ggml_backend_vk_buffer_context *)dst->buffer->context;
|
||||
const vk_buffer d_buf = d_buf_ctx->dev_buffer;
|
||||
@@ -10571,7 +10645,7 @@ static void ggml_vk_im2col(ggml_backend_vk_context * ctx, vk_context& subctx, co
|
||||
IC, IW, IH, OW, OH, KW, KH,
|
||||
pelements,
|
||||
IC * KH * KW,
|
||||
s0, s1, p0, p1, d0, d1,
|
||||
s0, s1, p0, p1, d0, d1, batch * IC
|
||||
});
|
||||
}
|
||||
|
||||
@@ -10776,7 +10850,7 @@ static void ggml_vk_conv_2d_dw(ggml_backend_vk_context * ctx, vk_context& subctx
|
||||
|
||||
static void ggml_vk_leaky_relu(ggml_backend_vk_context * ctx, vk_context& subctx, const ggml_tensor * src0, ggml_tensor * dst) {
|
||||
const float * op_params = (const float *)dst->op_params;
|
||||
ggml_vk_op_f32<vk_op_push_constants>(ctx, subctx, src0, nullptr, nullptr, nullptr, dst, GGML_OP_LEAKY_RELU, { (uint32_t)ggml_nelements(src0), 0, op_params[0], 0.0f });
|
||||
ggml_vk_op_f32<vk_op_push_constants>(ctx, subctx, src0, nullptr, nullptr, nullptr, dst, GGML_OP_LEAKY_RELU, { (uint32_t)ggml_nelements(src0), 0, op_params[0], 0.0f, 0.0f, 0.0f });
|
||||
}
|
||||
|
||||
#ifdef GGML_VULKAN_RUN_TESTS
|
||||
@@ -11820,15 +11894,18 @@ static bool ggml_vk_build_graph(ggml_backend_vk_context * ctx, ggml_cgraph * cgr
|
||||
}
|
||||
}
|
||||
|
||||
#define ENABLE_SYNC_LOGGING 0
|
||||
|
||||
if (need_sync) {
|
||||
#if ENABLE_SYNC_LOGGING
|
||||
std::cerr << "sync" << std::endl;
|
||||
#endif
|
||||
if (vk_enable_sync_logger) {
|
||||
std::cerr << "sync" << std::endl;
|
||||
}
|
||||
ctx->unsynced_nodes_written.clear();
|
||||
ctx->unsynced_nodes_read.clear();
|
||||
ggml_vk_sync_buffers(ctx, compute_ctx);
|
||||
|
||||
if (vk_perf_logger_enabled && vk_perf_logger_concurrent) {
|
||||
ctx->query_node_idx[ctx->query_idx] = node_idx;
|
||||
compute_ctx->s->buffer.writeTimestamp(vk::PipelineStageFlagBits::eAllCommands, ctx->query_pool, ctx->query_idx++);
|
||||
}
|
||||
}
|
||||
// Add all fused nodes to the unsynchronized lists.
|
||||
for (int32_t i = 0; i < ctx->num_additional_fused_ops + 1; ++i) {
|
||||
@@ -11845,20 +11922,20 @@ static bool ggml_vk_build_graph(ggml_backend_vk_context * ctx, ggml_cgraph * cgr
|
||||
}
|
||||
}
|
||||
}
|
||||
#if ENABLE_SYNC_LOGGING
|
||||
for (int i = 0; i < ctx->num_additional_fused_ops + 1; ++i) {
|
||||
auto *n = cgraph->nodes[node_idx + i];
|
||||
std::cerr << node_idx + i << " " << ggml_op_name(n->op) << " " << n->name;
|
||||
if (n->op == GGML_OP_GLU) {
|
||||
std::cerr << " " << ggml_glu_op_name(ggml_get_glu_op(n)) << " " << (n->src[1] ? "split" : "single") << " ";
|
||||
if (vk_enable_sync_logger) {
|
||||
for (int i = 0; i < ctx->num_additional_fused_ops + 1; ++i) {
|
||||
auto *n = cgraph->nodes[node_idx + i];
|
||||
std::cerr << node_idx + i << " " << ggml_op_name(n->op) << " " << n->name;
|
||||
if (n->op == GGML_OP_GLU) {
|
||||
std::cerr << " " << ggml_glu_op_name(ggml_get_glu_op(n)) << " " << (n->src[1] ? "split" : "single") << " ";
|
||||
}
|
||||
if (n->op == GGML_OP_ROPE) {
|
||||
const int mode = ((const int32_t *) n->op_params)[2];
|
||||
std::cerr << " rope mode: " << mode;
|
||||
}
|
||||
std::cerr << std::endl;
|
||||
}
|
||||
if (n->op == GGML_OP_ROPE) {
|
||||
const int mode = ((const int32_t *) n->op_params)[2];
|
||||
std::cerr << " rope mode: " << mode;
|
||||
}
|
||||
std::cerr << std::endl;
|
||||
}
|
||||
#endif
|
||||
|
||||
switch (node->op) {
|
||||
case GGML_OP_REPEAT:
|
||||
@@ -12019,6 +12096,9 @@ static bool ggml_vk_build_graph(ggml_backend_vk_context * ctx, ggml_cgraph * cgr
|
||||
case GGML_UNARY_OP_TRUNC:
|
||||
ggml_vk_unary(ctx, compute_ctx, src0, node);
|
||||
break;
|
||||
case GGML_UNARY_OP_XIELU:
|
||||
ggml_vk_xielu(ctx, compute_ctx, src0, node);
|
||||
break;
|
||||
default:
|
||||
return false;
|
||||
}
|
||||
@@ -12612,7 +12692,23 @@ static void ggml_backend_vk_set_tensor_async(ggml_backend_t backend, ggml_tensor
|
||||
|
||||
vk_buffer buf = buf_ctx->dev_buffer;
|
||||
|
||||
ggml_vk_buffer_write_async(transfer_ctx, buf, vk_tensor_offset(tensor) + tensor->view_offs + offset, data, size);
|
||||
auto dst_offset = vk_tensor_offset(tensor) + tensor->view_offs + offset;
|
||||
|
||||
bool ret = ggml_vk_buffer_write_async(transfer_ctx, buf, dst_offset, data, size);
|
||||
|
||||
if (!ret) {
|
||||
ggml_vk_ensure_sync_staging_buffer(ctx, size);
|
||||
ggml_vk_sync_buffers(nullptr, transfer_ctx);
|
||||
|
||||
vk::BufferCopy buffer_cpy;
|
||||
buffer_cpy.srcOffset = 0;
|
||||
buffer_cpy.dstOffset = dst_offset;
|
||||
buffer_cpy.size = size;
|
||||
|
||||
transfer_ctx->s->buffer.copyBuffer(ctx->sync_staging->buffer, buf->buffer, { buffer_cpy });
|
||||
deferred_memcpy(ctx->sync_staging->ptr, data, size, &transfer_ctx->in_memcpys);
|
||||
ggml_vk_synchronize(ctx);
|
||||
}
|
||||
}
|
||||
|
||||
static void ggml_backend_vk_get_tensor_async(ggml_backend_t backend, const ggml_tensor * tensor, void * data, size_t offset, size_t size) {
|
||||
@@ -12889,24 +12985,43 @@ static bool ggml_vk_can_fuse_topk_moe(ggml_backend_vk_context * ctx, const struc
|
||||
|
||||
const ggml_tensor * softmax;
|
||||
const ggml_tensor * weights;
|
||||
const ggml_tensor * get_rows;
|
||||
const ggml_tensor * argsort;
|
||||
|
||||
switch (mode) {
|
||||
case TOPK_MOE_EARLY_SOFTMAX_NORM:
|
||||
softmax = cgraph->nodes[node_idx + 0];
|
||||
weights = cgraph->nodes[node_idx + 9];
|
||||
get_rows = cgraph->nodes[node_idx + 4];
|
||||
argsort = cgraph->nodes[node_idx + 2];
|
||||
break;
|
||||
case TOPK_MOE_EARLY_SOFTMAX:
|
||||
softmax = cgraph->nodes[node_idx + 0];
|
||||
weights = cgraph->nodes[node_idx + 4];
|
||||
get_rows = cgraph->nodes[node_idx + 4];
|
||||
argsort = cgraph->nodes[node_idx + 2];
|
||||
break;
|
||||
case TOPK_MOE_LATE_SOFTMAX:
|
||||
softmax = cgraph->nodes[node_idx + 4];
|
||||
weights = cgraph->nodes[node_idx + 5];
|
||||
get_rows = cgraph->nodes[node_idx + 2];
|
||||
argsort = cgraph->nodes[node_idx + 0];
|
||||
break;
|
||||
default:
|
||||
return false;
|
||||
}
|
||||
|
||||
ggml_tensor * probs = get_rows->src[0];
|
||||
if (probs->op != GGML_OP_RESHAPE) {
|
||||
return false;
|
||||
}
|
||||
probs = probs->src[0];
|
||||
ggml_tensor * selection_probs = argsort->src[0];
|
||||
|
||||
if (probs != selection_probs) {
|
||||
return false;
|
||||
}
|
||||
|
||||
const float * op_params = (const float *)softmax->op_params;
|
||||
|
||||
float scale = op_params[0];
|
||||
@@ -12966,9 +13081,9 @@ static bool ggml_vk_can_fuse_rope_set_rows(ggml_backend_vk_context * ctx, const
|
||||
return false;
|
||||
}
|
||||
|
||||
// Only norm/neox shaders have the fusion code
|
||||
// Only norm/neox/mrope shaders have the fusion code
|
||||
const int mode = ((const int32_t *) rope->op_params)[2];
|
||||
if (mode != GGML_ROPE_TYPE_NORMAL && mode != GGML_ROPE_TYPE_NEOX) {
|
||||
if (mode != GGML_ROPE_TYPE_NORMAL && mode != GGML_ROPE_TYPE_NEOX && mode != GGML_ROPE_TYPE_MROPE) {
|
||||
return false;
|
||||
}
|
||||
|
||||
@@ -13138,12 +13253,16 @@ static ggml_status ggml_backend_vk_graph_compute(ggml_backend_t backend, ggml_cg
|
||||
ctx->query_pool = ctx->device->device.createQueryPool(query_create_info);
|
||||
ctx->num_queries = query_create_info.queryCount;
|
||||
ctx->query_fusion_names.resize(ctx->num_queries);
|
||||
ctx->query_fusion_node_count.resize(ctx->num_queries);
|
||||
ctx->query_nodes.resize(ctx->num_queries);
|
||||
ctx->query_node_idx.resize(ctx->num_queries);
|
||||
}
|
||||
|
||||
ctx->device->device.resetQueryPool(ctx->query_pool, 0, cgraph->n_nodes+1);
|
||||
std::fill(ctx->query_fusion_names.begin(), ctx->query_fusion_names.end(), nullptr);
|
||||
std::fill(ctx->query_fusion_node_count.begin(), ctx->query_fusion_node_count.end(), 0);
|
||||
std::fill(ctx->query_nodes.begin(), ctx->query_nodes.end(), nullptr);
|
||||
std::fill(ctx->query_node_idx.begin(), ctx->query_node_idx.end(), 0);
|
||||
|
||||
GGML_ASSERT(ctx->compute_ctx.expired());
|
||||
compute_ctx = ggml_vk_create_context(ctx, ctx->compute_cmd_pool);
|
||||
@@ -13272,9 +13391,16 @@ static ggml_status ggml_backend_vk_graph_compute(ggml_backend_t backend, ggml_cg
|
||||
} else {
|
||||
compute_ctx = ctx->compute_ctx.lock();
|
||||
}
|
||||
ctx->query_nodes[ctx->query_idx] = cgraph->nodes[i];
|
||||
ctx->query_fusion_names[ctx->query_idx] = fusion_string;
|
||||
compute_ctx->s->buffer.writeTimestamp(vk::PipelineStageFlagBits::eAllCommands, ctx->query_pool, ctx->query_idx++);
|
||||
if (!vk_perf_logger_concurrent) {
|
||||
// track a single node/fusion for the current query
|
||||
ctx->query_nodes[ctx->query_idx] = cgraph->nodes[i];
|
||||
ctx->query_fusion_names[ctx->query_idx] = fusion_string;
|
||||
compute_ctx->s->buffer.writeTimestamp(vk::PipelineStageFlagBits::eAllCommands, ctx->query_pool, ctx->query_idx++);
|
||||
} else {
|
||||
// track a fusion string and number of fused ops for the current node_idx
|
||||
ctx->query_fusion_names[i] = fusion_string;
|
||||
ctx->query_fusion_node_count[i] = ctx->num_additional_fused_ops;
|
||||
}
|
||||
}
|
||||
|
||||
if (enqueued) {
|
||||
@@ -13316,12 +13442,32 @@ static ggml_status ggml_backend_vk_graph_compute(ggml_backend_t backend, ggml_cg
|
||||
// Get the results and pass them to the logger
|
||||
std::vector<uint64_t> timestamps(cgraph->n_nodes + 1);
|
||||
VK_CHECK(ctx->device->device.getQueryPoolResults(ctx->query_pool, 0, ctx->query_idx, (cgraph->n_nodes + 1)*sizeof(uint64_t), timestamps.data(), sizeof(uint64_t), vk::QueryResultFlagBits::e64 | vk::QueryResultFlagBits::eWait), "get timestamp results");
|
||||
for (int i = 1; i < ctx->query_idx; i++) {
|
||||
auto node = ctx->query_nodes[i];
|
||||
auto name = ctx->query_fusion_names[i];
|
||||
ctx->perf_logger->log_timing(node, name, uint64_t((timestamps[i] - timestamps[i-1]) * ctx->device->properties.limits.timestampPeriod));
|
||||
if (!vk_perf_logger_concurrent) {
|
||||
// Log each op separately
|
||||
for (int i = 1; i < ctx->query_idx; i++) {
|
||||
auto node = ctx->query_nodes[i];
|
||||
auto name = ctx->query_fusion_names[i];
|
||||
ctx->perf_logger->log_timing(node, name, uint64_t((timestamps[i] - timestamps[i-1]) * ctx->device->properties.limits.timestampPeriod));
|
||||
}
|
||||
} else {
|
||||
// Log each group of nodes
|
||||
int prev_node_idx = 0;
|
||||
for (int i = 1; i < ctx->query_idx; i++) {
|
||||
auto cur_node_idx = ctx->query_node_idx[i];
|
||||
std::vector<ggml_tensor *> nodes;
|
||||
std::vector<const char *> names;
|
||||
for (int node_idx = prev_node_idx; node_idx < cur_node_idx; ++node_idx) {
|
||||
if (ggml_op_is_empty(cgraph->nodes[node_idx]->op)) {
|
||||
continue;
|
||||
}
|
||||
nodes.push_back(cgraph->nodes[node_idx]);
|
||||
names.push_back(ctx->query_fusion_names[node_idx]);
|
||||
node_idx += ctx->query_fusion_node_count[node_idx];
|
||||
}
|
||||
prev_node_idx = cur_node_idx;
|
||||
ctx->perf_logger->log_timing(nodes, names, uint64_t((timestamps[i] - timestamps[i-1]) * ctx->device->properties.limits.timestampPeriod));
|
||||
}
|
||||
}
|
||||
|
||||
ctx->perf_logger->print_timings();
|
||||
}
|
||||
|
||||
@@ -13440,7 +13586,8 @@ static void ggml_vk_graph_optimize(ggml_backend_t backend, struct ggml_cgraph *
|
||||
!(j == c+1 && c == current_set.back() && graph->nodes[c]->op == GGML_OP_RMS_NORM && graph->nodes[j]->op == GGML_OP_MUL) &&
|
||||
!(j == c+1 && c == current_set.back() && graph->nodes[c]->op == GGML_OP_MUL_MAT && graph->nodes[j]->op == GGML_OP_ADD) &&
|
||||
!(j == c+1 && c == current_set.back() && graph->nodes[c]->op == GGML_OP_MUL_MAT_ID && graph->nodes[j]->op == GGML_OP_ADD_ID) &&
|
||||
!(j == c+1 && c == current_set.back() && graph->nodes[c]->op == GGML_OP_MUL_MAT_ID && graph->nodes[j]->op == GGML_OP_MUL)) {
|
||||
!(j == c+1 && c == current_set.back() && graph->nodes[c]->op == GGML_OP_MUL_MAT_ID && graph->nodes[j]->op == GGML_OP_MUL) &&
|
||||
!(j == c+1 && c == current_set.back() && graph->nodes[c]->op == GGML_OP_ADD && graph->nodes[j]->op == GGML_OP_ADD)) {
|
||||
ok = false;
|
||||
break;
|
||||
}
|
||||
@@ -13568,11 +13715,58 @@ static void ggml_vk_graph_optimize(ggml_backend_t backend, struct ggml_cgraph *
|
||||
}
|
||||
}
|
||||
|
||||
static void ggml_backend_vk_event_record(ggml_backend_t backend, ggml_backend_event_t event) {
|
||||
ggml_backend_vk_context * ctx = (ggml_backend_vk_context *)backend->context;
|
||||
vk_event *vkev = (vk_event *)event->context;
|
||||
|
||||
vk_context transfer_ctx;
|
||||
|
||||
if (ctx->transfer_ctx.expired()) {
|
||||
// Initialize new transfer context
|
||||
transfer_ctx = ggml_vk_create_context(ctx, ctx->compute_cmd_pool);
|
||||
ctx->transfer_ctx = transfer_ctx;
|
||||
ggml_vk_ctx_begin(ctx->device, transfer_ctx);
|
||||
} else {
|
||||
transfer_ctx = ctx->transfer_ctx.lock();
|
||||
}
|
||||
|
||||
// the backend interface doesn't have an explicit reset, so reset it here
|
||||
// before we record the command to set it
|
||||
ctx->device->device.resetEvent(vkev->event);
|
||||
ctx->device->device.resetFences({ vkev->fence });
|
||||
|
||||
ggml_vk_set_event(transfer_ctx, vkev->event);
|
||||
|
||||
ggml_vk_ctx_end(transfer_ctx);
|
||||
|
||||
ggml_vk_submit(transfer_ctx, {vkev->fence});
|
||||
ctx->submit_pending = true;
|
||||
ctx->transfer_ctx.reset();
|
||||
}
|
||||
|
||||
static void ggml_backend_vk_event_wait(ggml_backend_t backend, ggml_backend_event_t event) {
|
||||
ggml_backend_vk_context * ctx = (ggml_backend_vk_context *)backend->context;
|
||||
vk_event *vkev = (vk_event *)event->context;
|
||||
|
||||
vk_context transfer_ctx;
|
||||
|
||||
if (ctx->transfer_ctx.expired()) {
|
||||
// Initialize new transfer context
|
||||
transfer_ctx = ggml_vk_create_context(ctx, ctx->compute_cmd_pool);
|
||||
ctx->transfer_ctx = transfer_ctx;
|
||||
ggml_vk_ctx_begin(ctx->device, transfer_ctx);
|
||||
} else {
|
||||
transfer_ctx = ctx->transfer_ctx.lock();
|
||||
}
|
||||
|
||||
ggml_vk_wait_events(transfer_ctx, {vkev->event});
|
||||
}
|
||||
|
||||
// TODO: enable async and synchronize
|
||||
static ggml_backend_i ggml_backend_vk_interface = {
|
||||
/* .get_name = */ ggml_backend_vk_name,
|
||||
/* .free = */ ggml_backend_vk_free,
|
||||
/* .set_tensor_async = */ NULL, // ggml_backend_vk_set_tensor_async,
|
||||
/* .set_tensor_async = */ ggml_backend_vk_set_tensor_async,
|
||||
/* .get_tensor_async = */ ggml_backend_vk_get_tensor_async,
|
||||
/* .cpy_tensor_async = */ NULL, // ggml_backend_vk_cpy_tensor_async,
|
||||
/* .synchronize = */ ggml_backend_vk_synchronize,
|
||||
@@ -13581,8 +13775,8 @@ static ggml_backend_i ggml_backend_vk_interface = {
|
||||
/* .graph_plan_update = */ NULL,
|
||||
/* .graph_plan_compute = */ NULL,
|
||||
/* .graph_compute = */ ggml_backend_vk_graph_compute,
|
||||
/* .event_record = */ NULL,
|
||||
/* .event_wait = */ NULL,
|
||||
/* .event_record = */ ggml_backend_vk_event_record,
|
||||
/* .event_wait = */ ggml_backend_vk_event_wait,
|
||||
/* .graph_optimize = */ ggml_vk_graph_optimize,
|
||||
};
|
||||
|
||||
@@ -13757,10 +13951,10 @@ static void ggml_backend_vk_device_get_props(ggml_backend_dev_t dev, struct ggml
|
||||
props->device_id = ctx->pci_bus_id.empty() ? nullptr : ctx->pci_bus_id.c_str();
|
||||
ggml_backend_vk_device_get_memory(dev, &props->memory_free, &props->memory_total);
|
||||
props->caps = {
|
||||
/* .async = */ false,
|
||||
/* .async = */ true,
|
||||
/* .host_buffer = */ true,
|
||||
/* .buffer_from_host_ptr = */ false,
|
||||
/* .events = */ false,
|
||||
/* .events = */ true,
|
||||
};
|
||||
}
|
||||
|
||||
@@ -13780,6 +13974,7 @@ static bool ggml_backend_vk_device_supports_op(ggml_backend_dev_t dev, const ggm
|
||||
case GGML_UNARY_OP_GELU_QUICK:
|
||||
case GGML_UNARY_OP_SILU:
|
||||
case GGML_UNARY_OP_RELU:
|
||||
case GGML_UNARY_OP_XIELU:
|
||||
case GGML_UNARY_OP_NEG:
|
||||
case GGML_UNARY_OP_TANH:
|
||||
case GGML_UNARY_OP_SIGMOID:
|
||||
@@ -14291,6 +14486,46 @@ static bool ggml_backend_vk_device_offload_op(ggml_backend_dev_t dev, const ggml
|
||||
UNUSED(dev);
|
||||
}
|
||||
|
||||
static ggml_backend_event_t ggml_backend_vk_device_event_new(ggml_backend_dev_t dev) {
|
||||
ggml_backend_vk_device_context * ctx = (ggml_backend_vk_device_context *)dev->context;
|
||||
auto device = ggml_vk_get_device(ctx->device);
|
||||
|
||||
vk_event *vkev = new vk_event;
|
||||
if (!vkev) {
|
||||
return nullptr;
|
||||
}
|
||||
|
||||
// The event/fence is expected to initially be in the signaled state.
|
||||
vkev->event = device->device.createEvent({});
|
||||
vkev->fence = device->device.createFence({vk::FenceCreateFlagBits::eSignaled});
|
||||
device->device.setEvent(vkev->event);
|
||||
|
||||
return new ggml_backend_event {
|
||||
/* .device = */ dev,
|
||||
/* .context = */ vkev,
|
||||
};
|
||||
}
|
||||
|
||||
static void ggml_backend_vk_device_event_free(ggml_backend_dev_t dev, ggml_backend_event_t event) {
|
||||
ggml_backend_vk_device_context * ctx = (ggml_backend_vk_device_context *)dev->context;
|
||||
auto device = ggml_vk_get_device(ctx->device);
|
||||
|
||||
vk_event *vkev = (vk_event *)event->context;
|
||||
|
||||
device->device.destroyFence(vkev->fence);
|
||||
device->device.destroyEvent(vkev->event);
|
||||
delete vkev;
|
||||
delete event;
|
||||
}
|
||||
|
||||
static void ggml_backend_vk_device_event_synchronize(ggml_backend_dev_t dev, ggml_backend_event_t event) {
|
||||
ggml_backend_vk_device_context * ctx = (ggml_backend_vk_device_context *)dev->context;
|
||||
auto device = ggml_vk_get_device(ctx->device);
|
||||
vk_event *vkev = (vk_event *)event->context;
|
||||
|
||||
VK_CHECK(device->device.waitForFences({ vkev->fence }, true, UINT64_MAX), "event_synchronize");
|
||||
}
|
||||
|
||||
static const struct ggml_backend_device_i ggml_backend_vk_device_i = {
|
||||
/* .get_name = */ ggml_backend_vk_device_get_name,
|
||||
/* .get_description = */ ggml_backend_vk_device_get_description,
|
||||
@@ -14304,9 +14539,9 @@ static const struct ggml_backend_device_i ggml_backend_vk_device_i = {
|
||||
/* .supports_op = */ ggml_backend_vk_device_supports_op,
|
||||
/* .supports_buft = */ ggml_backend_vk_device_supports_buft,
|
||||
/* .offload_op = */ ggml_backend_vk_device_offload_op,
|
||||
/* .event_new = */ NULL,
|
||||
/* .event_free = */ NULL,
|
||||
/* .event_synchronize = */ NULL,
|
||||
/* .event_new = */ ggml_backend_vk_device_event_new,
|
||||
/* .event_free = */ ggml_backend_vk_device_event_free,
|
||||
/* .event_synchronize = */ ggml_backend_vk_device_event_synchronize,
|
||||
};
|
||||
|
||||
static const char * ggml_backend_vk_reg_get_name(ggml_backend_reg_t reg) {
|
||||
@@ -14685,7 +14920,7 @@ static void ggml_vk_check_results_0(ggml_backend_vk_context * ctx, ggml_cgraph *
|
||||
} else if (tensor->op == GGML_OP_LOG) {
|
||||
tensor_clone = ggml_log(ggml_ctx, src_clone[0]);
|
||||
} else if (tensor->op == GGML_OP_TRI) {
|
||||
tensor_clone = ggml_tri(ggml_ctx, src_clone[0], ggml_get_op_params_i32(tensor, 0));
|
||||
tensor_clone = ggml_tri(ggml_ctx, src_clone[0], (ggml_tri_type)ggml_get_op_params_i32(tensor, 0));
|
||||
} else if (tensor->op == GGML_OP_DIAG) {
|
||||
tensor_clone = ggml_diag(ggml_ctx, src_clone[0]);
|
||||
} else if (tensor->op == GGML_OP_CLAMP) {
|
||||
@@ -14773,6 +15008,13 @@ static void ggml_vk_check_results_0(ggml_backend_vk_context * ctx, ggml_cgraph *
|
||||
case GGML_UNARY_OP_RELU:
|
||||
tensor_clone = ggml_relu(ggml_ctx, src_clone[0]);
|
||||
break;
|
||||
case GGML_UNARY_OP_XIELU:
|
||||
tensor_clone = ggml_xielu(ggml_ctx, src_clone[0], 0, 0, 0, 0);
|
||||
ggml_set_op_params_f32(tensor_clone, 1, ggml_get_op_params_f32(tensor, 1));
|
||||
ggml_set_op_params_f32(tensor_clone, 2, ggml_get_op_params_f32(tensor, 2));
|
||||
ggml_set_op_params_f32(tensor_clone, 3, ggml_get_op_params_f32(tensor, 3));
|
||||
ggml_set_op_params_f32(tensor_clone, 4, ggml_get_op_params_f32(tensor, 4));
|
||||
break;
|
||||
case GGML_UNARY_OP_NEG:
|
||||
tensor_clone = ggml_neg(ggml_ctx, src_clone[0]);
|
||||
break;
|
||||
|
||||
@@ -6,4 +6,6 @@ layout (push_constant) uniform parameter
|
||||
uint KY;
|
||||
float param1;
|
||||
float param2;
|
||||
float param3;
|
||||
float param4;
|
||||
} p;
|
||||
|
||||
@@ -19,6 +19,7 @@ layout (push_constant) uniform parameter
|
||||
int s0; int s1;
|
||||
int p0; int p1;
|
||||
int d0; int d1;
|
||||
uint batch_IC;
|
||||
} p;
|
||||
|
||||
layout(constant_id = 0) const uint BLOCK_SIZE = 32;
|
||||
@@ -34,12 +35,12 @@ layout (binding = 1) writeonly buffer D {D_TYPE data_d[];};
|
||||
layout (buffer_reference) buffer D_ptr {D_TYPE d;};
|
||||
#endif
|
||||
|
||||
void main() {
|
||||
void im2col(const uint y, const uint z) {
|
||||
const uint gidx = gl_GlobalInvocationID.x;
|
||||
|
||||
const uint oh = gl_GlobalInvocationID.y;
|
||||
const uint batch = gl_GlobalInvocationID.z / p.IC;
|
||||
const uint ic = gl_GlobalInvocationID.z % p.IC;
|
||||
const uint oh = y;
|
||||
const uint batch = z / p.IC;
|
||||
const uint ic = z % p.IC;
|
||||
|
||||
const uint src_base = ic * p.offset_delta + batch * p.batch_offset;
|
||||
const BDA_OFFSET_T dst_base = ((BDA_OFFSET_T(batch) * p.OH + oh) * p.OW) * p.CHW + BDA_OFFSET_T(ic) * (p.KW * p.KH);
|
||||
@@ -101,3 +102,15 @@ void main() {
|
||||
#endif
|
||||
}
|
||||
}
|
||||
|
||||
void main() {
|
||||
uint y = gl_GlobalInvocationID.y;
|
||||
while (y < p.OH) {
|
||||
uint z = gl_GlobalInvocationID.z;
|
||||
while (z < p.batch_IC) {
|
||||
im2col(y, z);
|
||||
z += gl_NumWorkGroups.z;
|
||||
}
|
||||
y += gl_NumWorkGroups.y;
|
||||
}
|
||||
}
|
||||
|
||||
@@ -11,36 +11,54 @@ void calc_superblock(const uint a_offset, const uint b_offset, const uint itid,
|
||||
const uint y_idx = i * QUANT_K + 16 * itid;
|
||||
const uint nibble_shift = 4 * (itid & 1);
|
||||
const uint ib32 = itid / 2; // 0..7
|
||||
|
||||
uint ibi = a_offset / QUANT_K + first_row * num_blocks_per_row + i;
|
||||
// Precompute db multiplication factors
|
||||
float db_vals[NUM_ROWS];
|
||||
[[unroll]] for (uint n = 0; n < num_rows; ++n) {
|
||||
const float d = float(data_a[ibi].d);
|
||||
const uint scale = (data_a[ibi].scales[ib32] >> nibble_shift) & 0xF;
|
||||
const float db = d * (0.5 + scale) * 0.25;
|
||||
|
||||
const uint scale_raw = data_a[ibi].scales[ib32];
|
||||
const uint scale = (scale_raw >> nibble_shift) & 0xF;
|
||||
// Merge constant calculations d * (0.5 + scale) * 0.25 = d*0.125 + d*scale*0.25
|
||||
db_vals[n] = d * (0.125f + float(scale) * 0.25f);
|
||||
ibi += num_blocks_per_row;
|
||||
}
|
||||
ibi = a_offset / QUANT_K + first_row * num_blocks_per_row + i;
|
||||
[[unroll]] for (uint n = 0; n < num_rows; ++n) {
|
||||
// Preload grid and sign data for all l values
|
||||
vec4 grid0_vals[2], grid1_vals[2];
|
||||
uint sign_vals[2], sign7_vals[2];
|
||||
[[unroll]] for (uint l = 0; l < 2; ++l) {
|
||||
const uint qs = data_a[ibi].qs[2 * itid + l];
|
||||
const uint sign = qs >> 9;
|
||||
const uint sign7 = bitCount(sign);
|
||||
const vec4 grid0 = vec4(unpack8(iq2xs_grid[qs & 511].x));
|
||||
const vec4 grid1 = vec4(unpack8(iq2xs_grid[qs & 511].y));
|
||||
|
||||
[[unroll]] for (uint j = 0; j < NUM_COLS; ++j) {
|
||||
vec4 b0 = vec4(data_b_v4[(j*p.batch_stride_b + b_offset + y_idx) / 4 + 2*l + 0]);
|
||||
vec4 b4 = vec4(data_b_v4[(j*p.batch_stride_b + b_offset + y_idx) / 4 + 2*l + 1]);
|
||||
|
||||
FLOAT_TYPE sum =
|
||||
fma(FLOAT_TYPE(b0.x), FLOAT_TYPE((sign & 1) != 0 ? -grid0.x : grid0.x),
|
||||
fma(FLOAT_TYPE(b0.y), FLOAT_TYPE((sign & 2) != 0 ? -grid0.y : grid0.y),
|
||||
fma(FLOAT_TYPE(b0.z), FLOAT_TYPE((sign & 4) != 0 ? -grid0.z : grid0.z),
|
||||
fma(FLOAT_TYPE(b0.w), FLOAT_TYPE((sign & 8) != 0 ? -grid0.w : grid0.w),
|
||||
fma(FLOAT_TYPE(b4.x), FLOAT_TYPE((sign & 16) != 0 ? -grid1.x : grid1.x),
|
||||
fma(FLOAT_TYPE(b4.y), FLOAT_TYPE((sign & 32) != 0 ? -grid1.y : grid1.y),
|
||||
fma(FLOAT_TYPE(b4.z), FLOAT_TYPE((sign & 64) != 0 ? -grid1.z : grid1.z),
|
||||
fma(FLOAT_TYPE(b4.w), FLOAT_TYPE((sign7 & 1) != 0 ? -grid1.w : grid1.w),
|
||||
FLOAT_TYPE(0.0)))))))));
|
||||
temp[j][n] = fma(db, sum, temp[j][n]);
|
||||
sign_vals[l] = qs >> 9;
|
||||
sign7_vals[l] = bitCount(sign_vals[l]);
|
||||
const uvec2 grid_data = iq2xs_grid[qs & 511];
|
||||
grid0_vals[l] = vec4(unpack8(grid_data.x));
|
||||
grid1_vals[l] = vec4(unpack8(grid_data.y));
|
||||
}
|
||||
// Preload B data for all j columns (reduce repeated index calculations)
|
||||
[[unroll]] for (uint j = 0; j < NUM_COLS; ++j) {
|
||||
FLOAT_TYPE sum = FLOAT_TYPE(0.0);
|
||||
[[unroll]] for (uint l = 0; l < 2; ++l) {
|
||||
const uint sign = sign_vals[l];
|
||||
const uint sign7 = sign7_vals[l];
|
||||
const vec4 grid0 = grid0_vals[l];
|
||||
const vec4 grid1 = grid1_vals[l];
|
||||
// Precompute indices
|
||||
const uint b_idx = (j * p.batch_stride_b + b_offset + y_idx) / 4 + 2 * l;
|
||||
const vec4 b0 = vec4(data_b_v4[b_idx + 0]);
|
||||
const vec4 b4 = vec4(data_b_v4[b_idx + 1]);
|
||||
sum +=
|
||||
fma(FLOAT_TYPE(b0.x), FLOAT_TYPE((sign & 1) != 0 ? -grid0.x : grid0.x),
|
||||
fma(FLOAT_TYPE(b0.y), FLOAT_TYPE((sign & 2) != 0 ? -grid0.y : grid0.y),
|
||||
fma(FLOAT_TYPE(b0.z), FLOAT_TYPE((sign & 4) != 0 ? -grid0.z : grid0.z),
|
||||
fma(FLOAT_TYPE(b0.w), FLOAT_TYPE((sign & 8) != 0 ? -grid0.w : grid0.w),
|
||||
fma(FLOAT_TYPE(b4.x), FLOAT_TYPE((sign & 16) != 0 ? -grid1.x : grid1.x),
|
||||
fma(FLOAT_TYPE(b4.y), FLOAT_TYPE((sign & 32) != 0 ? -grid1.y : grid1.y),
|
||||
fma(FLOAT_TYPE(b4.z), FLOAT_TYPE((sign & 64) != 0 ? -grid1.z : grid1.z),
|
||||
fma(FLOAT_TYPE(b4.w), FLOAT_TYPE((sign7 & 1) != 0 ? -grid1.w : grid1.w),
|
||||
FLOAT_TYPE(0.0)))))))));
|
||||
}
|
||||
temp[j][n] = fma(FLOAT_TYPE(db_vals[n]), sum, temp[j][n]);
|
||||
}
|
||||
ibi += num_blocks_per_row;
|
||||
}
|
||||
|
||||
@@ -49,8 +49,8 @@ void rope_norm(const uint i0, const uint i1, rope_params p) {
|
||||
uint idst = i1*ne0 + i0;
|
||||
const uint ix = rope_a_coord(i0, i01, i02, p);
|
||||
|
||||
// Fusion optimization: ROPE + VIEW + SET_ROWS..
|
||||
// The rope output is viewed as a 1D tensor and offset based on a row index in data_i.
|
||||
// Fusion optimization: ROPE + VIEW + SET_ROWS.
|
||||
// The rope output is viewed as a 1D tensor and offset based on a row index in rope_data_i.
|
||||
if (p.set_rows_stride != 0) {
|
||||
idst = i01*ne0 + i0;
|
||||
idst += rope_data_i[i02].x * p.set_rows_stride;
|
||||
@@ -91,7 +91,7 @@ void rope_neox(const uint i0, const uint i1, rope_params p) {
|
||||
uint idst = i1*ne0 + i0/2;
|
||||
const uint ix = rope_a_coord(i0/2, i01, i02, p);
|
||||
|
||||
// Fusion optimization: ROPE + VIEW + SET_ROWS..
|
||||
// Fusion optimization: ROPE + VIEW + SET_ROWS.
|
||||
// The rope output is viewed as a 1D tensor and offset based on a row index in rope_data_i.
|
||||
if (p.set_rows_stride != 0) {
|
||||
idst = i01*ne0 + i0/2;
|
||||
@@ -132,9 +132,16 @@ void rope_multi(const uint i0, const uint i1, rope_params p) {
|
||||
const uint i01 = i1 % ne1;
|
||||
const uint i02 = i1 / ne1;
|
||||
|
||||
const uint idst = i1*ne0 + i0/2;
|
||||
uint idst = i1*ne0 + i0/2;
|
||||
const uint ix = rope_a_coord(i0/2, i01, i02, p);
|
||||
|
||||
// Fusion optimization: ROPE + VIEW + SET_ROWS.
|
||||
// The rope output is viewed as a 1D tensor and offset based on a row index in rope_data_i.
|
||||
if (p.set_rows_stride != 0) {
|
||||
idst = i01*ne0 + i0/2;
|
||||
idst += rope_data_i[i02].x * p.set_rows_stride;
|
||||
}
|
||||
|
||||
if (i0 >= p.n_dims) {
|
||||
rope_data_d[idst + i0/2 + 0] = ROPE_D_TYPE(rope_data_a[ix + i0/2 + 0]);
|
||||
rope_data_d[idst + i0/2 + 1] = ROPE_D_TYPE(rope_data_a[ix + i0/2 + 1]);
|
||||
|
||||
@@ -853,6 +853,8 @@ void process_shaders() {
|
||||
string_to_spv("hardswish_f32", "hardswish.comp", {{"A_TYPE", "float"}, {"D_TYPE", "float"}});
|
||||
string_to_spv("abs_f16", "abs.comp", {{"A_TYPE", "float16_t"}, {"D_TYPE", "float16_t"}});
|
||||
string_to_spv("abs_f32", "abs.comp", {{"A_TYPE", "float"}, {"D_TYPE", "float"}});
|
||||
string_to_spv("xielu_f16", "xielu.comp", {{"A_TYPE", "float16_t"}, {"D_TYPE", "float16_t"}});
|
||||
string_to_spv("xielu_f32", "xielu.comp", {{"A_TYPE", "float"}, {"D_TYPE", "float"}});
|
||||
|
||||
string_to_spv("tri_f16", "tri.comp", {{"A_TYPE", "float16_t"}, {"D_TYPE", "float16_t"}});
|
||||
string_to_spv("tri_f32", "tri.comp", {{"A_TYPE", "float"}, {"D_TYPE", "float"}});
|
||||
@@ -925,6 +927,8 @@ void process_shaders() {
|
||||
string_to_spv("rope_multi_f32", "rope_multi.comp", {{"A_TYPE", "float"}, {"ROPE_D_TYPE", "float"}});
|
||||
string_to_spv("rope_multi_f16", "rope_multi.comp", {{"A_TYPE", "float16_t"}, {"ROPE_D_TYPE", "float16_t"}});
|
||||
string_to_spv("rope_multi_f16_rte", "rope_multi.comp", {{"A_TYPE", "float16_t"}, {"ROPE_D_TYPE", "float16_t"}, {"RTE16", "1"}});
|
||||
string_to_spv("rope_multi_f32_f16", "rope_multi.comp", {{"A_TYPE", "float"}, {"ROPE_D_TYPE", "float16_t"}});
|
||||
string_to_spv("rope_multi_f32_f16_rte", "rope_multi.comp", {{"A_TYPE", "float"}, {"ROPE_D_TYPE", "float16_t"}, {"RTE16", "1"}});
|
||||
|
||||
string_to_spv("rope_vision_f32", "rope_vision.comp", {{"A_TYPE", "float"}, {"ROPE_D_TYPE", "float"}});
|
||||
string_to_spv("rope_vision_f16", "rope_vision.comp", {{"A_TYPE", "float16_t"}, {"ROPE_D_TYPE", "float16_t"}});
|
||||
|
||||
@@ -0,0 +1,35 @@
|
||||
#version 450
|
||||
|
||||
#include "generic_head.glsl"
|
||||
#include "types.glsl"
|
||||
|
||||
#extension GL_EXT_control_flow_attributes : enable
|
||||
|
||||
layout(local_size_x = 512, local_size_y = 1, local_size_z = 1) in;
|
||||
|
||||
layout (binding = 0) readonly buffer X {A_TYPE data_a[];};
|
||||
layout (binding = 1) writeonly buffer D {D_TYPE data_d[];};
|
||||
|
||||
void main() {
|
||||
const uint i = gl_GlobalInvocationID.z * 262144 + gl_GlobalInvocationID.y * 512 + gl_GlobalInvocationID.x;
|
||||
|
||||
if (i >= p.KX) {
|
||||
return;
|
||||
}
|
||||
|
||||
float x = float(data_a[i]);
|
||||
|
||||
float alpha_n = p.param1;
|
||||
float alpha_p = p.param2;
|
||||
float beta = p.param3;
|
||||
float eps = p.param4;
|
||||
|
||||
if (x > 0.0f) {
|
||||
x = alpha_p * x * x + beta * x;
|
||||
} else {
|
||||
const float min_x_eps = min(x, eps);
|
||||
x = (exp(min_x_eps) - 1 - x) * alpha_n + beta * x;
|
||||
}
|
||||
|
||||
data_d[i] = D_TYPE(x);
|
||||
}
|
||||
@@ -181,6 +181,7 @@ class Keys:
|
||||
DIMENSION_COUNT = "{arch}.rope.dimension_count"
|
||||
DIMENSION_SECTIONS = "{arch}.rope.dimension_sections"
|
||||
FREQ_BASE = "{arch}.rope.freq_base"
|
||||
FREQ_BASE_SWA = "{arch}.rope.freq_base_swa"
|
||||
SCALING_TYPE = "{arch}.rope.scaling.type"
|
||||
SCALING_FACTOR = "{arch}.rope.scaling.factor"
|
||||
SCALING_ATTN_FACTOR = "{arch}.rope.scaling.attn_factor"
|
||||
@@ -354,6 +355,7 @@ class MODEL_ARCH(IntEnum):
|
||||
STARCODER = auto()
|
||||
REFACT = auto()
|
||||
BERT = auto()
|
||||
MODERN_BERT = auto()
|
||||
NOMIC_BERT = auto()
|
||||
NOMIC_BERT_MOE = auto()
|
||||
NEO_BERT = auto()
|
||||
@@ -747,6 +749,7 @@ MODEL_ARCH_NAMES: dict[MODEL_ARCH, str] = {
|
||||
MODEL_ARCH.STARCODER: "starcoder",
|
||||
MODEL_ARCH.REFACT: "refact",
|
||||
MODEL_ARCH.BERT: "bert",
|
||||
MODEL_ARCH.MODERN_BERT: "modern-bert",
|
||||
MODEL_ARCH.NOMIC_BERT: "nomic-bert",
|
||||
MODEL_ARCH.NOMIC_BERT_MOE: "nomic-bert-moe",
|
||||
MODEL_ARCH.NEO_BERT: "neo-bert",
|
||||
@@ -1367,6 +1370,19 @@ MODEL_TENSORS: dict[MODEL_ARCH, list[MODEL_TENSOR]] = {
|
||||
MODEL_TENSOR.CLS,
|
||||
MODEL_TENSOR.CLS_OUT,
|
||||
],
|
||||
MODEL_ARCH.MODERN_BERT: [
|
||||
MODEL_TENSOR.TOKEN_EMBD,
|
||||
MODEL_TENSOR.TOKEN_EMBD_NORM,
|
||||
MODEL_TENSOR.OUTPUT_NORM,
|
||||
MODEL_TENSOR.ATTN_NORM,
|
||||
MODEL_TENSOR.ATTN_OUT,
|
||||
MODEL_TENSOR.ATTN_QKV,
|
||||
MODEL_TENSOR.FFN_UP,
|
||||
MODEL_TENSOR.FFN_DOWN,
|
||||
MODEL_TENSOR.FFN_NORM,
|
||||
MODEL_TENSOR.CLS,
|
||||
MODEL_TENSOR.CLS_OUT,
|
||||
],
|
||||
MODEL_ARCH.NOMIC_BERT: [
|
||||
MODEL_TENSOR.TOKEN_EMBD,
|
||||
MODEL_TENSOR.TOKEN_EMBD_NORM,
|
||||
|
||||
@@ -774,8 +774,12 @@ class GGUFWriter:
|
||||
def add_shared_kv_layers(self, value: int) -> None:
|
||||
self.add_uint32(Keys.Attention.SHARED_KV_LAYERS.format(arch=self.arch), value)
|
||||
|
||||
def add_sliding_window_pattern(self, value: Sequence[bool]) -> None:
|
||||
self.add_array(Keys.Attention.SLIDING_WINDOW_PATTERN.format(arch=self.arch), value)
|
||||
def add_sliding_window_pattern(self, value: int | Sequence[bool]) -> None:
|
||||
key = Keys.Attention.SLIDING_WINDOW_PATTERN.format(arch=self.arch)
|
||||
if isinstance(value, int):
|
||||
self.add_uint32(key, value)
|
||||
else:
|
||||
self.add_array(key, value)
|
||||
|
||||
def add_dense_features_dims(self, dense:str, in_f:int, out_f:int) -> None:
|
||||
self.add_uint32(Keys.LLM.DENSE_FEAT_IN_SIZE.format(arch=self.arch, dense=dense), in_f)
|
||||
@@ -886,6 +890,9 @@ class GGUFWriter:
|
||||
def add_value_residual_mix_lora_rank(self, length: int) -> None:
|
||||
self.add_uint32(Keys.Attention.VALUE_RESIDUAL_MIX_LORA_RANK.format(arch=self.arch), length)
|
||||
|
||||
def add_rope_freq_base_swa(self, value: float) -> None:
|
||||
self.add_float32(Keys.Rope.FREQ_BASE_SWA.format(arch=self.arch), value)
|
||||
|
||||
def add_gate_lora_rank(self, length: int) -> None:
|
||||
self.add_uint32(Keys.Attention.GATE_LORA_RANK.format(arch=self.arch), length)
|
||||
|
||||
|
||||
@@ -17,6 +17,7 @@ class TensorNameMap:
|
||||
"embed_tokens", # embeddinggemma
|
||||
"tok_embeddings", # llama-pth
|
||||
"embeddings.word_embeddings", # bert nomic-bert
|
||||
"embeddings.tok_embeddings", # modern-bert
|
||||
"language_model.embedding.word_embeddings", # persimmon
|
||||
"wte", # gpt2
|
||||
"transformer.embd.wte", # phi2
|
||||
@@ -46,6 +47,7 @@ class TensorNameMap:
|
||||
MODEL_TENSOR.TOKEN_EMBD_NORM: (
|
||||
"word_embeddings_layernorm", # bloom
|
||||
"embeddings.LayerNorm", # bert
|
||||
"embeddings.norm", # modern-bert
|
||||
"emb_ln", # nomic-bert
|
||||
"transformer.norm", # openelm
|
||||
"rwkv.blocks.0.pre_ln", # rwkv
|
||||
@@ -75,6 +77,7 @@ class TensorNameMap:
|
||||
"head.out", # wavtokenizer
|
||||
"lm_head", # llama4
|
||||
"model.transformer.ff_out", # llada
|
||||
"head.decoder", # modern-bert
|
||||
),
|
||||
MODEL_TENSOR.DENSE_2_OUT: (
|
||||
"dense_2_out", # embeddinggemma
|
||||
@@ -104,6 +107,7 @@ class TensorNameMap:
|
||||
"backbone.final_layer_norm", # wavtokenizer
|
||||
"model.norm", # llama4
|
||||
"model.transformer.ln_f", # llada
|
||||
"final_norm", # modern-bert
|
||||
"model.norm", # cogvlm
|
||||
),
|
||||
|
||||
@@ -151,6 +155,7 @@ class TensorNameMap:
|
||||
"model.layers.{bid}.input_layernorm", # llama4
|
||||
"layers.{bid}.input_layernorm", # embeddinggemma
|
||||
"transformer_encoder.{bid}.attention_norm", # neobert
|
||||
"layers.{bid}.attn_norm", # modern-bert
|
||||
"model.layers.{bid}.operator_norm", # lfm2
|
||||
"model.transformer.blocks.{bid}.attn_norm", # llada
|
||||
"layers.{bid}.input_layernorm", # qwen3-embedding
|
||||
@@ -187,6 +192,7 @@ class TensorNameMap:
|
||||
"encoder.layers.{bid}.self_attention.query_key_value", # chatglm
|
||||
"transformer.layers.{bid}.attn.qkv_proj", # openelm
|
||||
"transformer_encoder.{bid}.qkv", # neobert
|
||||
"layers.{bid}.attn.Wqkv", # modern-bert
|
||||
"model.layers.{bid}.self_attn.language_expert_query_key_value", # cogvlm
|
||||
),
|
||||
|
||||
@@ -261,6 +267,7 @@ class TensorNameMap:
|
||||
"model.layers.{bid}.self_attn.linear_attn", # deci
|
||||
"layers.{bid}.attention.wo", # llama-pth
|
||||
"encoder.layer.{bid}.attention.output.dense", # bert
|
||||
"layers.{bid}.attn.Wo", # modern-bert
|
||||
"transformer.layer.{bid}.attention.out_lin", # distillbert
|
||||
"transformer.h.{bid}.attn.out_proj", # gpt-j
|
||||
"language_model.encoder.layers.{bid}.self_attention.dense", # persimmon
|
||||
@@ -344,6 +351,7 @@ class TensorNameMap:
|
||||
"layers.{bid}.post_attention_layernorm", # qwen3-embedding
|
||||
"model.layers.{bid}.feedforward_layernorm", # apertus
|
||||
"model.layers.{bid}.pre_mlp_layernorm", # kormo
|
||||
"layers.{bid}.mlp_norm" # modern-bert
|
||||
),
|
||||
|
||||
# Pre feed-forward norm
|
||||
@@ -407,6 +415,7 @@ class TensorNameMap:
|
||||
"layers.{bid}.mlp.up_proj", # embeddinggemma
|
||||
"layers.{bid}.feed_forward.w3", # llama-pth
|
||||
"encoder.layer.{bid}.intermediate.dense", # bert
|
||||
"layers.{bid}.mlp.Wi", # modern-bert
|
||||
"transformer.layer.{bid}.ffn.lin1", # distillbert
|
||||
"transformer.h.{bid}.mlp.fc_in", # gpt-j
|
||||
"transformer.h.{bid}.mlp.linear_3", # refact
|
||||
@@ -521,6 +530,7 @@ class TensorNameMap:
|
||||
"layers.{bid}.mlp.down_proj", # embeddinggemma
|
||||
"layers.{bid}.feed_forward.w2", # llama-pth
|
||||
"encoder.layer.{bid}.output.dense", # bert
|
||||
"layers.{bid}.mlp.Wo", # modern-bert
|
||||
"transformer.layer.{bid}.ffn.lin2", # distillbert
|
||||
"transformer.h.{bid}.mlp.fc_out", # gpt-j
|
||||
"language_model.encoder.layers.{bid}.mlp.dense_4h_to_h", # persimmon
|
||||
@@ -1122,6 +1132,7 @@ class TensorNameMap:
|
||||
"classifier.dense", # roberta
|
||||
"pre_classifier", # distillbert
|
||||
"dense", # neobert
|
||||
"head.dense", # modern-bert
|
||||
),
|
||||
|
||||
MODEL_TENSOR.CLS_OUT: (
|
||||
|
||||
@@ -110,7 +110,6 @@ class SafetensorRemote:
|
||||
"""
|
||||
|
||||
BASE_DOMAIN = "https://huggingface.co"
|
||||
ALIGNMENT = 8 # bytes
|
||||
|
||||
@classmethod
|
||||
def get_list_tensors_hf_model(cls, model_id: str) -> dict[str, RemoteTensor]:
|
||||
@@ -204,9 +203,6 @@ class SafetensorRemote:
|
||||
|
||||
# Calculate the data start offset
|
||||
data_start_offset = 8 + metadata_length
|
||||
alignment = SafetensorRemote.ALIGNMENT
|
||||
if data_start_offset % alignment != 0:
|
||||
data_start_offset += alignment - (data_start_offset % alignment)
|
||||
|
||||
# Check if we have enough data to read the metadata
|
||||
if len(raw_data) < 8 + metadata_length:
|
||||
@@ -298,7 +294,6 @@ class SafetensorsLocal:
|
||||
Custom parsing gives a bit more control over the memory usage.
|
||||
The official safetensors library doesn't expose file ranges.
|
||||
"""
|
||||
ALIGNMENT = 8 # bytes
|
||||
|
||||
tensors: dict[str, LocalTensor]
|
||||
|
||||
@@ -316,9 +311,6 @@ class SafetensorsLocal:
|
||||
raise ValueError(f"Failed to parse safetensors metadata as JSON: {e}")
|
||||
|
||||
data_start_offset = f.tell()
|
||||
alignment = self.ALIGNMENT
|
||||
if data_start_offset % alignment != 0:
|
||||
data_start_offset += alignment - (data_start_offset % alignment)
|
||||
|
||||
tensors: dict[str, LocalTensor] = {}
|
||||
for name, meta in metadata.items():
|
||||
|
||||
@@ -90,6 +90,7 @@ add_library(llama
|
||||
models/mamba.cpp
|
||||
models/minicpm3.cpp
|
||||
models/minimax-m2.cpp
|
||||
models/modern-bert.cpp
|
||||
models/mpt.cpp
|
||||
models/nemotron-h.cpp
|
||||
models/nemotron.cpp
|
||||
|
||||
@@ -20,6 +20,7 @@ static const std::map<llm_arch, const char *> LLM_ARCH_NAMES = {
|
||||
{ LLM_ARCH_STARCODER, "starcoder" },
|
||||
{ LLM_ARCH_REFACT, "refact" },
|
||||
{ LLM_ARCH_BERT, "bert" },
|
||||
{ LLM_ARCH_MODERN_BERT, "modern-bert" },
|
||||
{ LLM_ARCH_NOMIC_BERT, "nomic-bert" },
|
||||
{ LLM_ARCH_NOMIC_BERT_MOE, "nomic-bert-moe" },
|
||||
{ LLM_ARCH_NEO_BERT, "neo-bert" },
|
||||
@@ -204,6 +205,7 @@ static const std::map<llm_kv, const char *> LLM_KV_NAMES = {
|
||||
{ LLM_KV_ATTENTION_GATE_LORA_RANK, "%s.attention.gate_lora_rank" },
|
||||
{ LLM_KV_ATTENTION_RELATIVE_BUCKETS_COUNT, "%s.attention.relative_buckets_count" },
|
||||
{ LLM_KV_ATTENTION_SLIDING_WINDOW, "%s.attention.sliding_window" },
|
||||
{ LLM_KV_ATTENTION_SLIDING_WINDOW_PATTERN, "%s.attention.sliding_window_pattern" },
|
||||
{ LLM_KV_ATTENTION_SCALE, "%s.attention.scale" },
|
||||
{ LLM_KV_ATTENTION_OUTPUT_SCALE, "%s.attention.output_scale" },
|
||||
{ LLM_KV_ATTENTION_TEMPERATURE_LENGTH, "%s.attention.temperature_length" },
|
||||
@@ -214,6 +216,7 @@ static const std::map<llm_kv, const char *> LLM_KV_NAMES = {
|
||||
{ LLM_KV_ROPE_DIMENSION_COUNT, "%s.rope.dimension_count" },
|
||||
{ LLM_KV_ROPE_DIMENSION_SECTIONS, "%s.rope.dimension_sections" },
|
||||
{ LLM_KV_ROPE_FREQ_BASE, "%s.rope.freq_base" },
|
||||
{ LLM_KV_ROPE_FREQ_BASE_SWA, "%s.rope.freq_base_swa" },
|
||||
{ LLM_KV_ROPE_SCALE_LINEAR, "%s.rope.scale_linear" },
|
||||
{ LLM_KV_ROPE_SCALING_TYPE, "%s.rope.scaling.type" },
|
||||
{ LLM_KV_ROPE_SCALING_FACTOR, "%s.rope.scaling.factor" },
|
||||
@@ -778,6 +781,20 @@ static std::set<llm_tensor> llm_get_tensor_names(llm_arch arch) {
|
||||
LLM_TENSOR_CLS,
|
||||
LLM_TENSOR_CLS_OUT,
|
||||
};
|
||||
case LLM_ARCH_MODERN_BERT:
|
||||
return {
|
||||
LLM_TENSOR_TOKEN_EMBD,
|
||||
LLM_TENSOR_TOKEN_EMBD_NORM,
|
||||
LLM_TENSOR_OUTPUT_NORM,
|
||||
LLM_TENSOR_ATTN_NORM,
|
||||
LLM_TENSOR_ATTN_OUT,
|
||||
LLM_TENSOR_ATTN_QKV,
|
||||
LLM_TENSOR_FFN_DOWN,
|
||||
LLM_TENSOR_FFN_UP,
|
||||
LLM_TENSOR_FFN_NORM,
|
||||
LLM_TENSOR_CLS,
|
||||
LLM_TENSOR_CLS_OUT,
|
||||
};
|
||||
case LLM_ARCH_JINA_BERT_V2:
|
||||
return {
|
||||
LLM_TENSOR_TOKEN_EMBD,
|
||||
|
||||
@@ -24,6 +24,7 @@ enum llm_arch {
|
||||
LLM_ARCH_STARCODER,
|
||||
LLM_ARCH_REFACT,
|
||||
LLM_ARCH_BERT,
|
||||
LLM_ARCH_MODERN_BERT,
|
||||
LLM_ARCH_NOMIC_BERT,
|
||||
LLM_ARCH_NOMIC_BERT_MOE,
|
||||
LLM_ARCH_NEO_BERT,
|
||||
@@ -208,6 +209,7 @@ enum llm_kv {
|
||||
LLM_KV_ATTENTION_GATE_LORA_RANK,
|
||||
LLM_KV_ATTENTION_RELATIVE_BUCKETS_COUNT,
|
||||
LLM_KV_ATTENTION_SLIDING_WINDOW,
|
||||
LLM_KV_ATTENTION_SLIDING_WINDOW_PATTERN,
|
||||
LLM_KV_ATTENTION_SCALE,
|
||||
LLM_KV_ATTENTION_OUTPUT_SCALE,
|
||||
LLM_KV_ATTENTION_TEMPERATURE_LENGTH,
|
||||
@@ -218,6 +220,7 @@ enum llm_kv {
|
||||
LLM_KV_ROPE_DIMENSION_COUNT,
|
||||
LLM_KV_ROPE_DIMENSION_SECTIONS,
|
||||
LLM_KV_ROPE_FREQ_BASE,
|
||||
LLM_KV_ROPE_FREQ_BASE_SWA,
|
||||
LLM_KV_ROPE_SCALE_LINEAR,
|
||||
LLM_KV_ROPE_SCALING_TYPE,
|
||||
LLM_KV_ROPE_SCALING_FACTOR,
|
||||
|
||||
+15
-16
@@ -459,23 +459,22 @@ llama_context::llama_context(
|
||||
}
|
||||
|
||||
llama_context::~llama_context() {
|
||||
// FIXME this currently results in a use-after-free bug if the model is freed before the context
|
||||
// if (!model.hparams.no_alloc) {
|
||||
// for (size_t i = 0; i < backend_ptrs.size(); ++i) {
|
||||
// ggml_backend_t backend = backend_ptrs[i];
|
||||
// ggml_backend_buffer_type_t buft = backend_buft[i];
|
||||
if (!model.hparams.no_alloc) {
|
||||
for (size_t i = 0; i < backend_ptrs.size(); ++i) {
|
||||
ggml_backend_t backend = backend_ptrs[i];
|
||||
ggml_backend_buffer_type_t buft = backend_buft[i];
|
||||
|
||||
// const size_t size_exp = backend_buf_exp_size[i];
|
||||
// const size_t size_act = ggml_backend_sched_get_buffer_size(sched.get(), backend);
|
||||
// if (size_exp == size_act) {
|
||||
// LLAMA_LOG_DEBUG("%s: %10s compute buffer size is %8.4f MiB, matches expectation of %8.4f MiB\n",
|
||||
// __func__, ggml_backend_buft_name(buft), size_act / (1024.0*1024.0), size_exp / (1024.0*1024.0));
|
||||
// } else {
|
||||
// LLAMA_LOG_WARN("%s: %10s compute buffer size of %8.4f MiB, does not match expectation of %8.4f MiB\n",
|
||||
// __func__, ggml_backend_buft_name(buft), size_act / (1024.0*1024.0), size_exp / (1024.0*1024.0));
|
||||
// }
|
||||
// }
|
||||
// }
|
||||
const size_t size_exp = backend_buf_exp_size[i];
|
||||
const size_t size_act = ggml_backend_sched_get_buffer_size(sched.get(), backend);
|
||||
if (size_exp == size_act) {
|
||||
LLAMA_LOG_DEBUG("%s: %10s compute buffer size is %8.4f MiB, matches expectation of %8.4f MiB\n",
|
||||
__func__, ggml_backend_buft_name(buft), size_act / (1024.0*1024.0), size_exp / (1024.0*1024.0));
|
||||
} else {
|
||||
LLAMA_LOG_WARN("%s: %10s compute buffer size of %8.4f MiB, does not match expectation of %8.4f MiB\n",
|
||||
__func__, ggml_backend_buft_name(buft), size_act / (1024.0*1024.0), size_exp / (1024.0*1024.0));
|
||||
}
|
||||
}
|
||||
}
|
||||
ggml_opt_free(opt_ctx);
|
||||
}
|
||||
|
||||
|
||||
@@ -462,6 +462,29 @@ namespace GGUFMeta {
|
||||
return get_key_or_arr(llm_kv(kid), result, n, required);
|
||||
}
|
||||
|
||||
bool llama_model_loader::get_key_or_arr(enum llm_kv kid, uint32_t & result, bool required) {
|
||||
const std::string key = llm_kv(kid);
|
||||
|
||||
const int id = gguf_find_key(meta.get(), key.c_str());
|
||||
|
||||
if (id < 0) {
|
||||
if (required) {
|
||||
throw std::runtime_error(format("key not found in model: %s", key.c_str()));
|
||||
}
|
||||
return false;
|
||||
}
|
||||
|
||||
// throw and error if type is an array
|
||||
if (gguf_get_kv_type(meta.get(), id) == GGUF_TYPE_ARRAY) {
|
||||
if (required) {
|
||||
throw std::runtime_error(format("expected scalar, found array for key: %s", key.c_str()));
|
||||
}
|
||||
return false;
|
||||
}
|
||||
|
||||
return get_key(key, result, required);
|
||||
}
|
||||
|
||||
// TODO: this is not very clever - figure out something better
|
||||
template bool llama_model_loader::get_key_or_arr<std::array<int, 4>>(enum llm_kv kid, std::array<int, 4> & result, uint32_t n, bool required);
|
||||
template bool llama_model_loader::get_key_or_arr<std::array<uint32_t, 512>>(enum llm_kv kid, std::array<uint32_t, 512> & result, uint32_t n, bool required);
|
||||
@@ -1086,10 +1109,10 @@ bool llama_model_loader::load_all_data(
|
||||
} else {
|
||||
// If upload_backend is valid load the tensor in chunks to pinned memory and upload the buffers asynchronously to the GPU.
|
||||
if (upload_backend) {
|
||||
auto offset = (off_t) weight->offs;
|
||||
size_t offset = weight->offs;
|
||||
alignment = file->read_alignment();
|
||||
off_t aligned_offset = offset & ~(alignment - 1);
|
||||
off_t offset_from_alignment = offset - aligned_offset;
|
||||
size_t aligned_offset = offset & ~(alignment - 1);
|
||||
size_t offset_from_alignment = offset - aligned_offset;
|
||||
file->seek(aligned_offset, SEEK_SET);
|
||||
|
||||
// Calculate aligned read boundaries
|
||||
|
||||
@@ -131,6 +131,8 @@ struct llama_model_loader {
|
||||
template<typename T>
|
||||
bool get_key_or_arr(enum llm_kv kid, T & result, uint32_t n, bool required = true);
|
||||
|
||||
bool get_key_or_arr(enum llm_kv kid, uint32_t & result, bool required = true);
|
||||
|
||||
std::string get_arch_name() const;
|
||||
|
||||
enum llm_arch get_arch() const;
|
||||
|
||||
+71
-3
@@ -31,12 +31,14 @@ const char * llm_type_name(llm_type type) {
|
||||
case LLM_TYPE_17M: return "17M";
|
||||
case LLM_TYPE_22M: return "22M";
|
||||
case LLM_TYPE_33M: return "33M";
|
||||
case LLM_TYPE_47M: return "47M";
|
||||
case LLM_TYPE_60M: return "60M";
|
||||
case LLM_TYPE_70M: return "70M";
|
||||
case LLM_TYPE_80M: return "80M";
|
||||
case LLM_TYPE_109M: return "109M";
|
||||
case LLM_TYPE_137M: return "137M";
|
||||
case LLM_TYPE_140M: return "140M";
|
||||
case LLM_TYPE_149M: return "149M";
|
||||
case LLM_TYPE_160M: return "160M";
|
||||
case LLM_TYPE_190M: return "190M";
|
||||
case LLM_TYPE_220M: return "220M";
|
||||
@@ -46,6 +48,7 @@ const char * llm_type_name(llm_type type) {
|
||||
case LLM_TYPE_335M: return "335M";
|
||||
case LLM_TYPE_350M: return "350M";
|
||||
case LLM_TYPE_360M: return "360M";
|
||||
case LLM_TYPE_395M: return "395M";
|
||||
case LLM_TYPE_410M: return "410M";
|
||||
case LLM_TYPE_450M: return "450M";
|
||||
case LLM_TYPE_475M: return "475M";
|
||||
@@ -875,6 +878,34 @@ void llama_model::load_hparams(llama_model_loader & ml) {
|
||||
default: type = LLM_TYPE_UNKNOWN;
|
||||
}
|
||||
} break;
|
||||
case LLM_ARCH_MODERN_BERT:
|
||||
{
|
||||
const bool found_swa = ml.get_key(LLM_KV_ATTENTION_SLIDING_WINDOW, hparams.n_swa, false);
|
||||
if (found_swa && hparams.n_swa > 0) {
|
||||
uint32_t swa_period = 3;
|
||||
hparams.swa_type = LLAMA_SWA_TYPE_SYMMETRIC;
|
||||
|
||||
ml.get_key(LLM_KV_ROPE_FREQ_BASE_SWA, hparams.rope_freq_base_train_swa);
|
||||
ml.get_key_or_arr(LLM_KV_ATTENTION_SLIDING_WINDOW_PATTERN, swa_period, false);
|
||||
hparams.set_swa_pattern(swa_period);
|
||||
} else {
|
||||
hparams.swa_type = LLAMA_SWA_TYPE_NONE;
|
||||
}
|
||||
|
||||
ml.get_key(LLM_KV_ATTENTION_LAYERNORM_EPS, hparams.f_norm_eps);
|
||||
ml.get_key(LLM_KV_ATTENTION_CAUSAL, hparams.causal_attn);
|
||||
ml.get_key(LLM_KV_POOLING_TYPE, hparams.pooling_type, false);
|
||||
|
||||
switch (hparams.n_layer) {
|
||||
case 12:
|
||||
type = LLM_TYPE_47M; break; // granite-embedding-small
|
||||
case 22:
|
||||
type = LLM_TYPE_149M; break; // modern-bert-base
|
||||
case 28:
|
||||
type = LLM_TYPE_395M; break; // modern-bert-large
|
||||
default: type = LLM_TYPE_UNKNOWN;
|
||||
}
|
||||
} break;
|
||||
case LLM_ARCH_JINA_BERT_V2:
|
||||
{
|
||||
ml.get_key(LLM_KV_ATTENTION_LAYERNORM_EPS, hparams.f_norm_eps);
|
||||
@@ -3155,6 +3186,37 @@ bool llama_model::load_tensors(llama_model_loader & ml) {
|
||||
layer.layer_out_norm_b = create_tensor(tn(LLM_TENSOR_LAYER_OUT_NORM, "bias", i), {n_embd}, 0);
|
||||
}
|
||||
} break;
|
||||
case LLM_ARCH_MODERN_BERT:
|
||||
{
|
||||
tok_embd = create_tensor(tn(LLM_TENSOR_TOKEN_EMBD, "weight"), {n_embd, n_vocab}, 0);
|
||||
tok_norm = create_tensor(tn(LLM_TENSOR_TOKEN_EMBD_NORM, "weight"), {n_embd}, 0);
|
||||
|
||||
output_norm = create_tensor(tn(LLM_TENSOR_OUTPUT_NORM, "weight"), {n_embd}, 0);
|
||||
|
||||
for(int i = 0; i < n_layer; ++i) {
|
||||
auto& layer = layers[i];
|
||||
|
||||
if ( i != 0 ) {
|
||||
layer.attn_norm = create_tensor(tn(LLM_TENSOR_ATTN_NORM, "weight", i), {n_embd}, 0);
|
||||
} else{
|
||||
// layer 0 uses identity
|
||||
layer.attn_norm = create_tensor(tn(LLM_TENSOR_ATTN_NORM, "weight", i), {n_embd}, TENSOR_NOT_REQUIRED);
|
||||
}
|
||||
|
||||
|
||||
layer.wqkv = create_tensor(tn(LLM_TENSOR_ATTN_QKV, "weight", i), {n_embd, 3 * n_embd }, 0);
|
||||
layer.wo = create_tensor(tn(LLM_TENSOR_ATTN_OUT, "weight", i), {n_embd, n_embd}, 0);
|
||||
|
||||
layer.ffn_up = create_tensor(tn(LLM_TENSOR_FFN_UP, "weight", i), {n_embd, 2 * n_ff}, 0);
|
||||
layer.ffn_down = create_tensor(tn(LLM_TENSOR_FFN_DOWN, "weight", i), {n_ff, n_embd}, 0);
|
||||
layer.ffn_norm = create_tensor(tn(LLM_TENSOR_FFN_NORM, "weight", i), {n_embd}, 0);
|
||||
}
|
||||
|
||||
cls = create_tensor(tn(LLM_TENSOR_CLS, "weight"), {n_embd, n_embd}, TENSOR_NOT_REQUIRED);
|
||||
cls_out = create_tensor(tn(LLM_TENSOR_CLS_OUT, "weight"), {n_embd, hparams.n_cls_out}, TENSOR_NOT_REQUIRED);
|
||||
cls_out_b = create_tensor(tn(LLM_TENSOR_CLS_OUT, "bias"), {hparams.n_cls_out}, TENSOR_NOT_REQUIRED);
|
||||
|
||||
} break;
|
||||
case LLM_ARCH_NEO_BERT:
|
||||
{
|
||||
tok_embd = create_tensor(tn(LLM_TENSOR_TOKEN_EMBD, "weight"), {n_embd, n_vocab}, 0);
|
||||
@@ -5181,9 +5243,6 @@ bool llama_model::load_tensors(llama_model_loader & ml) {
|
||||
const int64_t n_group = hparams.ssm_n_group;
|
||||
const int64_t d_in_proj = 2*d_inner + 2*n_group*d_state + n_ssm_head;
|
||||
|
||||
const int64_t n_ff_exp = hparams.n_ff_exp ? hparams.n_ff_exp : n_ff / n_expert_used;
|
||||
const int64_t n_ff_shexp = hparams.n_ff_shexp;
|
||||
|
||||
// embeddings
|
||||
tok_embd = create_tensor(tn(LLM_TENSOR_TOKEN_EMBD, "weight"), {n_embd, n_vocab}, 0);
|
||||
|
||||
@@ -5235,6 +5294,9 @@ bool llama_model::load_tensors(llama_model_loader & ml) {
|
||||
layer.bo = create_tensor(tn(LLM_TENSOR_ATTN_OUT, "bias", i), {n_embd}, TENSOR_NOT_REQUIRED);
|
||||
} else {
|
||||
if (n_expert != 0) {
|
||||
const int64_t n_ff_exp = hparams.n_ff_exp ? hparams.n_ff_exp : n_ff / n_expert_used;
|
||||
const int64_t n_ff_shexp = hparams.n_ff_shexp;
|
||||
|
||||
layer.ffn_gate_inp = create_tensor(tn(LLM_TENSOR_FFN_GATE_INP, "weight", i), { n_embd, n_expert}, 0);
|
||||
layer.ffn_exp_probs_b = create_tensor(tn(LLM_TENSOR_FFN_EXP_PROBS_B, "bias", i), {n_expert }, 0);
|
||||
|
||||
@@ -7089,6 +7151,7 @@ llama_memory_i * llama_model::create_memory(const llama_memory_params & params,
|
||||
case LLM_ARCH_NOMIC_BERT_MOE:
|
||||
case LLM_ARCH_NEO_BERT:
|
||||
case LLM_ARCH_WAVTOKENIZER_DEC:
|
||||
case LLM_ARCH_MODERN_BERT:
|
||||
case LLM_ARCH_GEMMA_EMBEDDING:
|
||||
case LLM_ARCH_DREAM:
|
||||
case LLM_ARCH_LLADA:
|
||||
@@ -7248,6 +7311,10 @@ ggml_cgraph * llama_model::build_graph(const llm_graph_params & params) const {
|
||||
{
|
||||
llm = std::make_unique<llm_build_bert>(*this, params);
|
||||
} break;
|
||||
case LLM_ARCH_MODERN_BERT:
|
||||
{
|
||||
llm = std::make_unique<llm_build_modern_bert<true>>(*this, params);
|
||||
} break;
|
||||
case LLM_ARCH_NEO_BERT:
|
||||
{
|
||||
llm = std::make_unique<llm_build_neo_bert>(*this, params);
|
||||
@@ -7816,6 +7883,7 @@ llama_rope_type llama_model_rope_type(const llama_model * model) {
|
||||
case LLM_ARCH_DBRX:
|
||||
case LLM_ARCH_BERT:
|
||||
case LLM_ARCH_JINA_BERT_V3:
|
||||
case LLM_ARCH_MODERN_BERT:
|
||||
case LLM_ARCH_NOMIC_BERT:
|
||||
case LLM_ARCH_NOMIC_BERT_MOE:
|
||||
case LLM_ARCH_STABLELM:
|
||||
|
||||
@@ -24,12 +24,14 @@ enum llm_type {
|
||||
LLM_TYPE_17M,
|
||||
LLM_TYPE_22M,
|
||||
LLM_TYPE_33M,
|
||||
LLM_TYPE_47M,
|
||||
LLM_TYPE_60M,
|
||||
LLM_TYPE_70M,
|
||||
LLM_TYPE_80M,
|
||||
LLM_TYPE_109M,
|
||||
LLM_TYPE_137M,
|
||||
LLM_TYPE_140M,
|
||||
LLM_TYPE_149M,
|
||||
LLM_TYPE_160M,
|
||||
LLM_TYPE_190M,
|
||||
LLM_TYPE_220M,
|
||||
@@ -39,6 +41,7 @@ enum llm_type {
|
||||
LLM_TYPE_335M,
|
||||
LLM_TYPE_350M,
|
||||
LLM_TYPE_360M,
|
||||
LLM_TYPE_395M,
|
||||
LLM_TYPE_410M,
|
||||
LLM_TYPE_450M,
|
||||
LLM_TYPE_475M,
|
||||
|
||||
+9
-1
@@ -1878,7 +1878,8 @@ void llama_vocab::impl::load(llama_model_loader & ml, const LLM_KV & kv) {
|
||||
tokenizer_pre == "jina-v2-es" ||
|
||||
tokenizer_pre == "jina-v2-de" ||
|
||||
tokenizer_pre == "a.x-4.0" ||
|
||||
tokenizer_pre == "mellum") {
|
||||
tokenizer_pre == "mellum" ||
|
||||
tokenizer_pre == "modern-bert" ) {
|
||||
pre_type = LLAMA_VOCAB_PRE_TYPE_GPT2;
|
||||
} else if (
|
||||
tokenizer_pre == "jina-v1-en" ||
|
||||
@@ -2528,6 +2529,13 @@ void llama_vocab::impl::load(llama_model_loader & ml, const LLM_KV & kv) {
|
||||
for (const auto * token : {"<unk>", "<s>", "<|endoftext|>"}) {
|
||||
_set_token_attr(token, LLAMA_TOKEN_ATTR_RSTRIP, false);
|
||||
}
|
||||
} else if (_contains_any(model_name, {"modern-bert"})) {
|
||||
if (token_to_id.count("[MASK]") == 0 ) {
|
||||
LLAMA_LOG_WARN("%s: Mask token missing in vocab!\n", __func__);
|
||||
}
|
||||
else {
|
||||
_set_token_attr("[MASK]", LLAMA_TOKEN_ATTR_LSTRIP, true);
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
@@ -327,6 +327,11 @@ struct llm_build_mistral3 : public llm_graph_context {
|
||||
llm_build_mistral3(const llama_model & model, const llm_graph_params & params);
|
||||
};
|
||||
|
||||
template <bool iswa>
|
||||
struct llm_build_modern_bert : public llm_graph_context {
|
||||
llm_build_modern_bert(const llama_model & model, const llm_graph_params & params);
|
||||
};
|
||||
|
||||
struct llm_build_mpt : public llm_graph_context {
|
||||
llm_build_mpt(const llama_model & model, const llm_graph_params & params);
|
||||
};
|
||||
|
||||
@@ -0,0 +1,126 @@
|
||||
#include "models.h"
|
||||
|
||||
template <bool iswa>
|
||||
llm_build_modern_bert<iswa>::llm_build_modern_bert(const llama_model & model, const llm_graph_params & params) : llm_graph_context(params) {
|
||||
const int64_t n_embd_head = hparams.n_embd_head_v;
|
||||
const int64_t n_embd_gqa = hparams.n_embd_v_gqa();
|
||||
|
||||
GGML_ASSERT(n_embd_head == hparams.n_embd_head_k);
|
||||
|
||||
ggml_tensor * cur;
|
||||
ggml_tensor * inpL;
|
||||
ggml_tensor * inp_pos = build_inp_pos();
|
||||
|
||||
// construct input embeddings (token, type, position)
|
||||
inpL = build_inp_embd(model.tok_embd);
|
||||
cb(inpL, "inp_embd", -1);
|
||||
|
||||
// embed layer norm
|
||||
inpL = build_norm(inpL, model.tok_norm, nullptr, LLM_NORM, -1);
|
||||
cb(inpL, "inp_norm", -1);
|
||||
|
||||
ggml_tensor * inp_out_ids = build_inp_out_ids();
|
||||
|
||||
auto * inp_attn = build_attn_inp_no_cache();
|
||||
|
||||
for (int il = 0; il < n_layer; ++il) {
|
||||
float freq_base_l = 0.0f;
|
||||
|
||||
if constexpr (iswa) {
|
||||
freq_base_l = model.get_rope_freq_base(cparams, il);
|
||||
} else {
|
||||
freq_base_l = freq_base;
|
||||
}
|
||||
|
||||
cur = inpL;
|
||||
|
||||
// attention layer norm
|
||||
if (model.layers[il].attn_norm) {
|
||||
cur = build_norm(inpL,
|
||||
model.layers[il].attn_norm, NULL,
|
||||
LLM_NORM, il);
|
||||
cb(cur, "attn_norm", il);
|
||||
}
|
||||
|
||||
// self attention
|
||||
cur = build_lora_mm(model.layers[il].wqkv, cur);
|
||||
cb(cur, "wqkv", il);
|
||||
|
||||
const size_t type_size = ggml_type_size(cur->type);
|
||||
|
||||
ggml_tensor * Qcur = ggml_view_3d(ctx0, cur, n_embd_head, n_head, n_tokens, n_embd_head*type_size, cur->nb[1], 0*type_size*(n_embd));
|
||||
ggml_tensor * Kcur = ggml_view_3d(ctx0, cur, n_embd_head, n_head_kv, n_tokens, n_embd_head*type_size, cur->nb[1], 1*type_size*(n_embd));
|
||||
ggml_tensor * Vcur = ggml_view_3d(ctx0, cur, n_embd_head, n_head_kv, n_tokens, n_embd_head*type_size, cur->nb[1], 1*type_size*(n_embd + n_embd_gqa));
|
||||
|
||||
// RoPE
|
||||
Qcur = ggml_rope_ext(
|
||||
ctx0, Qcur, inp_pos, nullptr,
|
||||
n_rot, rope_type, n_ctx_orig, freq_base_l, freq_scale,
|
||||
ext_factor, attn_factor, beta_fast, beta_slow
|
||||
);
|
||||
|
||||
Kcur = ggml_rope_ext(
|
||||
ctx0, Kcur, inp_pos, nullptr,
|
||||
n_rot, rope_type, n_ctx_orig, freq_base_l, freq_scale,
|
||||
ext_factor, attn_factor, beta_fast, beta_slow
|
||||
);
|
||||
|
||||
cb(Qcur, "Qcur", il);
|
||||
cb(Kcur, "Kcur", il);
|
||||
cb(Vcur, "Vcur", il);
|
||||
|
||||
cur = build_attn(inp_attn,
|
||||
model.layers[il].wo, nullptr,
|
||||
Qcur, Kcur, Vcur, nullptr, nullptr, nullptr, 1.0f/sqrtf(float(n_embd_head)), il);
|
||||
cb(cur, "kqv_out", il);
|
||||
|
||||
if (il == n_layer - 1 && inp_out_ids) {
|
||||
cur = ggml_get_rows(ctx0, cur, inp_out_ids);
|
||||
inpL = ggml_get_rows(ctx0, inpL, inp_out_ids);
|
||||
}
|
||||
|
||||
// re-add the layer input
|
||||
ggml_tensor * ffn_inp = ggml_add(ctx0, cur, inpL);
|
||||
cb(ffn_inp, "ffn_inp", il);
|
||||
|
||||
// attention layer norm
|
||||
cur = build_norm(ffn_inp,
|
||||
model.layers[il].ffn_norm, NULL,
|
||||
LLM_NORM, il);
|
||||
cb(cur, "ffn_norm", il);
|
||||
|
||||
cur = build_ffn(cur,
|
||||
model.layers[il].ffn_up, NULL, NULL,
|
||||
NULL, NULL, NULL,
|
||||
model.layers[il].ffn_down, NULL, NULL,
|
||||
NULL,
|
||||
LLM_FFN_GEGLU, LLM_FFN_SEQ, il);
|
||||
|
||||
// attentions bypass the intermediate layer
|
||||
cur = ggml_add(ctx0, cur, ffn_inp);
|
||||
|
||||
// input for next layer
|
||||
inpL = cur;
|
||||
}
|
||||
|
||||
cur = inpL;
|
||||
|
||||
cur = build_norm(cur,
|
||||
model.output_norm, NULL,
|
||||
LLM_NORM, -1);
|
||||
cb(cur, "final_norm_out", -1);
|
||||
|
||||
if (hparams.pooling_type == LLAMA_POOLING_TYPE_CLS) {
|
||||
// extracting cls token
|
||||
cur = ggml_view_1d(ctx0, cur, hparams.n_embd, 0);
|
||||
cb(cur, "cls_pooled_embd", -1);
|
||||
}
|
||||
|
||||
cb(cur, "res_embd", -1);
|
||||
res->t_embd = cur;
|
||||
ggml_build_forward_expand(gf, cur);
|
||||
}
|
||||
|
||||
// Explicit template instantiations
|
||||
template struct llm_build_modern_bert<false>;
|
||||
template struct llm_build_modern_bert<true>;
|
||||
@@ -16,6 +16,7 @@ int main(void) {
|
||||
for (int ex = 0; ex < LLAMA_EXAMPLE_COUNT; ex++) {
|
||||
try {
|
||||
auto ctx_arg = common_params_parser_init(params, (enum llama_example)ex);
|
||||
common_params_add_preset_options(ctx_arg.options);
|
||||
std::unordered_set<std::string> seen_args;
|
||||
std::unordered_set<std::string> seen_env_vars;
|
||||
for (const auto & opt : ctx_arg.options) {
|
||||
@@ -37,6 +38,30 @@ int main(void) {
|
||||
exit(1);
|
||||
}
|
||||
}
|
||||
|
||||
// ensure shorter argument precedes longer argument
|
||||
if (opt.args.size() > 1) {
|
||||
const std::string first(opt.args.front());
|
||||
const std::string last(opt.args.back());
|
||||
|
||||
if (first.length() > last.length()) {
|
||||
fprintf(stderr, "test-arg-parser: shorter argument should come before longer one: %s, %s\n",
|
||||
first.c_str(), last.c_str());
|
||||
assert(false);
|
||||
}
|
||||
}
|
||||
|
||||
// same check for negated arguments
|
||||
if (opt.args_neg.size() > 1) {
|
||||
const std::string first(opt.args_neg.front());
|
||||
const std::string last(opt.args_neg.back());
|
||||
|
||||
if (first.length() > last.length()) {
|
||||
fprintf(stderr, "test-arg-parser: shorter negated argument should come before longer one: %s, %s\n",
|
||||
first.c_str(), last.c_str());
|
||||
assert(false);
|
||||
}
|
||||
}
|
||||
}
|
||||
} catch (std::exception & e) {
|
||||
printf("%s\n", e.what());
|
||||
|
||||
+146
-47
@@ -2329,11 +2329,13 @@ struct test_set_rows : public test_case {
|
||||
struct test_rope_set_rows : public test_case {
|
||||
const ggml_type type;
|
||||
const ggml_type type_idx;
|
||||
const std::array<int64_t, 4> ne;
|
||||
const std::array<int64_t, 4> ne_a;
|
||||
int mode;
|
||||
const int n_ctx{512};
|
||||
const int n_dims{128};
|
||||
|
||||
std::string vars() override {
|
||||
return VARS_TO_STR4(type, type_idx, ne, mode);
|
||||
return VARS_TO_STR4(type, type_idx, ne_a, mode);
|
||||
}
|
||||
|
||||
std::string op_desc(ggml_tensor * t) override {
|
||||
@@ -2345,24 +2347,51 @@ struct test_rope_set_rows : public test_case {
|
||||
|
||||
test_rope_set_rows(ggml_type type,
|
||||
ggml_type type_idx,
|
||||
std::array<int64_t, 4> ne,
|
||||
std::array<int64_t, 4> ne_a,
|
||||
int mode)
|
||||
: type(type), type_idx(type_idx), ne(ne), mode(mode) {}
|
||||
: type(type), type_idx(type_idx), ne_a(ne_a), mode(mode) {}
|
||||
|
||||
ggml_tensor * build_graph(ggml_context * ctx) override {
|
||||
ggml_tensor * src = ggml_new_tensor_4d(ctx, GGML_TYPE_F32, ne[0], ne[1], ne[2], 1);
|
||||
ggml_set_name(src, "src");
|
||||
ggml_tensor * a = ggml_new_tensor_4d(ctx, GGML_TYPE_F32, ne_a[0], ne_a[1], ne_a[2], 1);
|
||||
ggml_set_name(a, "a");
|
||||
|
||||
ggml_tensor * pos = ggml_new_tensor_1d(ctx, GGML_TYPE_I32, ne[2]);
|
||||
const bool is_mrope = mode & GGML_ROPE_TYPE_MROPE;
|
||||
const bool is_vision = mode == GGML_ROPE_TYPE_VISION;
|
||||
|
||||
ggml_tensor * rope = ggml_rope(ctx, src, pos, ne[0], mode);
|
||||
ggml_tensor * pos;
|
||||
if (is_mrope || is_vision) {
|
||||
pos = ggml_new_tensor_1d(ctx, GGML_TYPE_I32, ne_a[2] * 4);
|
||||
} else {
|
||||
pos = ggml_new_tensor_1d(ctx, GGML_TYPE_I32, ne_a[2]);
|
||||
}
|
||||
ggml_set_name(pos, "pos");
|
||||
|
||||
ggml_tensor * view = ggml_view_2d(ctx, rope, ne[0] * ne[1], ne[2], rope->nb[2], 0);
|
||||
float fs = 1.4245f;
|
||||
float ef = 0.7465f;
|
||||
float af = 1.4245f;
|
||||
ggml_tensor * freq = nullptr;
|
||||
|
||||
ggml_tensor * dst = ggml_new_tensor_4d(ctx, type, ne[0] * ne[1], ne[2] * ne[3], 1, 1);
|
||||
ggml_tensor * rope = nullptr;
|
||||
if (is_mrope) {
|
||||
if (is_vision) {
|
||||
GGML_ASSERT(n_dims/4 > 0);
|
||||
int rope_sections[4] = {n_dims/4, n_dims/4, 0, 0}; // Vision-RoPE only use first two dimension for image (x, y) coordinate
|
||||
rope = ggml_rope_multi(ctx, a, pos, freq, n_dims/2, rope_sections, mode, 0, 10000.0f, fs, ef, af, 1.0f, 1.0f);
|
||||
} else {
|
||||
GGML_ASSERT(n_dims/3 > 0);
|
||||
int rope_sections[4] = {n_dims/3, n_dims/3, n_dims/3, 0};
|
||||
rope = ggml_rope_multi(ctx, a, pos, freq, n_dims, rope_sections, mode, 0, 10000.0f, fs, ef, af, 1.0f, 1.0f);
|
||||
}
|
||||
} else {
|
||||
rope = ggml_rope(ctx, a, pos, ne_a[0], mode);
|
||||
}
|
||||
|
||||
ggml_tensor * view = ggml_view_2d(ctx, rope, ne_a[0] * ne_a[1], ne_a[2], rope->nb[2], 0);
|
||||
|
||||
ggml_tensor * dst = ggml_new_tensor_4d(ctx, type, ne_a[0] * ne_a[1], ne_a[2] * ne_a[3], 1, 1);
|
||||
ggml_set_name(dst, "dst");
|
||||
|
||||
ggml_tensor * row_idxs = ggml_new_tensor_3d(ctx, type_idx, ne[2], 1, 1);
|
||||
ggml_tensor * row_idxs = ggml_new_tensor_3d(ctx, type_idx, ne_a[2], 1, 1);
|
||||
ggml_set_name(row_idxs, "row_idxs");
|
||||
|
||||
ggml_tensor * out = ggml_set_rows(ctx, dst, view, row_idxs);
|
||||
@@ -2373,14 +2402,26 @@ struct test_rope_set_rows : public test_case {
|
||||
|
||||
void initialize_tensors(ggml_context * ctx) override {
|
||||
for (ggml_tensor * t = ggml_get_first_tensor(ctx); t != NULL; t = ggml_get_next_tensor(ctx, t)) {
|
||||
if (t->type == GGML_TYPE_I64 || t->type == GGML_TYPE_I32) {
|
||||
if (strcmp(t->name, "row_idxs") == 0) {
|
||||
if (ggml_is_view_op(t->op)) {
|
||||
continue;
|
||||
}
|
||||
|
||||
init_set_rows_row_ids(t, ne[2]);
|
||||
init_set_rows_row_ids(t, ne_a[2]);
|
||||
} else if (t->type == GGML_TYPE_I32) {
|
||||
// pos
|
||||
const int num_pos_ids = (mode & GGML_ROPE_TYPE_MROPE) ? ne_a[2] * 4 : ne_a[2];
|
||||
std::vector<int> data(num_pos_ids);
|
||||
for (int i = 0; i < num_pos_ids; i++) {
|
||||
data[i] = rand() % n_ctx;
|
||||
}
|
||||
ggml_backend_tensor_set(t, data.data(), 0, num_pos_ids * sizeof(int));
|
||||
} else {
|
||||
init_tensor_uniform(t);
|
||||
if (t->ne[0] == n_dims/2) {
|
||||
// frequency factors in the range [0.9f, 1.1f]
|
||||
init_tensor_uniform(t, 0.9f, 1.1f);
|
||||
} else {
|
||||
init_tensor_uniform(t);
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
@@ -5118,25 +5159,36 @@ struct test_top_k : public test_case {
|
||||
}
|
||||
};
|
||||
|
||||
enum MoeGatingFunc {
|
||||
GATING_FUNC_SOFTMAX,
|
||||
GATING_FUNC_SIGMOID,
|
||||
GATING_FUNC_SOFTMAX_WEIGHT,
|
||||
};
|
||||
|
||||
struct test_topk_moe : public test_case {
|
||||
const std::array<int64_t, 4> ne;
|
||||
const int n_expert_used;
|
||||
const bool with_norm;
|
||||
const bool delayed_softmax;
|
||||
const bool bias_probs;
|
||||
const MoeGatingFunc gating_func;
|
||||
const float scale_w;
|
||||
|
||||
test_topk_moe(std::array<int64_t, 4> ne = { 10, 5, 1, 1 },
|
||||
int n_expert_used = 1,
|
||||
bool with_norm = false,
|
||||
bool delayed_softmax = false) :
|
||||
bool bias_probs = false,
|
||||
MoeGatingFunc gating_func = GATING_FUNC_SOFTMAX,
|
||||
float scale_w = 0.0f) :
|
||||
ne(ne),
|
||||
n_expert_used(n_expert_used),
|
||||
with_norm(with_norm),
|
||||
delayed_softmax(delayed_softmax) {
|
||||
bias_probs(bias_probs),
|
||||
gating_func(gating_func),
|
||||
scale_w(scale_w) {
|
||||
GGML_ASSERT(n_expert_used <= ne[0]);
|
||||
GGML_ASSERT(!(with_norm && delayed_softmax));
|
||||
}
|
||||
|
||||
std::string vars() override { return VARS_TO_STR4(ne, n_expert_used, with_norm, delayed_softmax); }
|
||||
std::string vars() override { return VARS_TO_STR6(ne, n_expert_used, with_norm, bias_probs, gating_func, scale_w); }
|
||||
|
||||
std::string op_desc(ggml_tensor * t) override {
|
||||
GGML_UNUSED(t);
|
||||
@@ -5150,28 +5202,47 @@ struct test_topk_moe : public test_case {
|
||||
const int n_tokens = ne[1];
|
||||
|
||||
ggml_tensor * logits = ggml_new_tensor(ctx, GGML_TYPE_F32, 4, ne.data());
|
||||
ggml_tensor * probs = delayed_softmax ? logits : ggml_soft_max(ctx, logits);
|
||||
ggml_tensor * selected_experts = ggml_argsort_top_k(ctx, probs, n_expert_used); // [n_expert_used, n_tokens]
|
||||
ggml_tensor * probs =
|
||||
(gating_func == GATING_FUNC_SOFTMAX) ? ggml_soft_max(ctx, logits) :
|
||||
(gating_func == GATING_FUNC_SIGMOID) ? ggml_sigmoid(ctx, logits) : logits;
|
||||
ggml_set_name(probs, "probs");
|
||||
|
||||
ggml_tensor * out = ggml_get_rows(ctx, ggml_reshape_3d(ctx, probs, 1, n_expert, n_tokens), selected_experts); // [1, n_expert_used, n_tokens]
|
||||
ggml_tensor * selection_probs = probs;
|
||||
if (bias_probs) {
|
||||
ggml_tensor * exp_probs_b = ggml_new_tensor(ctx, GGML_TYPE_F32, 4, ne.data());
|
||||
ggml_set_name(exp_probs_b, "exp_probs_b");
|
||||
selection_probs = ggml_add(ctx, probs, exp_probs_b);
|
||||
ggml_set_name(selection_probs, "selection_probs");
|
||||
}
|
||||
|
||||
if (delayed_softmax) {
|
||||
out = ggml_reshape_2d(ctx, out, n_expert_used, n_tokens);
|
||||
out = ggml_soft_max(ctx, out); // [n_expert_used, n_tokens]
|
||||
out = ggml_reshape_3d(ctx, out, 1, n_expert_used, n_tokens);
|
||||
ggml_tensor * selected_experts = ggml_argsort_top_k(ctx, selection_probs, n_expert_used); // [n_expert_used, n_tokens]
|
||||
ggml_set_name(selected_experts, "selected_experts");
|
||||
|
||||
ggml_tensor * weights = ggml_get_rows(ctx, ggml_reshape_3d(ctx, probs, 1, n_expert, n_tokens), selected_experts); // [1, n_expert_used, n_tokens]
|
||||
ggml_set_name(weights, "weights");
|
||||
|
||||
if (gating_func == GATING_FUNC_SOFTMAX_WEIGHT) {
|
||||
weights = ggml_reshape_2d(ctx, weights, n_expert_used, n_tokens);
|
||||
weights = ggml_soft_max(ctx, weights); // [n_expert_used, n_tokens]
|
||||
weights = ggml_reshape_3d(ctx, weights, 1, n_expert_used, n_tokens);
|
||||
}
|
||||
|
||||
if (with_norm) {
|
||||
out = ggml_reshape_2d(ctx, out, n_expert_used, n_tokens);
|
||||
ggml_tensor * weights_sum = ggml_sum_rows(ctx, out); // [1, n_tokens]
|
||||
weights = ggml_reshape_2d(ctx, weights, n_expert_used, n_tokens);
|
||||
ggml_tensor * weights_sum = ggml_sum_rows(ctx, weights); // [1, n_tokens]
|
||||
ggml_set_name(weights_sum, "weights_sum");
|
||||
|
||||
weights_sum = ggml_clamp(ctx, weights_sum, 6.103515625e-5, INFINITY);
|
||||
out = ggml_div(ctx, out, weights_sum); // [n_expert_used, n_tokens]
|
||||
out = ggml_reshape_3d(ctx, out, 1, n_expert_used, n_tokens);
|
||||
weights = ggml_div(ctx, weights, weights_sum); // [n_expert_used, n_tokens]
|
||||
weights = ggml_reshape_3d(ctx, weights, 1, n_expert_used, n_tokens);
|
||||
}
|
||||
|
||||
ggml_set_name(out, "out");
|
||||
return out;
|
||||
if (scale_w) {
|
||||
weights = ggml_scale(ctx, weights, scale_w);
|
||||
}
|
||||
|
||||
ggml_set_name(weights, "weights");
|
||||
return weights;
|
||||
}
|
||||
};
|
||||
|
||||
@@ -5344,6 +5415,13 @@ struct test_sum : public test_case {
|
||||
float grad_eps() override {
|
||||
return 0.1f * sqrtf(ne[0]*ne[1]*ne[2]*ne[3]);
|
||||
}
|
||||
|
||||
// Don't center the distribution around zero. Helps to avoid catastrophic cancellation.
|
||||
void initialize_tensors(ggml_context * ctx) override {
|
||||
for (ggml_tensor * t = ggml_get_first_tensor(ctx); t != nullptr; t = ggml_get_next_tensor(ctx, t)) {
|
||||
init_tensor_uniform(t, -0.9f, 1.1f);
|
||||
}
|
||||
}
|
||||
};
|
||||
|
||||
// GGML_OP_SUM_ROWS
|
||||
@@ -5410,6 +5488,13 @@ struct test_mean : public test_case {
|
||||
float grad_eps() override {
|
||||
return 0.1f * ne[0]*ne[1]*ne[2]*ne[3];
|
||||
}
|
||||
|
||||
// Don't center the distribution around zero. Helps to avoid catastrophic cancellation.
|
||||
void initialize_tensors(ggml_context * ctx) override {
|
||||
for (ggml_tensor * t = ggml_get_first_tensor(ctx); t != nullptr; t = ggml_get_next_tensor(ctx, t)) {
|
||||
init_tensor_uniform(t, -0.9f, 1.1f);
|
||||
}
|
||||
}
|
||||
};
|
||||
|
||||
// GGML_OP_UPSCALE
|
||||
@@ -6710,6 +6795,11 @@ static const ggml_type other_types[] = {
|
||||
GGML_TYPE_BF16,
|
||||
};
|
||||
|
||||
#ifdef _MSC_VER
|
||||
// Workaround long compile time with msvc
|
||||
#pragma optimize("", off)
|
||||
#endif
|
||||
|
||||
// Test cases for evaluation: should try to cover edge cases while using small input sizes to keep the runtime low
|
||||
static std::vector<std::unique_ptr<test_case>> make_test_cases_eval() {
|
||||
std::vector<std::unique_ptr<test_case>> test_cases;
|
||||
@@ -6805,10 +6895,12 @@ static std::vector<std::unique_ptr<test_case>> make_test_cases_eval() {
|
||||
}
|
||||
}
|
||||
|
||||
for (int mode : { GGML_ROPE_TYPE_NORMAL, GGML_ROPE_TYPE_NEOX }) {
|
||||
for (int mode : { GGML_ROPE_TYPE_NORMAL, GGML_ROPE_TYPE_NEOX, GGML_ROPE_TYPE_MROPE, GGML_ROPE_TYPE_VISION }) {
|
||||
for (ggml_type type : {GGML_TYPE_F16, GGML_TYPE_F32}) {
|
||||
test_cases.emplace_back(new test_rope_set_rows(type, GGML_TYPE_I64, { 128, 32, 1, 100 }, mode));
|
||||
test_cases.emplace_back(new test_rope_set_rows(type, GGML_TYPE_I64, { 128, 32, 512, 1 }, mode));
|
||||
for (int ne2 : {1, 8, 512}) {
|
||||
test_cases.emplace_back(new test_rope_set_rows(type, GGML_TYPE_I64, { 128, 32, ne2, 1 }, mode));
|
||||
test_cases.emplace_back(new test_rope_set_rows(type, GGML_TYPE_I64, { 128, 32, ne2, 3 }, mode));
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
@@ -6881,6 +6973,7 @@ static std::vector<std::unique_ptr<test_case>> make_test_cases_eval() {
|
||||
test_cases.emplace_back(new test_im2col(GGML_TYPE_F32, GGML_TYPE_F16, GGML_TYPE_F16, {12, 12, 1, 2560}, {3, 3, 1, 2560}, 1, 1, 1, 1, 1, 1, true));
|
||||
test_cases.emplace_back(new test_im2col(GGML_TYPE_F32, GGML_TYPE_F16, GGML_TYPE_F16, {12, 12, 2, 2560}, {3, 3, 2, 2560}, 1, 1, 1, 1, 1, 1, true));
|
||||
test_cases.emplace_back(new test_im2col(GGML_TYPE_F32, GGML_TYPE_F16, GGML_TYPE_F16, {5, 5, 1, 32}, {3, 4, 1, 32}, 1, 1, 0, 0, 1, 1, true));
|
||||
test_cases.emplace_back(new test_im2col(GGML_TYPE_F32, GGML_TYPE_F32, GGML_TYPE_F32, {2, 2, 1536, 729}, {2, 2, 1536, 4096}, 1, 1, 0, 0, 1, 1, true));
|
||||
|
||||
// im2col 3D
|
||||
test_cases.emplace_back(new test_im2col_3d(GGML_TYPE_F32, GGML_TYPE_F32, GGML_TYPE_F32));
|
||||
@@ -7972,19 +8065,22 @@ static std::vector<std::unique_ptr<test_case>> make_test_cases_eval() {
|
||||
}
|
||||
}
|
||||
|
||||
for (bool with_norm : {false, true}) {
|
||||
test_cases.emplace_back(new test_topk_moe({8, 22, 1, 1}, 4, with_norm));
|
||||
test_cases.emplace_back(new test_topk_moe({31, 22, 1, 1}, 8, with_norm));
|
||||
test_cases.emplace_back(new test_topk_moe({32, 22, 1, 1}, 8, with_norm));
|
||||
test_cases.emplace_back(new test_topk_moe({40, 22, 1, 1}, 8, with_norm));
|
||||
test_cases.emplace_back(new test_topk_moe({71, 22, 1, 1}, 8, with_norm));
|
||||
test_cases.emplace_back(new test_topk_moe({128, 1, 1, 1}, 128, with_norm));
|
||||
test_cases.emplace_back(new test_topk_moe({129, 1, 1, 1}, 128, with_norm));
|
||||
for (auto gate : {GATING_FUNC_SOFTMAX, GATING_FUNC_SIGMOID, GATING_FUNC_SOFTMAX_WEIGHT}) {
|
||||
for (bool with_norm : {false, true}) {
|
||||
for (bool bias_probs : {false, true}) {
|
||||
for (float scale_w : {0.0f, 2.0f}) {
|
||||
test_cases.emplace_back(new test_topk_moe({8, 22, 1, 1}, 4, with_norm, bias_probs, gate, scale_w));
|
||||
test_cases.emplace_back(new test_topk_moe({31, 22, 1, 1}, 8, with_norm, bias_probs, gate, scale_w));
|
||||
test_cases.emplace_back(new test_topk_moe({32, 22, 1, 1}, 8, with_norm, bias_probs, gate, scale_w));
|
||||
test_cases.emplace_back(new test_topk_moe({40, 22, 1, 1}, 8, with_norm, bias_probs, gate, scale_w));
|
||||
test_cases.emplace_back(new test_topk_moe({71, 22, 1, 1}, 8, with_norm, bias_probs, gate, scale_w));
|
||||
test_cases.emplace_back(new test_topk_moe({128, 1, 1, 1}, 128, with_norm, bias_probs, gate, scale_w));
|
||||
test_cases.emplace_back(new test_topk_moe({129, 1, 1, 1}, 128, with_norm, bias_probs, gate, scale_w));
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
test_cases.emplace_back(new test_topk_moe({ 8, 22, 1, 1 }, 4, /*with_norm*/ false, /*delayed_softmax*/ true));
|
||||
test_cases.emplace_back(new test_topk_moe({ 32, 22, 1, 1 }, 8, /*with_norm*/ false, /*delayed_softmax*/ true));
|
||||
|
||||
#if 0
|
||||
// these tests are disabled to save execution time, sbut they can be handy for debugging
|
||||
test_cases.emplace_back(new test_llama(2, true));
|
||||
@@ -7996,6 +8092,9 @@ static std::vector<std::unique_ptr<test_case>> make_test_cases_eval() {
|
||||
|
||||
return test_cases;
|
||||
}
|
||||
#ifdef _MSC_VER
|
||||
#pragma optimize("", on)
|
||||
#endif
|
||||
|
||||
// Test cases for performance evaluation: should be representative of real-world use cases
|
||||
static std::vector<std::unique_ptr<test_case>> make_test_cases_perf() {
|
||||
|
||||
@@ -1196,6 +1196,9 @@ int main(int argc, const char ** argv) {
|
||||
|
||||
test_sampler_chain();
|
||||
|
||||
llama_free(ctx);
|
||||
llama_model_free(model);
|
||||
|
||||
fprintf(stdout, "All tests passed.\n");
|
||||
return 0;
|
||||
}
|
||||
|
||||
@@ -300,8 +300,8 @@ int main(int argc, char **argv) {
|
||||
fprintf(stderr, "%s : tokens written to '%s'\n", __func__, (fname_text + ".tokcpp").c_str());
|
||||
}
|
||||
|
||||
llama_model_free(model);
|
||||
llama_free(ctx);
|
||||
llama_model_free(model);
|
||||
|
||||
llama_backend_free();
|
||||
|
||||
|
||||
@@ -146,8 +146,8 @@ int main(int argc, char **argv) {
|
||||
}
|
||||
}
|
||||
|
||||
llama_model_free(model);
|
||||
llama_free(ctx);
|
||||
llama_model_free(model);
|
||||
|
||||
llama_backend_free();
|
||||
|
||||
|
||||
@@ -116,8 +116,8 @@ int main(int argc, char ** argv) {
|
||||
}
|
||||
}
|
||||
|
||||
llama_model_free(model);
|
||||
llama_free(ctx);
|
||||
llama_model_free(model);
|
||||
|
||||
llama_backend_free();
|
||||
|
||||
|
||||
@@ -55,6 +55,7 @@ int main(int argc, char ** argv) {
|
||||
|
||||
if (ctx == NULL) {
|
||||
fprintf(stderr , "%s: error: failed to create the llama_context\n" , __func__);
|
||||
llama_model_free(model);
|
||||
return 1;
|
||||
}
|
||||
|
||||
@@ -108,6 +109,8 @@ int main(int argc, char ** argv) {
|
||||
|
||||
if (!decode_helper(ctx, batch, ctx_params.n_batch, true)) {
|
||||
LOG_ERR("%s: llama_decode() failed\n", __func__);
|
||||
llama_free(ctx);
|
||||
llama_model_free(model);
|
||||
return 1;
|
||||
}
|
||||
}
|
||||
@@ -147,6 +150,8 @@ int main(int argc, char ** argv) {
|
||||
|
||||
if (!decode_helper(ctx, batch, ctx_params.n_batch, false)) {
|
||||
LOG_ERR("%s: llama_decode() failed\n", __func__);
|
||||
llama_free(ctx);
|
||||
llama_model_free(model);
|
||||
return 1;
|
||||
}
|
||||
|
||||
@@ -165,6 +170,8 @@ int main(int argc, char ** argv) {
|
||||
common_batch_add(batch, get_token_rand(), pp + 0, { 0 }, true);
|
||||
if (!decode_helper(ctx, batch, ctx_params.n_batch, true)) {
|
||||
LOG_ERR("%s: llama_decode() failed\n", __func__);
|
||||
llama_free(ctx);
|
||||
llama_model_free(model);
|
||||
return 1;
|
||||
}
|
||||
llama_memory_seq_rm(mem, 0, pp, -1);
|
||||
@@ -184,6 +191,8 @@ int main(int argc, char ** argv) {
|
||||
|
||||
if (!decode_helper(ctx, batch, ctx_params.n_batch, true)) {
|
||||
LOG_ERR("%s: llama_decode() failed\n", __func__);
|
||||
llama_free(ctx);
|
||||
llama_model_free(model);
|
||||
return 1;
|
||||
}
|
||||
}
|
||||
@@ -200,6 +209,8 @@ int main(int argc, char ** argv) {
|
||||
|
||||
if (!decode_helper(ctx, batch, ctx_params.n_batch, true)) {
|
||||
LOG_ERR("%s: llama_decode() failed\n", __func__);
|
||||
llama_free(ctx);
|
||||
llama_model_free(model);
|
||||
return 1;
|
||||
}
|
||||
}
|
||||
|
||||
+187
-1
@@ -1 +1,187 @@
|
||||
TODO
|
||||
# llama.cpp/tools/cli
|
||||
|
||||
## Usage
|
||||
|
||||
<!-- HELP_START -->
|
||||
|
||||
<!-- IMPORTANT: The list below is auto-generated by llama-gen-docs; do NOT modify it manually -->
|
||||
|
||||
### Common params
|
||||
|
||||
| Argument | Explanation |
|
||||
| -------- | ----------- |
|
||||
| `-h, --help, --usage` | print usage and exit |
|
||||
| `--version` | show version and build info |
|
||||
| `-cl, --cache-list` | show list of models in cache |
|
||||
| `--completion-bash` | print source-able bash completion script for llama.cpp |
|
||||
| `--verbose-prompt` | print a verbose prompt before generation (default: false) |
|
||||
| `-t, --threads N` | number of CPU threads to use during generation (default: -1)<br/>(env: LLAMA_ARG_THREADS) |
|
||||
| `-tb, --threads-batch N` | number of threads to use during batch and prompt processing (default: same as --threads) |
|
||||
| `-C, --cpu-mask M` | CPU affinity mask: arbitrarily long hex. Complements cpu-range (default: "") |
|
||||
| `-Cr, --cpu-range lo-hi` | range of CPUs for affinity. Complements --cpu-mask |
|
||||
| `--cpu-strict <0\|1>` | use strict CPU placement (default: 0) |
|
||||
| `--prio N` | set process/thread priority : low(-1), normal(0), medium(1), high(2), realtime(3) (default: 0) |
|
||||
| `--poll <0...100>` | use polling level to wait for work (0 - no polling, default: 50) |
|
||||
| `-Cb, --cpu-mask-batch M` | CPU affinity mask: arbitrarily long hex. Complements cpu-range-batch (default: same as --cpu-mask) |
|
||||
| `-Crb, --cpu-range-batch lo-hi` | ranges of CPUs for affinity. Complements --cpu-mask-batch |
|
||||
| `--cpu-strict-batch <0\|1>` | use strict CPU placement (default: same as --cpu-strict) |
|
||||
| `--prio-batch N` | set process/thread priority : 0-normal, 1-medium, 2-high, 3-realtime (default: 0) |
|
||||
| `--poll-batch <0\|1>` | use polling to wait for work (default: same as --poll) |
|
||||
| `-c, --ctx-size N` | size of the prompt context (default: 0, 0 = loaded from model)<br/>(env: LLAMA_ARG_CTX_SIZE) |
|
||||
| `-n, --predict, --n-predict N` | number of tokens to predict (default: -1, -1 = infinity)<br/>(env: LLAMA_ARG_N_PREDICT) |
|
||||
| `-b, --batch-size N` | logical maximum batch size (default: 2048)<br/>(env: LLAMA_ARG_BATCH) |
|
||||
| `-ub, --ubatch-size N` | physical maximum batch size (default: 512)<br/>(env: LLAMA_ARG_UBATCH) |
|
||||
| `--keep N` | number of tokens to keep from the initial prompt (default: 0, -1 = all) |
|
||||
| `--swa-full` | use full-size SWA cache (default: false)<br/>[(more info)](https://github.com/ggml-org/llama.cpp/pull/13194#issuecomment-2868343055)<br/>(env: LLAMA_ARG_SWA_FULL) |
|
||||
| `-fa, --flash-attn [on\|off\|auto]` | set Flash Attention use ('on', 'off', or 'auto', default: 'auto')<br/>(env: LLAMA_ARG_FLASH_ATTN) |
|
||||
| `-p, --prompt PROMPT` | prompt to start generation with; for system message, use -sys |
|
||||
| `--perf, --no-perf` | whether to enable internal libllama performance timings (default: false)<br/>(env: LLAMA_ARG_PERF) |
|
||||
| `-f, --file FNAME` | a file containing the prompt (default: none) |
|
||||
| `-bf, --binary-file FNAME` | binary file containing the prompt (default: none) |
|
||||
| `-e, --escape, --no-escape` | whether to process escapes sequences (\n, \r, \t, \', \", \\) (default: true) |
|
||||
| `--rope-scaling {none,linear,yarn}` | RoPE frequency scaling method, defaults to linear unless specified by the model<br/>(env: LLAMA_ARG_ROPE_SCALING_TYPE) |
|
||||
| `--rope-scale N` | RoPE context scaling factor, expands context by a factor of N<br/>(env: LLAMA_ARG_ROPE_SCALE) |
|
||||
| `--rope-freq-base N` | RoPE base frequency, used by NTK-aware scaling (default: loaded from model)<br/>(env: LLAMA_ARG_ROPE_FREQ_BASE) |
|
||||
| `--rope-freq-scale N` | RoPE frequency scaling factor, expands context by a factor of 1/N<br/>(env: LLAMA_ARG_ROPE_FREQ_SCALE) |
|
||||
| `--yarn-orig-ctx N` | YaRN: original context size of model (default: 0 = model training context size)<br/>(env: LLAMA_ARG_YARN_ORIG_CTX) |
|
||||
| `--yarn-ext-factor N` | YaRN: extrapolation mix factor (default: -1.0, 0.0 = full interpolation)<br/>(env: LLAMA_ARG_YARN_EXT_FACTOR) |
|
||||
| `--yarn-attn-factor N` | YaRN: scale sqrt(t) or attention magnitude (default: -1.0)<br/>(env: LLAMA_ARG_YARN_ATTN_FACTOR) |
|
||||
| `--yarn-beta-slow N` | YaRN: high correction dim or alpha (default: -1.0)<br/>(env: LLAMA_ARG_YARN_BETA_SLOW) |
|
||||
| `--yarn-beta-fast N` | YaRN: low correction dim or beta (default: -1.0)<br/>(env: LLAMA_ARG_YARN_BETA_FAST) |
|
||||
| `-kvo, --kv-offload, -nkvo, --no-kv-offload` | whether to enable KV cache offloading (default: enabled)<br/>(env: LLAMA_ARG_KV_OFFLOAD) |
|
||||
| `--repack, -nr, --no-repack` | whether to enable weight repacking (default: enabled)<br/>(env: LLAMA_ARG_REPACK) |
|
||||
| `--no-host` | bypass host buffer allowing extra buffers to be used<br/>(env: LLAMA_ARG_NO_HOST) |
|
||||
| `-ctk, --cache-type-k TYPE` | KV cache data type for K<br/>allowed values: f32, f16, bf16, q8_0, q4_0, q4_1, iq4_nl, q5_0, q5_1<br/>(default: f16)<br/>(env: LLAMA_ARG_CACHE_TYPE_K) |
|
||||
| `-ctv, --cache-type-v TYPE` | KV cache data type for V<br/>allowed values: f32, f16, bf16, q8_0, q4_0, q4_1, iq4_nl, q5_0, q5_1<br/>(default: f16)<br/>(env: LLAMA_ARG_CACHE_TYPE_V) |
|
||||
| `-dt, --defrag-thold N` | KV cache defragmentation threshold (DEPRECATED)<br/>(env: LLAMA_ARG_DEFRAG_THOLD) |
|
||||
| `-np, --parallel N` | number of parallel sequences to decode (default: 1)<br/>(env: LLAMA_ARG_N_PARALLEL) |
|
||||
| `--mlock` | force system to keep model in RAM rather than swapping or compressing<br/>(env: LLAMA_ARG_MLOCK) |
|
||||
| `--mmap, --no-mmap` | whether to memory-map model (if disabled, slower load but may reduce pageouts if not using mlock) (default: enabled)<br/>(env: LLAMA_ARG_MMAP) |
|
||||
| `--numa TYPE` | attempt optimizations that help on some NUMA systems<br/>- distribute: spread execution evenly over all nodes<br/>- isolate: only spawn threads on CPUs on the node that execution started on<br/>- numactl: use the CPU map provided by numactl<br/>if run without this previously, it is recommended to drop the system page cache before using this<br/>see https://github.com/ggml-org/llama.cpp/issues/1437<br/>(env: LLAMA_ARG_NUMA) |
|
||||
| `-dev, --device <dev1,dev2,..>` | comma-separated list of devices to use for offloading (none = don't offload)<br/>use --list-devices to see a list of available devices<br/>(env: LLAMA_ARG_DEVICE) |
|
||||
| `--list-devices` | print list of available devices and exit |
|
||||
| `-ot, --override-tensor <tensor name pattern>=<buffer type>,...` | override tensor buffer type |
|
||||
| `-cmoe, --cpu-moe` | keep all Mixture of Experts (MoE) weights in the CPU<br/>(env: LLAMA_ARG_CPU_MOE) |
|
||||
| `-ncmoe, --n-cpu-moe N` | keep the Mixture of Experts (MoE) weights of the first N layers in the CPU<br/>(env: LLAMA_ARG_N_CPU_MOE) |
|
||||
| `-ngl, --gpu-layers, --n-gpu-layers N` | max. number of layers to store in VRAM (default: -1)<br/>(env: LLAMA_ARG_N_GPU_LAYERS) |
|
||||
| `-sm, --split-mode {none,layer,row}` | how to split the model across multiple GPUs, one of:<br/>- none: use one GPU only<br/>- layer (default): split layers and KV across GPUs<br/>- row: split rows across GPUs<br/>(env: LLAMA_ARG_SPLIT_MODE) |
|
||||
| `-ts, --tensor-split N0,N1,N2,...` | fraction of the model to offload to each GPU, comma-separated list of proportions, e.g. 3,1<br/>(env: LLAMA_ARG_TENSOR_SPLIT) |
|
||||
| `-mg, --main-gpu INDEX` | the GPU to use for the model (with split-mode = none), or for intermediate results and KV (with split-mode = row) (default: 0)<br/>(env: LLAMA_ARG_MAIN_GPU) |
|
||||
| `-fit, --fit [on\|off]` | whether to adjust unset arguments to fit in device memory ('on' or 'off', default: 'on')<br/>(env: LLAMA_ARG_FIT) |
|
||||
| `-fitt, --fit-target MiB` | target margin per device for --fit option, default: 1024<br/>(env: LLAMA_ARG_FIT_TARGET) |
|
||||
| `-fitc, --fit-ctx N` | minimum ctx size that can be set by --fit option, default: 4096<br/>(env: LLAMA_ARG_FIT_CTX) |
|
||||
| `--check-tensors` | check model tensor data for invalid values (default: false) |
|
||||
| `--override-kv KEY=TYPE:VALUE,...` | advanced option to override model metadata by key. to specify multiple overrides, either use comma-separated or repeat this argument.<br/>types: int, float, bool, str. example: --override-kv tokenizer.ggml.add_bos_token=bool:false,tokenizer.ggml.add_eos_token=bool:false |
|
||||
| `--op-offload, --no-op-offload` | whether to offload host tensor operations to device (default: true) |
|
||||
| `--lora FNAME` | path to LoRA adapter (use comma-separated values to load multiple adapters) |
|
||||
| `--lora-scaled FNAME:SCALE,...` | path to LoRA adapter with user defined scaling (format: FNAME:SCALE,...)<br/>note: use comma-separated values |
|
||||
| `--control-vector FNAME` | add a control vector<br/>note: use comma-separated values to add multiple control vectors |
|
||||
| `--control-vector-scaled FNAME:SCALE,...` | add a control vector with user defined scaling SCALE<br/>note: use comma-separated values (format: FNAME:SCALE,...) |
|
||||
| `--control-vector-layer-range START END` | layer range to apply the control vector(s) to, start and end inclusive |
|
||||
| `-m, --model FNAME` | model path to load<br/>(env: LLAMA_ARG_MODEL) |
|
||||
| `-mu, --model-url MODEL_URL` | model download url (default: unused)<br/>(env: LLAMA_ARG_MODEL_URL) |
|
||||
| `-dr, --docker-repo [<repo>/]<model>[:quant]` | Docker Hub model repository. repo is optional, default to ai/. quant is optional, default to :latest.<br/>example: gemma3<br/>(default: unused)<br/>(env: LLAMA_ARG_DOCKER_REPO) |
|
||||
| `-hf, -hfr, --hf-repo <user>/<model>[:quant]` | Hugging Face model repository; quant is optional, case-insensitive, default to Q4_K_M, or falls back to the first file in the repo if Q4_K_M doesn't exist.<br/>mmproj is also downloaded automatically if available. to disable, add --no-mmproj<br/>example: unsloth/phi-4-GGUF:q4_k_m<br/>(default: unused)<br/>(env: LLAMA_ARG_HF_REPO) |
|
||||
| `-hfd, -hfrd, --hf-repo-draft <user>/<model>[:quant]` | Same as --hf-repo, but for the draft model (default: unused)<br/>(env: LLAMA_ARG_HFD_REPO) |
|
||||
| `-hff, --hf-file FILE` | Hugging Face model file. If specified, it will override the quant in --hf-repo (default: unused)<br/>(env: LLAMA_ARG_HF_FILE) |
|
||||
| `-hfv, -hfrv, --hf-repo-v <user>/<model>[:quant]` | Hugging Face model repository for the vocoder model (default: unused)<br/>(env: LLAMA_ARG_HF_REPO_V) |
|
||||
| `-hffv, --hf-file-v FILE` | Hugging Face model file for the vocoder model (default: unused)<br/>(env: LLAMA_ARG_HF_FILE_V) |
|
||||
| `-hft, --hf-token TOKEN` | Hugging Face access token (default: value from HF_TOKEN environment variable)<br/>(env: HF_TOKEN) |
|
||||
| `--log-disable` | Log disable |
|
||||
| `--log-file FNAME` | Log to file<br/>(env: LLAMA_LOG_FILE) |
|
||||
| `--log-colors [on\|off\|auto]` | Set colored logging ('on', 'off', or 'auto', default: 'auto')<br/>'auto' enables colors when output is to a terminal<br/>(env: LLAMA_LOG_COLORS) |
|
||||
| `-v, --verbose, --log-verbose` | Set verbosity level to infinity (i.e. log all messages, useful for debugging) |
|
||||
| `--offline` | Offline mode: forces use of cache, prevents network access<br/>(env: LLAMA_OFFLINE) |
|
||||
| `-lv, --verbosity, --log-verbosity N` | Set the verbosity threshold. Messages with a higher verbosity will be ignored. Values:<br/> - 0: generic output<br/> - 1: error<br/> - 2: warning<br/> - 3: info<br/> - 4: debug<br/>(default: 3)<br/><br/>(env: LLAMA_LOG_VERBOSITY) |
|
||||
| `--log-prefix` | Enable prefix in log messages<br/>(env: LLAMA_LOG_PREFIX) |
|
||||
| `--log-timestamps` | Enable timestamps in log messages<br/>(env: LLAMA_LOG_TIMESTAMPS) |
|
||||
| `-ctkd, --cache-type-k-draft TYPE` | KV cache data type for K for the draft model<br/>allowed values: f32, f16, bf16, q8_0, q4_0, q4_1, iq4_nl, q5_0, q5_1<br/>(default: f16)<br/>(env: LLAMA_ARG_CACHE_TYPE_K_DRAFT) |
|
||||
| `-ctvd, --cache-type-v-draft TYPE` | KV cache data type for V for the draft model<br/>allowed values: f32, f16, bf16, q8_0, q4_0, q4_1, iq4_nl, q5_0, q5_1<br/>(default: f16)<br/>(env: LLAMA_ARG_CACHE_TYPE_V_DRAFT) |
|
||||
|
||||
|
||||
### Sampling params
|
||||
|
||||
| Argument | Explanation |
|
||||
| -------- | ----------- |
|
||||
| `--samplers SAMPLERS` | samplers that will be used for generation in the order, separated by ';'<br/>(default: penalties;dry;top_n_sigma;top_k;typ_p;top_p;min_p;xtc;temperature) |
|
||||
| `-s, --seed SEED` | RNG seed (default: -1, use random seed for -1) |
|
||||
| `--sampler-seq, --sampling-seq SEQUENCE` | simplified sequence for samplers that will be used (default: edskypmxt) |
|
||||
| `--ignore-eos` | ignore end of stream token and continue generating (implies --logit-bias EOS-inf) |
|
||||
| `--temp N` | temperature (default: 0.8) |
|
||||
| `--top-k N` | top-k sampling (default: 40, 0 = disabled)<br/>(env: LLAMA_ARG_TOP_K) |
|
||||
| `--top-p N` | top-p sampling (default: 0.9, 1.0 = disabled) |
|
||||
| `--min-p N` | min-p sampling (default: 0.1, 0.0 = disabled) |
|
||||
| `--top-nsigma N` | top-n-sigma sampling (default: -1.0, -1.0 = disabled) |
|
||||
| `--xtc-probability N` | xtc probability (default: 0.0, 0.0 = disabled) |
|
||||
| `--xtc-threshold N` | xtc threshold (default: 0.1, 1.0 = disabled) |
|
||||
| `--typical N` | locally typical sampling, parameter p (default: 1.0, 1.0 = disabled) |
|
||||
| `--repeat-last-n N` | last n tokens to consider for penalize (default: 64, 0 = disabled, -1 = ctx_size) |
|
||||
| `--repeat-penalty N` | penalize repeat sequence of tokens (default: 1.0, 1.0 = disabled) |
|
||||
| `--presence-penalty N` | repeat alpha presence penalty (default: 0.0, 0.0 = disabled) |
|
||||
| `--frequency-penalty N` | repeat alpha frequency penalty (default: 0.0, 0.0 = disabled) |
|
||||
| `--dry-multiplier N` | set DRY sampling multiplier (default: 0.0, 0.0 = disabled) |
|
||||
| `--dry-base N` | set DRY sampling base value (default: 1.75) |
|
||||
| `--dry-allowed-length N` | set allowed length for DRY sampling (default: 2) |
|
||||
| `--dry-penalty-last-n N` | set DRY penalty for the last n tokens (default: -1, 0 = disable, -1 = context size) |
|
||||
| `--dry-sequence-breaker STRING` | add sequence breaker for DRY sampling, clearing out default breakers ('\n', ':', '"', '*') in the process; use "none" to not use any sequence breakers |
|
||||
| `--dynatemp-range N` | dynamic temperature range (default: 0.0, 0.0 = disabled) |
|
||||
| `--dynatemp-exp N` | dynamic temperature exponent (default: 1.0) |
|
||||
| `--mirostat N` | use Mirostat sampling.<br/>Top K, Nucleus and Locally Typical samplers are ignored if used.<br/>(default: 0, 0 = disabled, 1 = Mirostat, 2 = Mirostat 2.0) |
|
||||
| `--mirostat-lr N` | Mirostat learning rate, parameter eta (default: 0.1) |
|
||||
| `--mirostat-ent N` | Mirostat target entropy, parameter tau (default: 5.0) |
|
||||
| `-l, --logit-bias TOKEN_ID(+/-)BIAS` | modifies the likelihood of token appearing in the completion,<br/>i.e. `--logit-bias 15043+1` to increase likelihood of token ' Hello',<br/>or `--logit-bias 15043-1` to decrease likelihood of token ' Hello' |
|
||||
| `--grammar GRAMMAR` | BNF-like grammar to constrain generations (see samples in grammars/ dir) (default: '') |
|
||||
| `--grammar-file FNAME` | file to read grammar from |
|
||||
| `-j, --json-schema SCHEMA` | JSON schema to constrain generations (https://json-schema.org/), e.g. `{}` for any JSON object<br/>For schemas w/ external $refs, use --grammar + example/json_schema_to_grammar.py instead |
|
||||
| `-jf, --json-schema-file FILE` | File containing a JSON schema to constrain generations (https://json-schema.org/), e.g. `{}` for any JSON object<br/>For schemas w/ external $refs, use --grammar + example/json_schema_to_grammar.py instead |
|
||||
|
||||
|
||||
### CLI-specific params
|
||||
|
||||
| Argument | Explanation |
|
||||
| -------- | ----------- |
|
||||
| `--display-prompt, --no-display-prompt` | whether to print prompt at generation (default: true) |
|
||||
| `-co, --color [on\|off\|auto]` | Colorize output to distinguish prompt and user input from generations ('on', 'off', or 'auto', default: 'auto')<br/>'auto' enables colors when output is to a terminal |
|
||||
| `--ctx-checkpoints, --swa-checkpoints N` | max number of context checkpoints to create per slot (default: 8)[(more info)](https://github.com/ggml-org/llama.cpp/pull/15293)<br/>(env: LLAMA_ARG_CTX_CHECKPOINTS) |
|
||||
| `-cram, --cache-ram N` | set the maximum cache size in MiB (default: 8192, -1 - no limit, 0 - disable)[(more info)](https://github.com/ggml-org/llama.cpp/pull/16391)<br/>(env: LLAMA_ARG_CACHE_RAM) |
|
||||
| `--context-shift, --no-context-shift` | whether to use context shift on infinite text generation (default: disabled)<br/>(env: LLAMA_ARG_CONTEXT_SHIFT) |
|
||||
| `-sys, --system-prompt PROMPT` | system prompt to use with model (if applicable, depending on chat template) |
|
||||
| `--show-timings, --no-show-timings` | whether to show timing information after each response (default: true)<br/>(env: LLAMA_ARG_SHOW_TIMINGS) |
|
||||
| `-sysf, --system-prompt-file FNAME` | a file containing the system prompt (default: none) |
|
||||
| `-r, --reverse-prompt PROMPT` | halt generation at PROMPT, return control in interactive mode |
|
||||
| `-sp, --special` | special tokens output enabled (default: false) |
|
||||
| `-cnv, --conversation, -no-cnv, --no-conversation` | whether to run in conversation mode:<br/>- does not print special tokens and suffix/prefix<br/>- interactive mode is also enabled<br/>(default: auto enabled if chat template is available) |
|
||||
| `-st, --single-turn` | run conversation for a single turn only, then exit when done<br/>will not be interactive if first turn is predefined with --prompt<br/>(default: false) |
|
||||
| `-mli, --multiline-input` | allows you to write or paste multiple lines without ending each in '\' |
|
||||
| `--warmup, --no-warmup` | whether to perform warmup with an empty run (default: enabled) |
|
||||
| `-mm, --mmproj FILE` | path to a multimodal projector file. see tools/mtmd/README.md<br/>note: if -hf is used, this argument can be omitted<br/>(env: LLAMA_ARG_MMPROJ) |
|
||||
| `-mmu, --mmproj-url URL` | URL to a multimodal projector file. see tools/mtmd/README.md<br/>(env: LLAMA_ARG_MMPROJ_URL) |
|
||||
| `--mmproj-auto, --no-mmproj, --no-mmproj-auto` | whether to use multimodal projector file (if available), useful when using -hf (default: enabled)<br/>(env: LLAMA_ARG_MMPROJ_AUTO) |
|
||||
| `--mmproj-offload, --no-mmproj-offload` | whether to enable GPU offloading for multimodal projector (default: enabled)<br/>(env: LLAMA_ARG_MMPROJ_OFFLOAD) |
|
||||
| `--image, --audio FILE` | path to an image or audio file. use with multimodal models, use comma-separated values for multiple files |
|
||||
| `--image-min-tokens N` | minimum number of tokens each image can take, only used by vision models with dynamic resolution (default: read from model)<br/>(env: LLAMA_ARG_IMAGE_MIN_TOKENS) |
|
||||
| `--image-max-tokens N` | maximum number of tokens each image can take, only used by vision models with dynamic resolution (default: read from model)<br/>(env: LLAMA_ARG_IMAGE_MAX_TOKENS) |
|
||||
| `-otd, --override-tensor-draft <tensor name pattern>=<buffer type>,...` | override tensor buffer type for draft model |
|
||||
| `-cmoed, --cpu-moe-draft` | keep all Mixture of Experts (MoE) weights in the CPU for the draft model<br/>(env: LLAMA_ARG_CPU_MOE_DRAFT) |
|
||||
| `-ncmoed, --n-cpu-moe-draft N` | keep the Mixture of Experts (MoE) weights of the first N layers in the CPU for the draft model<br/>(env: LLAMA_ARG_N_CPU_MOE_DRAFT) |
|
||||
| `--chat-template-kwargs STRING` | sets additional params for the json template parser<br/>(env: LLAMA_CHAT_TEMPLATE_KWARGS) |
|
||||
| `--jinja, --no-jinja` | whether to use jinja template engine for chat (default: enabled)<br/>(env: LLAMA_ARG_JINJA) |
|
||||
| `--reasoning-format FORMAT` | controls whether thought tags are allowed and/or extracted from the response, and in which format they're returned; one of:<br/>- none: leaves thoughts unparsed in `message.content`<br/>- deepseek: puts thoughts in `message.reasoning_content`<br/>- deepseek-legacy: keeps `<think>` tags in `message.content` while also populating `message.reasoning_content`<br/>(default: auto)<br/>(env: LLAMA_ARG_THINK) |
|
||||
| `--reasoning-budget N` | controls the amount of thinking allowed; currently only one of: -1 for unrestricted thinking budget, or 0 to disable thinking (default: -1)<br/>(env: LLAMA_ARG_THINK_BUDGET) |
|
||||
| `--chat-template JINJA_TEMPLATE` | set custom jinja chat template (default: template taken from model's metadata)<br/>if suffix/prefix are specified, template will be disabled<br/>only commonly used templates are accepted (unless --jinja is set before this flag):<br/>list of built-in templates:<br/>bailing, bailing-think, bailing2, chatglm3, chatglm4, chatml, command-r, deepseek, deepseek2, deepseek3, exaone3, exaone4, falcon3, gemma, gigachat, glmedge, gpt-oss, granite, grok-2, hunyuan-dense, hunyuan-moe, kimi-k2, llama2, llama2-sys, llama2-sys-bos, llama2-sys-strip, llama3, llama4, megrez, minicpm, mistral-v1, mistral-v3, mistral-v3-tekken, mistral-v7, mistral-v7-tekken, monarch, openchat, orion, pangu-embedded, phi3, phi4, rwkv-world, seed_oss, smolvlm, vicuna, vicuna-orca, yandex, zephyr<br/>(env: LLAMA_ARG_CHAT_TEMPLATE) |
|
||||
| `--chat-template-file JINJA_TEMPLATE_FILE` | set custom jinja chat template file (default: template taken from model's metadata)<br/>if suffix/prefix are specified, template will be disabled<br/>only commonly used templates are accepted (unless --jinja is set before this flag):<br/>list of built-in templates:<br/>bailing, bailing-think, bailing2, chatglm3, chatglm4, chatml, command-r, deepseek, deepseek2, deepseek3, exaone3, exaone4, falcon3, gemma, gigachat, glmedge, gpt-oss, granite, grok-2, hunyuan-dense, hunyuan-moe, kimi-k2, llama2, llama2-sys, llama2-sys-bos, llama2-sys-strip, llama3, llama4, megrez, minicpm, mistral-v1, mistral-v3, mistral-v3-tekken, mistral-v7, mistral-v7-tekken, monarch, openchat, orion, pangu-embedded, phi3, phi4, rwkv-world, seed_oss, smolvlm, vicuna, vicuna-orca, yandex, zephyr<br/>(env: LLAMA_ARG_CHAT_TEMPLATE_FILE) |
|
||||
| `--simple-io` | use basic IO for better compatibility in subprocesses and limited consoles |
|
||||
| `--draft, --draft-n, --draft-max N` | number of tokens to draft for speculative decoding (default: 16)<br/>(env: LLAMA_ARG_DRAFT_MAX) |
|
||||
| `--draft-min, --draft-n-min N` | minimum number of draft tokens to use for speculative decoding (default: 0)<br/>(env: LLAMA_ARG_DRAFT_MIN) |
|
||||
| `--draft-p-min P` | minimum speculative decoding probability (greedy) (default: 0.8)<br/>(env: LLAMA_ARG_DRAFT_P_MIN) |
|
||||
| `-cd, --ctx-size-draft N` | size of the prompt context for the draft model (default: 0, 0 = loaded from model)<br/>(env: LLAMA_ARG_CTX_SIZE_DRAFT) |
|
||||
| `-devd, --device-draft <dev1,dev2,..>` | comma-separated list of devices to use for offloading the draft model (none = don't offload)<br/>use --list-devices to see a list of available devices |
|
||||
| `-ngld, --gpu-layers-draft, --n-gpu-layers-draft N` | number of layers to store in VRAM for the draft model<br/>(env: LLAMA_ARG_N_GPU_LAYERS_DRAFT) |
|
||||
| `-md, --model-draft FNAME` | draft model for speculative decoding (default: unused)<br/>(env: LLAMA_ARG_MODEL_DRAFT) |
|
||||
| `--spec-replace TARGET DRAFT` | translate the string in TARGET into DRAFT if the draft model and main model are not compatible |
|
||||
| `--gpt-oss-20b-default` | use gpt-oss-20b (note: can download weights from the internet) |
|
||||
| `--gpt-oss-120b-default` | use gpt-oss-120b (note: can download weights from the internet) |
|
||||
| `--vision-gemma-4b-default` | use Gemma 3 4B QAT (note: can download weights from the internet) |
|
||||
| `--vision-gemma-12b-default` | use Gemma 3 12B QAT (note: can download weights from the internet) |
|
||||
|
||||
<!-- HELP_END -->
|
||||
|
||||
+1
-3
@@ -209,8 +209,6 @@ int main(int argc, char ** argv) {
|
||||
return 1;
|
||||
}
|
||||
|
||||
ctx_cli.ctx_server.init();
|
||||
|
||||
console::spinner::stop();
|
||||
console::log("\n");
|
||||
|
||||
@@ -218,7 +216,7 @@ int main(int argc, char ** argv) {
|
||||
ctx_cli.ctx_server.start_loop();
|
||||
});
|
||||
|
||||
auto inf = ctx_cli.ctx_server.get_info();
|
||||
auto inf = ctx_cli.ctx_server.get_meta();
|
||||
std::string modalities = "text";
|
||||
if (inf.has_inp_image) {
|
||||
modalities += ", vision";
|
||||
|
||||
+179
-7
@@ -5,13 +5,14 @@ This example program allows you to use various LLaMA language models easily and
|
||||
## Table of Contents
|
||||
|
||||
1. [Quick Start](#quick-start)
|
||||
2. [Common Options](#common-options)
|
||||
3. [Input Prompts](#input-prompts)
|
||||
4. [Interaction](#interaction)
|
||||
5. [Context Management](#context-management)
|
||||
6. [Generation Flags](#generation-flags)
|
||||
7. [Performance Tuning and Memory Options](#performance-tuning-and-memory-options)
|
||||
8. [Additional Options](#additional-options)
|
||||
2. [Usage](#usage)
|
||||
3. [Common Options](#common-options)
|
||||
4. [Input Prompts](#input-prompts)
|
||||
5. [Interaction](#interaction)
|
||||
6. [Context Management](#context-management)
|
||||
7. [Generation Flags](#generation-flags)
|
||||
8. [Performance Tuning and Memory Options](#performance-tuning-and-memory-options)
|
||||
9. [Additional Options](#additional-options)
|
||||
|
||||
## Quick Start
|
||||
|
||||
@@ -82,6 +83,177 @@ Once downloaded, place your model in the models folder in llama.cpp.
|
||||
llama-completion.exe -m models\gemma-1.1-7b-it.Q4_K_M.gguf --ignore-eos -n -1
|
||||
```
|
||||
|
||||
## Usage
|
||||
|
||||
<!-- HELP_START -->
|
||||
|
||||
<!-- IMPORTANT: The list below is auto-generated by llama-gen-docs; do NOT modify it manually -->
|
||||
|
||||
### Common params
|
||||
|
||||
| Argument | Explanation |
|
||||
| -------- | ----------- |
|
||||
| `-h, --help, --usage` | print usage and exit |
|
||||
| `--version` | show version and build info |
|
||||
| `-cl, --cache-list` | show list of models in cache |
|
||||
| `--completion-bash` | print source-able bash completion script for llama.cpp |
|
||||
| `--verbose-prompt` | print a verbose prompt before generation (default: false) |
|
||||
| `-t, --threads N` | number of CPU threads to use during generation (default: -1)<br/>(env: LLAMA_ARG_THREADS) |
|
||||
| `-tb, --threads-batch N` | number of threads to use during batch and prompt processing (default: same as --threads) |
|
||||
| `-C, --cpu-mask M` | CPU affinity mask: arbitrarily long hex. Complements cpu-range (default: "") |
|
||||
| `-Cr, --cpu-range lo-hi` | range of CPUs for affinity. Complements --cpu-mask |
|
||||
| `--cpu-strict <0\|1>` | use strict CPU placement (default: 0) |
|
||||
| `--prio N` | set process/thread priority : low(-1), normal(0), medium(1), high(2), realtime(3) (default: 0) |
|
||||
| `--poll <0...100>` | use polling level to wait for work (0 - no polling, default: 50) |
|
||||
| `-Cb, --cpu-mask-batch M` | CPU affinity mask: arbitrarily long hex. Complements cpu-range-batch (default: same as --cpu-mask) |
|
||||
| `-Crb, --cpu-range-batch lo-hi` | ranges of CPUs for affinity. Complements --cpu-mask-batch |
|
||||
| `--cpu-strict-batch <0\|1>` | use strict CPU placement (default: same as --cpu-strict) |
|
||||
| `--prio-batch N` | set process/thread priority : 0-normal, 1-medium, 2-high, 3-realtime (default: 0) |
|
||||
| `--poll-batch <0\|1>` | use polling to wait for work (default: same as --poll) |
|
||||
| `-c, --ctx-size N` | size of the prompt context (default: 0, 0 = loaded from model)<br/>(env: LLAMA_ARG_CTX_SIZE) |
|
||||
| `-n, --predict, --n-predict N` | number of tokens to predict (default: -1, -1 = infinity, -2 = until context filled)<br/>(env: LLAMA_ARG_N_PREDICT) |
|
||||
| `-b, --batch-size N` | logical maximum batch size (default: 2048)<br/>(env: LLAMA_ARG_BATCH) |
|
||||
| `-ub, --ubatch-size N` | physical maximum batch size (default: 512)<br/>(env: LLAMA_ARG_UBATCH) |
|
||||
| `--keep N` | number of tokens to keep from the initial prompt (default: 0, -1 = all) |
|
||||
| `--swa-full` | use full-size SWA cache (default: false)<br/>[(more info)](https://github.com/ggml-org/llama.cpp/pull/13194#issuecomment-2868343055)<br/>(env: LLAMA_ARG_SWA_FULL) |
|
||||
| `-fa, --flash-attn [on\|off\|auto]` | set Flash Attention use ('on', 'off', or 'auto', default: 'auto')<br/>(env: LLAMA_ARG_FLASH_ATTN) |
|
||||
| `-p, --prompt PROMPT` | prompt to start generation with; for system message, use -sys |
|
||||
| `--perf, --no-perf` | whether to enable internal libllama performance timings (default: false)<br/>(env: LLAMA_ARG_PERF) |
|
||||
| `-f, --file FNAME` | a file containing the prompt (default: none) |
|
||||
| `-bf, --binary-file FNAME` | binary file containing the prompt (default: none) |
|
||||
| `-e, --escape, --no-escape` | whether to process escapes sequences (\n, \r, \t, \', \", \\) (default: true) |
|
||||
| `--rope-scaling {none,linear,yarn}` | RoPE frequency scaling method, defaults to linear unless specified by the model<br/>(env: LLAMA_ARG_ROPE_SCALING_TYPE) |
|
||||
| `--rope-scale N` | RoPE context scaling factor, expands context by a factor of N<br/>(env: LLAMA_ARG_ROPE_SCALE) |
|
||||
| `--rope-freq-base N` | RoPE base frequency, used by NTK-aware scaling (default: loaded from model)<br/>(env: LLAMA_ARG_ROPE_FREQ_BASE) |
|
||||
| `--rope-freq-scale N` | RoPE frequency scaling factor, expands context by a factor of 1/N<br/>(env: LLAMA_ARG_ROPE_FREQ_SCALE) |
|
||||
| `--yarn-orig-ctx N` | YaRN: original context size of model (default: 0 = model training context size)<br/>(env: LLAMA_ARG_YARN_ORIG_CTX) |
|
||||
| `--yarn-ext-factor N` | YaRN: extrapolation mix factor (default: -1.0, 0.0 = full interpolation)<br/>(env: LLAMA_ARG_YARN_EXT_FACTOR) |
|
||||
| `--yarn-attn-factor N` | YaRN: scale sqrt(t) or attention magnitude (default: -1.0)<br/>(env: LLAMA_ARG_YARN_ATTN_FACTOR) |
|
||||
| `--yarn-beta-slow N` | YaRN: high correction dim or alpha (default: -1.0)<br/>(env: LLAMA_ARG_YARN_BETA_SLOW) |
|
||||
| `--yarn-beta-fast N` | YaRN: low correction dim or beta (default: -1.0)<br/>(env: LLAMA_ARG_YARN_BETA_FAST) |
|
||||
| `-kvo, --kv-offload, -nkvo, --no-kv-offload` | whether to enable KV cache offloading (default: enabled)<br/>(env: LLAMA_ARG_KV_OFFLOAD) |
|
||||
| `--repack, -nr, --no-repack` | whether to enable weight repacking (default: enabled)<br/>(env: LLAMA_ARG_REPACK) |
|
||||
| `--no-host` | bypass host buffer allowing extra buffers to be used<br/>(env: LLAMA_ARG_NO_HOST) |
|
||||
| `-ctk, --cache-type-k TYPE` | KV cache data type for K<br/>allowed values: f32, f16, bf16, q8_0, q4_0, q4_1, iq4_nl, q5_0, q5_1<br/>(default: f16)<br/>(env: LLAMA_ARG_CACHE_TYPE_K) |
|
||||
| `-ctv, --cache-type-v TYPE` | KV cache data type for V<br/>allowed values: f32, f16, bf16, q8_0, q4_0, q4_1, iq4_nl, q5_0, q5_1<br/>(default: f16)<br/>(env: LLAMA_ARG_CACHE_TYPE_V) |
|
||||
| `-dt, --defrag-thold N` | KV cache defragmentation threshold (DEPRECATED)<br/>(env: LLAMA_ARG_DEFRAG_THOLD) |
|
||||
| `-np, --parallel N` | number of parallel sequences to decode (default: 1)<br/>(env: LLAMA_ARG_N_PARALLEL) |
|
||||
| `--mlock` | force system to keep model in RAM rather than swapping or compressing<br/>(env: LLAMA_ARG_MLOCK) |
|
||||
| `--mmap, --no-mmap` | whether to memory-map model (if disabled, slower load but may reduce pageouts if not using mlock) (default: enabled)<br/>(env: LLAMA_ARG_MMAP) |
|
||||
| `--numa TYPE` | attempt optimizations that help on some NUMA systems<br/>- distribute: spread execution evenly over all nodes<br/>- isolate: only spawn threads on CPUs on the node that execution started on<br/>- numactl: use the CPU map provided by numactl<br/>if run without this previously, it is recommended to drop the system page cache before using this<br/>see https://github.com/ggml-org/llama.cpp/issues/1437<br/>(env: LLAMA_ARG_NUMA) |
|
||||
| `-dev, --device <dev1,dev2,..>` | comma-separated list of devices to use for offloading (none = don't offload)<br/>use --list-devices to see a list of available devices<br/>(env: LLAMA_ARG_DEVICE) |
|
||||
| `--list-devices` | print list of available devices and exit |
|
||||
| `-ot, --override-tensor <tensor name pattern>=<buffer type>,...` | override tensor buffer type |
|
||||
| `-cmoe, --cpu-moe` | keep all Mixture of Experts (MoE) weights in the CPU<br/>(env: LLAMA_ARG_CPU_MOE) |
|
||||
| `-ncmoe, --n-cpu-moe N` | keep the Mixture of Experts (MoE) weights of the first N layers in the CPU<br/>(env: LLAMA_ARG_N_CPU_MOE) |
|
||||
| `-ngl, --gpu-layers, --n-gpu-layers N` | max. number of layers to store in VRAM (default: -1)<br/>(env: LLAMA_ARG_N_GPU_LAYERS) |
|
||||
| `-sm, --split-mode {none,layer,row}` | how to split the model across multiple GPUs, one of:<br/>- none: use one GPU only<br/>- layer (default): split layers and KV across GPUs<br/>- row: split rows across GPUs<br/>(env: LLAMA_ARG_SPLIT_MODE) |
|
||||
| `-ts, --tensor-split N0,N1,N2,...` | fraction of the model to offload to each GPU, comma-separated list of proportions, e.g. 3,1<br/>(env: LLAMA_ARG_TENSOR_SPLIT) |
|
||||
| `-mg, --main-gpu INDEX` | the GPU to use for the model (with split-mode = none), or for intermediate results and KV (with split-mode = row) (default: 0)<br/>(env: LLAMA_ARG_MAIN_GPU) |
|
||||
| `-fit, --fit [on\|off]` | whether to adjust unset arguments to fit in device memory ('on' or 'off', default: 'on')<br/>(env: LLAMA_ARG_FIT) |
|
||||
| `-fitt, --fit-target MiB` | target margin per device for --fit option, default: 1024<br/>(env: LLAMA_ARG_FIT_TARGET) |
|
||||
| `-fitc, --fit-ctx N` | minimum ctx size that can be set by --fit option, default: 4096<br/>(env: LLAMA_ARG_FIT_CTX) |
|
||||
| `--check-tensors` | check model tensor data for invalid values (default: false) |
|
||||
| `--override-kv KEY=TYPE:VALUE,...` | advanced option to override model metadata by key. to specify multiple overrides, either use comma-separated or repeat this argument.<br/>types: int, float, bool, str. example: --override-kv tokenizer.ggml.add_bos_token=bool:false,tokenizer.ggml.add_eos_token=bool:false |
|
||||
| `--op-offload, --no-op-offload` | whether to offload host tensor operations to device (default: true) |
|
||||
| `--lora FNAME` | path to LoRA adapter (use comma-separated values to load multiple adapters) |
|
||||
| `--lora-scaled FNAME:SCALE,...` | path to LoRA adapter with user defined scaling (format: FNAME:SCALE,...)<br/>note: use comma-separated values |
|
||||
| `--control-vector FNAME` | add a control vector<br/>note: use comma-separated values to add multiple control vectors |
|
||||
| `--control-vector-scaled FNAME:SCALE,...` | add a control vector with user defined scaling SCALE<br/>note: use comma-separated values (format: FNAME:SCALE,...) |
|
||||
| `--control-vector-layer-range START END` | layer range to apply the control vector(s) to, start and end inclusive |
|
||||
| `-m, --model FNAME` | model path to load<br/>(env: LLAMA_ARG_MODEL) |
|
||||
| `-mu, --model-url MODEL_URL` | model download url (default: unused)<br/>(env: LLAMA_ARG_MODEL_URL) |
|
||||
| `-dr, --docker-repo [<repo>/]<model>[:quant]` | Docker Hub model repository. repo is optional, default to ai/. quant is optional, default to :latest.<br/>example: gemma3<br/>(default: unused)<br/>(env: LLAMA_ARG_DOCKER_REPO) |
|
||||
| `-hf, -hfr, --hf-repo <user>/<model>[:quant]` | Hugging Face model repository; quant is optional, case-insensitive, default to Q4_K_M, or falls back to the first file in the repo if Q4_K_M doesn't exist.<br/>mmproj is also downloaded automatically if available. to disable, add --no-mmproj<br/>example: unsloth/phi-4-GGUF:q4_k_m<br/>(default: unused)<br/>(env: LLAMA_ARG_HF_REPO) |
|
||||
| `-hfd, -hfrd, --hf-repo-draft <user>/<model>[:quant]` | Same as --hf-repo, but for the draft model (default: unused)<br/>(env: LLAMA_ARG_HFD_REPO) |
|
||||
| `-hff, --hf-file FILE` | Hugging Face model file. If specified, it will override the quant in --hf-repo (default: unused)<br/>(env: LLAMA_ARG_HF_FILE) |
|
||||
| `-hfv, -hfrv, --hf-repo-v <user>/<model>[:quant]` | Hugging Face model repository for the vocoder model (default: unused)<br/>(env: LLAMA_ARG_HF_REPO_V) |
|
||||
| `-hffv, --hf-file-v FILE` | Hugging Face model file for the vocoder model (default: unused)<br/>(env: LLAMA_ARG_HF_FILE_V) |
|
||||
| `-hft, --hf-token TOKEN` | Hugging Face access token (default: value from HF_TOKEN environment variable)<br/>(env: HF_TOKEN) |
|
||||
| `--log-disable` | Log disable |
|
||||
| `--log-file FNAME` | Log to file<br/>(env: LLAMA_LOG_FILE) |
|
||||
| `--log-colors [on\|off\|auto]` | Set colored logging ('on', 'off', or 'auto', default: 'auto')<br/>'auto' enables colors when output is to a terminal<br/>(env: LLAMA_LOG_COLORS) |
|
||||
| `-v, --verbose, --log-verbose` | Set verbosity level to infinity (i.e. log all messages, useful for debugging) |
|
||||
| `--offline` | Offline mode: forces use of cache, prevents network access<br/>(env: LLAMA_OFFLINE) |
|
||||
| `-lv, --verbosity, --log-verbosity N` | Set the verbosity threshold. Messages with a higher verbosity will be ignored. Values:<br/> - 0: generic output<br/> - 1: error<br/> - 2: warning<br/> - 3: info<br/> - 4: debug<br/>(default: 3)<br/><br/>(env: LLAMA_LOG_VERBOSITY) |
|
||||
| `--log-prefix` | Enable prefix in log messages<br/>(env: LLAMA_LOG_PREFIX) |
|
||||
| `--log-timestamps` | Enable timestamps in log messages<br/>(env: LLAMA_LOG_TIMESTAMPS) |
|
||||
| `-ctkd, --cache-type-k-draft TYPE` | KV cache data type for K for the draft model<br/>allowed values: f32, f16, bf16, q8_0, q4_0, q4_1, iq4_nl, q5_0, q5_1<br/>(default: f16)<br/>(env: LLAMA_ARG_CACHE_TYPE_K_DRAFT) |
|
||||
| `-ctvd, --cache-type-v-draft TYPE` | KV cache data type for V for the draft model<br/>allowed values: f32, f16, bf16, q8_0, q4_0, q4_1, iq4_nl, q5_0, q5_1<br/>(default: f16)<br/>(env: LLAMA_ARG_CACHE_TYPE_V_DRAFT) |
|
||||
|
||||
|
||||
### Sampling params
|
||||
|
||||
| Argument | Explanation |
|
||||
| -------- | ----------- |
|
||||
| `--samplers SAMPLERS` | samplers that will be used for generation in the order, separated by ';'<br/>(default: penalties;dry;top_n_sigma;top_k;typ_p;top_p;min_p;xtc;temperature) |
|
||||
| `-s, --seed SEED` | RNG seed (default: -1, use random seed for -1) |
|
||||
| `--sampler-seq, --sampling-seq SEQUENCE` | simplified sequence for samplers that will be used (default: edskypmxt) |
|
||||
| `--ignore-eos` | ignore end of stream token and continue generating (implies --logit-bias EOS-inf) |
|
||||
| `--temp N` | temperature (default: 0.8) |
|
||||
| `--top-k N` | top-k sampling (default: 40, 0 = disabled)<br/>(env: LLAMA_ARG_TOP_K) |
|
||||
| `--top-p N` | top-p sampling (default: 0.9, 1.0 = disabled) |
|
||||
| `--min-p N` | min-p sampling (default: 0.1, 0.0 = disabled) |
|
||||
| `--top-nsigma N` | top-n-sigma sampling (default: -1.0, -1.0 = disabled) |
|
||||
| `--xtc-probability N` | xtc probability (default: 0.0, 0.0 = disabled) |
|
||||
| `--xtc-threshold N` | xtc threshold (default: 0.1, 1.0 = disabled) |
|
||||
| `--typical N` | locally typical sampling, parameter p (default: 1.0, 1.0 = disabled) |
|
||||
| `--repeat-last-n N` | last n tokens to consider for penalize (default: 64, 0 = disabled, -1 = ctx_size) |
|
||||
| `--repeat-penalty N` | penalize repeat sequence of tokens (default: 1.0, 1.0 = disabled) |
|
||||
| `--presence-penalty N` | repeat alpha presence penalty (default: 0.0, 0.0 = disabled) |
|
||||
| `--frequency-penalty N` | repeat alpha frequency penalty (default: 0.0, 0.0 = disabled) |
|
||||
| `--dry-multiplier N` | set DRY sampling multiplier (default: 0.0, 0.0 = disabled) |
|
||||
| `--dry-base N` | set DRY sampling base value (default: 1.75) |
|
||||
| `--dry-allowed-length N` | set allowed length for DRY sampling (default: 2) |
|
||||
| `--dry-penalty-last-n N` | set DRY penalty for the last n tokens (default: -1, 0 = disable, -1 = context size) |
|
||||
| `--dry-sequence-breaker STRING` | add sequence breaker for DRY sampling, clearing out default breakers ('\n', ':', '"', '*') in the process; use "none" to not use any sequence breakers |
|
||||
| `--dynatemp-range N` | dynamic temperature range (default: 0.0, 0.0 = disabled) |
|
||||
| `--dynatemp-exp N` | dynamic temperature exponent (default: 1.0) |
|
||||
| `--mirostat N` | use Mirostat sampling.<br/>Top K, Nucleus and Locally Typical samplers are ignored if used.<br/>(default: 0, 0 = disabled, 1 = Mirostat, 2 = Mirostat 2.0) |
|
||||
| `--mirostat-lr N` | Mirostat learning rate, parameter eta (default: 0.1) |
|
||||
| `--mirostat-ent N` | Mirostat target entropy, parameter tau (default: 5.0) |
|
||||
| `-l, --logit-bias TOKEN_ID(+/-)BIAS` | modifies the likelihood of token appearing in the completion,<br/>i.e. `--logit-bias 15043+1` to increase likelihood of token ' Hello',<br/>or `--logit-bias 15043-1` to decrease likelihood of token ' Hello' |
|
||||
| `--grammar GRAMMAR` | BNF-like grammar to constrain generations (see samples in grammars/ dir) (default: '') |
|
||||
| `--grammar-file FNAME` | file to read grammar from |
|
||||
| `-j, --json-schema SCHEMA` | JSON schema to constrain generations (https://json-schema.org/), e.g. `{}` for any JSON object<br/>For schemas w/ external $refs, use --grammar + example/json_schema_to_grammar.py instead |
|
||||
| `-jf, --json-schema-file FILE` | File containing a JSON schema to constrain generations (https://json-schema.org/), e.g. `{}` for any JSON object<br/>For schemas w/ external $refs, use --grammar + example/json_schema_to_grammar.py instead |
|
||||
|
||||
|
||||
### Completion-specific params
|
||||
|
||||
| Argument | Explanation |
|
||||
| -------- | ----------- |
|
||||
| `--display-prompt, --no-display-prompt` | whether to print prompt at generation (default: true) |
|
||||
| `-co, --color [on\|off\|auto]` | Colorize output to distinguish prompt and user input from generations ('on', 'off', or 'auto', default: 'auto')<br/>'auto' enables colors when output is to a terminal |
|
||||
| `--context-shift, --no-context-shift` | whether to use context shift on infinite text generation (default: disabled)<br/>(env: LLAMA_ARG_CONTEXT_SHIFT) |
|
||||
| `-sys, --system-prompt PROMPT` | system prompt to use with model (if applicable, depending on chat template) |
|
||||
| `-sysf, --system-prompt-file FNAME` | a file containing the system prompt (default: none) |
|
||||
| `-ptc, --print-token-count N` | print token count every N tokens (default: -1) |
|
||||
| `--prompt-cache FNAME` | file to cache prompt state for faster startup (default: none) |
|
||||
| `--prompt-cache-all` | if specified, saves user input and generations to cache as well |
|
||||
| `--prompt-cache-ro` | if specified, uses the prompt cache but does not update it |
|
||||
| `-r, --reverse-prompt PROMPT` | halt generation at PROMPT, return control in interactive mode |
|
||||
| `-sp, --special` | special tokens output enabled (default: false) |
|
||||
| `-cnv, --conversation, -no-cnv, --no-conversation` | whether to run in conversation mode:<br/>- does not print special tokens and suffix/prefix<br/>- interactive mode is also enabled<br/>(default: auto enabled if chat template is available) |
|
||||
| `-st, --single-turn` | run conversation for a single turn only, then exit when done<br/>will not be interactive if first turn is predefined with --prompt<br/>(default: false) |
|
||||
| `-i, --interactive` | run in interactive mode (default: false) |
|
||||
| `-if, --interactive-first` | run in interactive mode and wait for input right away (default: false) |
|
||||
| `-mli, --multiline-input` | allows you to write or paste multiple lines without ending each in '\' |
|
||||
| `--in-prefix-bos` | prefix BOS to user inputs, preceding the `--in-prefix` string |
|
||||
| `--in-prefix STRING` | string to prefix user inputs with (default: empty) |
|
||||
| `--in-suffix STRING` | string to suffix after user inputs with (default: empty) |
|
||||
| `--warmup, --no-warmup` | whether to perform warmup with an empty run (default: enabled) |
|
||||
| `-gan, --grp-attn-n N` | group-attention factor (default: 1)<br/>(env: LLAMA_ARG_GRP_ATTN_N) |
|
||||
| `-gaw, --grp-attn-w N` | group-attention width (default: 512)<br/>(env: LLAMA_ARG_GRP_ATTN_W) |
|
||||
| `--jinja, --no-jinja` | whether to use jinja template engine for chat (default: disabled)<br/>(env: LLAMA_ARG_JINJA) |
|
||||
| `--reasoning-format FORMAT` | controls whether thought tags are allowed and/or extracted from the response, and in which format they're returned; one of:<br/>- none: leaves thoughts unparsed in `message.content`<br/>- deepseek: puts thoughts in `message.reasoning_content`<br/>- deepseek-legacy: keeps `<think>` tags in `message.content` while also populating `message.reasoning_content`<br/>(default: auto)<br/>(env: LLAMA_ARG_THINK) |
|
||||
| `--reasoning-budget N` | controls the amount of thinking allowed; currently only one of: -1 for unrestricted thinking budget, or 0 to disable thinking (default: -1)<br/>(env: LLAMA_ARG_THINK_BUDGET) |
|
||||
| `--chat-template JINJA_TEMPLATE` | set custom jinja chat template (default: template taken from model's metadata)<br/>if suffix/prefix are specified, template will be disabled<br/>only commonly used templates are accepted (unless --jinja is set before this flag):<br/>list of built-in templates:<br/>bailing, bailing-think, bailing2, chatglm3, chatglm4, chatml, command-r, deepseek, deepseek2, deepseek3, exaone3, exaone4, falcon3, gemma, gigachat, glmedge, gpt-oss, granite, grok-2, hunyuan-dense, hunyuan-moe, kimi-k2, llama2, llama2-sys, llama2-sys-bos, llama2-sys-strip, llama3, llama4, megrez, minicpm, mistral-v1, mistral-v3, mistral-v3-tekken, mistral-v7, mistral-v7-tekken, monarch, openchat, orion, pangu-embedded, phi3, phi4, rwkv-world, seed_oss, smolvlm, vicuna, vicuna-orca, yandex, zephyr<br/>(env: LLAMA_ARG_CHAT_TEMPLATE) |
|
||||
| `--chat-template-file JINJA_TEMPLATE_FILE` | set custom jinja chat template file (default: template taken from model's metadata)<br/>if suffix/prefix are specified, template will be disabled<br/>only commonly used templates are accepted (unless --jinja is set before this flag):<br/>list of built-in templates:<br/>bailing, bailing-think, bailing2, chatglm3, chatglm4, chatml, command-r, deepseek, deepseek2, deepseek3, exaone3, exaone4, falcon3, gemma, gigachat, glmedge, gpt-oss, granite, grok-2, hunyuan-dense, hunyuan-moe, kimi-k2, llama2, llama2-sys, llama2-sys-bos, llama2-sys-strip, llama3, llama4, megrez, minicpm, mistral-v1, mistral-v3, mistral-v3-tekken, mistral-v7, mistral-v7-tekken, monarch, openchat, orion, pangu-embedded, phi3, phi4, rwkv-world, seed_oss, smolvlm, vicuna, vicuna-orca, yandex, zephyr<br/>(env: LLAMA_ARG_CHAT_TEMPLATE_FILE) |
|
||||
| `--simple-io` | use basic IO for better compatibility in subprocesses and limited consoles |
|
||||
|
||||
<!-- HELP_END -->
|
||||
|
||||
## Common Options
|
||||
|
||||
In this section, we cover the most commonly used options for running the `llama-completion` program with the LLaMA models:
|
||||
|
||||
@@ -2102,6 +2102,8 @@ int main(int argc, char ** argv) {
|
||||
struct ggml_threadpool_params tpp = ggml_threadpool_params_default(t.n_threads);
|
||||
if (!parse_cpu_mask(t.cpu_mask, tpp.cpumask)) {
|
||||
fprintf(stderr, "%s: failed to parse cpu-mask: %s\n", __func__, t.cpu_mask.c_str());
|
||||
llama_free(ctx);
|
||||
llama_model_free(lmodel);
|
||||
exit(1);
|
||||
}
|
||||
tpp.strict_cpu = t.cpu_strict;
|
||||
@@ -2111,6 +2113,8 @@ int main(int argc, char ** argv) {
|
||||
struct ggml_threadpool * threadpool = ggml_threadpool_new_fn(&tpp);
|
||||
if (!threadpool) {
|
||||
fprintf(stderr, "%s: threadpool create failed : n_threads %d\n", __func__, tpp.n_threads);
|
||||
llama_free(ctx);
|
||||
llama_model_free(lmodel);
|
||||
exit(1);
|
||||
}
|
||||
|
||||
@@ -2126,6 +2130,8 @@ int main(int argc, char ** argv) {
|
||||
bool res = test_prompt(ctx, t.n_prompt, t.n_batch, t.n_threads);
|
||||
if (!res) {
|
||||
fprintf(stderr, "%s: error: failed to run prompt warmup\n", __func__);
|
||||
llama_free(ctx);
|
||||
llama_model_free(lmodel);
|
||||
exit(1);
|
||||
}
|
||||
}
|
||||
@@ -2136,6 +2142,8 @@ int main(int argc, char ** argv) {
|
||||
bool res = test_gen(ctx, 1, t.n_threads);
|
||||
if (!res) {
|
||||
fprintf(stderr, "%s: error: failed to run gen warmup\n", __func__);
|
||||
llama_free(ctx);
|
||||
llama_model_free(lmodel);
|
||||
exit(1);
|
||||
}
|
||||
}
|
||||
@@ -2164,6 +2172,8 @@ int main(int argc, char ** argv) {
|
||||
bool res = test_prompt(ctx, t.n_depth, t.n_batch, t.n_threads);
|
||||
if (!res) {
|
||||
fprintf(stderr, "%s: error: failed to run depth\n", __func__);
|
||||
llama_free(ctx);
|
||||
llama_model_free(lmodel);
|
||||
exit(1);
|
||||
}
|
||||
|
||||
@@ -2189,6 +2199,8 @@ int main(int argc, char ** argv) {
|
||||
bool res = test_prompt(ctx, t.n_prompt, t.n_batch, t.n_threads);
|
||||
if (!res) {
|
||||
fprintf(stderr, "%s: error: failed to run prompt\n", __func__);
|
||||
llama_free(ctx);
|
||||
llama_model_free(lmodel);
|
||||
exit(1);
|
||||
}
|
||||
}
|
||||
@@ -2200,6 +2212,8 @@ int main(int argc, char ** argv) {
|
||||
bool res = test_gen(ctx, t.n_gen, t.n_threads);
|
||||
if (!res) {
|
||||
fprintf(stderr, "%s: error: failed to run gen\n", __func__);
|
||||
llama_free(ctx);
|
||||
llama_model_free(lmodel);
|
||||
exit(1);
|
||||
}
|
||||
}
|
||||
|
||||
@@ -107,6 +107,8 @@ For detailed instructions, see the [test documentation](./tests/README.md).
|
||||
- Large-scale code base split into smaller files: https://github.com/ggml-org/llama.cpp/pull/17362
|
||||
- Introduction of router mode: https://github.com/ggml-org/llama.cpp/pull/17470
|
||||
- Speculative decoding: https://github.com/ggml-org/llama.cpp/pull/17808 and rework in https://github.com/ggml-org/llama.cpp/pull/17808
|
||||
- INI presets: https://github.com/ggml-org/llama.cpp/pull/17859 (+ refactoring: https://github.com/ggml-org/llama.cpp/pull/18169)
|
||||
- Sleeping mode: https://github.com/ggml-org/llama.cpp/pull/18228
|
||||
|
||||
|
||||
|
||||
|
||||
+52
-25
@@ -23,9 +23,11 @@ For the ful list of features, please refer to [server's changelog](https://githu
|
||||
|
||||
## Usage
|
||||
|
||||
<!-- Note for contributors: The list below is generated by llama-gen-docs -->
|
||||
<!-- HELP_START -->
|
||||
|
||||
**Common params**
|
||||
<!-- IMPORTANT: The list below is auto-generated by llama-gen-docs; do NOT modify it manually -->
|
||||
|
||||
### Common params
|
||||
|
||||
| Argument | Explanation |
|
||||
| -------- | ----------- |
|
||||
@@ -38,13 +40,13 @@ For the ful list of features, please refer to [server's changelog](https://githu
|
||||
| `-tb, --threads-batch N` | number of threads to use during batch and prompt processing (default: same as --threads) |
|
||||
| `-C, --cpu-mask M` | CPU affinity mask: arbitrarily long hex. Complements cpu-range (default: "") |
|
||||
| `-Cr, --cpu-range lo-hi` | range of CPUs for affinity. Complements --cpu-mask |
|
||||
| `--cpu-strict <0\|1>` | use strict CPU placement (default: 0)<br/> |
|
||||
| `--prio N` | set process/thread priority : low(-1), normal(0), medium(1), high(2), realtime(3) (default: 0)<br/> |
|
||||
| `--poll <0...100>` | use polling level to wait for work (0 - no polling, default: 50)<br/> |
|
||||
| `--cpu-strict <0\|1>` | use strict CPU placement (default: 0) |
|
||||
| `--prio N` | set process/thread priority : low(-1), normal(0), medium(1), high(2), realtime(3) (default: 0) |
|
||||
| `--poll <0...100>` | use polling level to wait for work (0 - no polling, default: 50) |
|
||||
| `-Cb, --cpu-mask-batch M` | CPU affinity mask: arbitrarily long hex. Complements cpu-range-batch (default: same as --cpu-mask) |
|
||||
| `-Crb, --cpu-range-batch lo-hi` | ranges of CPUs for affinity. Complements --cpu-mask-batch |
|
||||
| `--cpu-strict-batch <0\|1>` | use strict CPU placement (default: same as --cpu-strict) |
|
||||
| `--prio-batch N` | set process/thread priority : 0-normal, 1-medium, 2-high, 3-realtime (default: 0)<br/> |
|
||||
| `--prio-batch N` | set process/thread priority : 0-normal, 1-medium, 2-high, 3-realtime (default: 0) |
|
||||
| `--poll-batch <0\|1>` | use polling to wait for work (default: same as --poll) |
|
||||
| `-c, --ctx-size N` | size of the prompt context (default: 0, 0 = loaded from model)<br/>(env: LLAMA_ARG_CTX_SIZE) |
|
||||
| `-n, --predict, --n-predict N` | number of tokens to predict (default: -1, -1 = infinity)<br/>(env: LLAMA_ARG_N_PREDICT) |
|
||||
@@ -75,9 +77,9 @@ For the ful list of features, please refer to [server's changelog](https://githu
|
||||
| `--numa TYPE` | attempt optimizations that help on some NUMA systems<br/>- distribute: spread execution evenly over all nodes<br/>- isolate: only spawn threads on CPUs on the node that execution started on<br/>- numactl: use the CPU map provided by numactl<br/>if run without this previously, it is recommended to drop the system page cache before using this<br/>see https://github.com/ggml-org/llama.cpp/issues/1437<br/>(env: LLAMA_ARG_NUMA) |
|
||||
| `-dev, --device <dev1,dev2,..>` | comma-separated list of devices to use for offloading (none = don't offload)<br/>use --list-devices to see a list of available devices<br/>(env: LLAMA_ARG_DEVICE) |
|
||||
| `--list-devices` | print list of available devices and exit |
|
||||
| `--override-tensor, -ot <tensor name pattern>=<buffer type>,...` | override tensor buffer type |
|
||||
| `--cpu-moe, -cmoe` | keep all Mixture of Experts (MoE) weights in the CPU<br/>(env: LLAMA_ARG_CPU_MOE) |
|
||||
| `--n-cpu-moe, -ncmoe N` | keep the Mixture of Experts (MoE) weights of the first N layers in the CPU<br/>(env: LLAMA_ARG_N_CPU_MOE) |
|
||||
| `-ot, --override-tensor <tensor name pattern>=<buffer type>,...` | override tensor buffer type |
|
||||
| `-cmoe, --cpu-moe` | keep all Mixture of Experts (MoE) weights in the CPU<br/>(env: LLAMA_ARG_CPU_MOE) |
|
||||
| `-ncmoe, --n-cpu-moe N` | keep the Mixture of Experts (MoE) weights of the first N layers in the CPU<br/>(env: LLAMA_ARG_N_CPU_MOE) |
|
||||
| `-ngl, --gpu-layers, --n-gpu-layers N` | max. number of layers to store in VRAM (default: -1)<br/>(env: LLAMA_ARG_N_GPU_LAYERS) |
|
||||
| `-sm, --split-mode {none,layer,row}` | how to split the model across multiple GPUs, one of:<br/>- none: use one GPU only<br/>- layer (default): split layers and KV across GPUs<br/>- row: split rows across GPUs<br/>(env: LLAMA_ARG_SPLIT_MODE) |
|
||||
| `-ts, --tensor-split N0,N1,N2,...` | fraction of the model to offload to each GPU, comma-separated list of proportions, e.g. 3,1<br/>(env: LLAMA_ARG_TENSOR_SPLIT) |
|
||||
@@ -114,13 +116,13 @@ For the ful list of features, please refer to [server's changelog](https://githu
|
||||
| `-ctvd, --cache-type-v-draft TYPE` | KV cache data type for V for the draft model<br/>allowed values: f32, f16, bf16, q8_0, q4_0, q4_1, iq4_nl, q5_0, q5_1<br/>(default: f16)<br/>(env: LLAMA_ARG_CACHE_TYPE_V_DRAFT) |
|
||||
|
||||
|
||||
**Sampling params**
|
||||
### Sampling params
|
||||
|
||||
| Argument | Explanation |
|
||||
| -------- | ----------- |
|
||||
| `--samplers SAMPLERS` | samplers that will be used for generation in the order, separated by ';'<br/>(default: penalties;dry;top_n_sigma;top_k;typ_p;top_p;min_p;xtc;temperature) |
|
||||
| `-s, --seed SEED` | RNG seed (default: -1, use random seed for -1) |
|
||||
| `--sampling-seq, --sampler-seq SEQUENCE` | simplified sequence for samplers that will be used (default: edskypmxt) |
|
||||
| `--sampler-seq, --sampling-seq SEQUENCE` | simplified sequence for samplers that will be used (default: edskypmxt) |
|
||||
| `--ignore-eos` | ignore end of stream token and continue generating (implies --logit-bias EOS-inf) |
|
||||
| `--temp N` | temperature (default: 0.8) |
|
||||
| `--top-k N` | top-k sampling (default: 40, 0 = disabled)<br/>(env: LLAMA_ARG_TOP_K) |
|
||||
@@ -138,7 +140,7 @@ For the ful list of features, please refer to [server's changelog](https://githu
|
||||
| `--dry-base N` | set DRY sampling base value (default: 1.75) |
|
||||
| `--dry-allowed-length N` | set allowed length for DRY sampling (default: 2) |
|
||||
| `--dry-penalty-last-n N` | set DRY penalty for the last n tokens (default: -1, 0 = disable, -1 = context size) |
|
||||
| `--dry-sequence-breaker STRING` | add sequence breaker for DRY sampling, clearing out default breakers ('\n', ':', '"', '*') in the process; use "none" to not use any sequence breakers<br/> |
|
||||
| `--dry-sequence-breaker STRING` | add sequence breaker for DRY sampling, clearing out default breakers ('\n', ':', '"', '*') in the process; use "none" to not use any sequence breakers |
|
||||
| `--dynatemp-range N` | dynamic temperature range (default: 0.0, 0.0 = disabled) |
|
||||
| `--dynatemp-exp N` | dynamic temperature exponent (default: 1.0) |
|
||||
| `--mirostat N` | use Mirostat sampling.<br/>Top K, Nucleus and Locally Typical samplers are ignored if used.<br/>(default: 0, 0 = disabled, 1 = Mirostat, 2 = Mirostat 2.0) |
|
||||
@@ -151,15 +153,15 @@ For the ful list of features, please refer to [server's changelog](https://githu
|
||||
| `-jf, --json-schema-file FILE` | File containing a JSON schema to constrain generations (https://json-schema.org/), e.g. `{}` for any JSON object<br/>For schemas w/ external $refs, use --grammar + example/json_schema_to_grammar.py instead |
|
||||
|
||||
|
||||
**Server-specific params**
|
||||
### Server-specific params
|
||||
|
||||
| Argument | Explanation |
|
||||
| -------- | ----------- |
|
||||
| `--ctx-checkpoints, --swa-checkpoints N` | max number of context checkpoints to create per slot (default: 8)[(more info)](https://github.com/ggml-org/llama.cpp/pull/15293)<br/>(env: LLAMA_ARG_CTX_CHECKPOINTS) |
|
||||
| `--cache-ram, -cram N` | set the maximum cache size in MiB (default: 8192, -1 - no limit, 0 - disable)[(more info)](https://github.com/ggml-org/llama.cpp/pull/16391)<br/>(env: LLAMA_ARG_CACHE_RAM) |
|
||||
| `--kv-unified, -kvu` | use single unified KV buffer shared across all sequences (default: enabled if number of slots is auto)<br/>(env: LLAMA_ARG_KV_UNIFIED) |
|
||||
| `-cram, --cache-ram N` | set the maximum cache size in MiB (default: 8192, -1 - no limit, 0 - disable)[(more info)](https://github.com/ggml-org/llama.cpp/pull/16391)<br/>(env: LLAMA_ARG_CACHE_RAM) |
|
||||
| `-kvu, --kv-unified` | use single unified KV buffer shared across all sequences (default: enabled if number of slots is auto)<br/>(env: LLAMA_ARG_KV_UNIFIED) |
|
||||
| `--context-shift, --no-context-shift` | whether to use context shift on infinite text generation (default: disabled)<br/>(env: LLAMA_ARG_CONTEXT_SHIFT) |
|
||||
| `-r, --reverse-prompt PROMPT` | halt generation at PROMPT, return control in interactive mode<br/> |
|
||||
| `-r, --reverse-prompt PROMPT` | halt generation at PROMPT, return control in interactive mode |
|
||||
| `-sp, --special` | special tokens output enabled (default: false) |
|
||||
| `--warmup, --no-warmup` | whether to perform warmup with an empty run (default: enabled) |
|
||||
| `--spm-infill` | use Suffix/Prefix/Middle pattern for infill (instead of Prefix/Suffix/Middle) as some models prefer this. (default: disabled) |
|
||||
@@ -172,9 +174,9 @@ For the ful list of features, please refer to [server's changelog](https://githu
|
||||
| `--mmproj-offload, --no-mmproj-offload` | whether to enable GPU offloading for multimodal projector (default: enabled)<br/>(env: LLAMA_ARG_MMPROJ_OFFLOAD) |
|
||||
| `--image-min-tokens N` | minimum number of tokens each image can take, only used by vision models with dynamic resolution (default: read from model)<br/>(env: LLAMA_ARG_IMAGE_MIN_TOKENS) |
|
||||
| `--image-max-tokens N` | maximum number of tokens each image can take, only used by vision models with dynamic resolution (default: read from model)<br/>(env: LLAMA_ARG_IMAGE_MAX_TOKENS) |
|
||||
| `--override-tensor-draft, -otd <tensor name pattern>=<buffer type>,...` | override tensor buffer type for draft model |
|
||||
| `--cpu-moe-draft, -cmoed` | keep all Mixture of Experts (MoE) weights in the CPU for the draft model<br/>(env: LLAMA_ARG_CPU_MOE_DRAFT) |
|
||||
| `--n-cpu-moe-draft, -ncmoed N` | keep the Mixture of Experts (MoE) weights of the first N layers in the CPU for the draft model<br/>(env: LLAMA_ARG_N_CPU_MOE_DRAFT) |
|
||||
| `-otd, --override-tensor-draft <tensor name pattern>=<buffer type>,...` | override tensor buffer type for draft model |
|
||||
| `-cmoed, --cpu-moe-draft` | keep all Mixture of Experts (MoE) weights in the CPU for the draft model<br/>(env: LLAMA_ARG_CPU_MOE_DRAFT) |
|
||||
| `-ncmoed, --n-cpu-moe-draft N` | keep the Mixture of Experts (MoE) weights of the first N layers in the CPU for the draft model<br/>(env: LLAMA_ARG_N_CPU_MOE_DRAFT) |
|
||||
| `-a, --alias STRING` | set alias for model name (to be used by REST API)<br/>(env: LLAMA_ARG_ALIAS) |
|
||||
| `--host HOST` | ip address to listen, or bind to an UNIX socket if the address ends with .sock (default: 127.0.0.1)<br/>(env: LLAMA_ARG_HOST) |
|
||||
| `--port PORT` | port to listen (default: 8080)<br/>(env: LLAMA_ARG_PORT) |
|
||||
@@ -184,7 +186,7 @@ For the ful list of features, please refer to [server's changelog](https://githu
|
||||
| `--webui-config-file PATH` | JSON file that provides default WebUI settings (overrides WebUI defaults)<br/>(env: LLAMA_ARG_WEBUI_CONFIG_FILE) |
|
||||
| `--webui, --no-webui` | whether to enable the Web UI (default: enabled)<br/>(env: LLAMA_ARG_WEBUI) |
|
||||
| `--embedding, --embeddings` | restrict to only support embedding use case; use only with dedicated embedding models (default: disabled)<br/>(env: LLAMA_ARG_EMBEDDINGS) |
|
||||
| `--reranking, --rerank` | enable reranking endpoint on server (default: disabled)<br/>(env: LLAMA_ARG_RERANKING) |
|
||||
| `--rerank, --reranking` | enable reranking endpoint on server (default: disabled)<br/>(env: LLAMA_ARG_RERANKING) |
|
||||
| `--api-key KEY` | API key to use for authentication (default: none)<br/>(env: LLAMA_API_KEY) |
|
||||
| `--api-key-file FNAME` | path to file containing API keys (default: none) |
|
||||
| `--ssl-key-file FNAME` | path to file a PEM-encoded SSL private key<br/>(env: LLAMA_ARG_SSL_KEY_FILE) |
|
||||
@@ -208,11 +210,12 @@ For the ful list of features, please refer to [server's changelog](https://githu
|
||||
| `--chat-template JINJA_TEMPLATE` | set custom jinja chat template (default: template taken from model's metadata)<br/>if suffix/prefix are specified, template will be disabled<br/>only commonly used templates are accepted (unless --jinja is set before this flag):<br/>list of built-in templates:<br/>bailing, bailing-think, bailing2, chatglm3, chatglm4, chatml, command-r, deepseek, deepseek2, deepseek3, exaone3, exaone4, falcon3, gemma, gigachat, glmedge, gpt-oss, granite, grok-2, hunyuan-dense, hunyuan-moe, kimi-k2, llama2, llama2-sys, llama2-sys-bos, llama2-sys-strip, llama3, llama4, megrez, minicpm, mistral-v1, mistral-v3, mistral-v3-tekken, mistral-v7, mistral-v7-tekken, monarch, openchat, orion, pangu-embedded, phi3, phi4, rwkv-world, seed_oss, smolvlm, vicuna, vicuna-orca, yandex, zephyr<br/>(env: LLAMA_ARG_CHAT_TEMPLATE) |
|
||||
| `--chat-template-file JINJA_TEMPLATE_FILE` | set custom jinja chat template file (default: template taken from model's metadata)<br/>if suffix/prefix are specified, template will be disabled<br/>only commonly used templates are accepted (unless --jinja is set before this flag):<br/>list of built-in templates:<br/>bailing, bailing-think, bailing2, chatglm3, chatglm4, chatml, command-r, deepseek, deepseek2, deepseek3, exaone3, exaone4, falcon3, gemma, gigachat, glmedge, gpt-oss, granite, grok-2, hunyuan-dense, hunyuan-moe, kimi-k2, llama2, llama2-sys, llama2-sys-bos, llama2-sys-strip, llama3, llama4, megrez, minicpm, mistral-v1, mistral-v3, mistral-v3-tekken, mistral-v7, mistral-v7-tekken, monarch, openchat, orion, pangu-embedded, phi3, phi4, rwkv-world, seed_oss, smolvlm, vicuna, vicuna-orca, yandex, zephyr<br/>(env: LLAMA_ARG_CHAT_TEMPLATE_FILE) |
|
||||
| `--prefill-assistant, --no-prefill-assistant` | whether to prefill the assistant's response if the last message is an assistant message (default: prefill enabled)<br/>when this flag is set, if the last message is an assistant message then it will be treated as a full message and not prefilled<br/><br/>(env: LLAMA_ARG_PREFILL_ASSISTANT) |
|
||||
| `-sps, --slot-prompt-similarity SIMILARITY` | how much the prompt of a request must match the prompt of a slot in order to use that slot (default: 0.10, 0.0 = disabled)<br/> |
|
||||
| `-sps, --slot-prompt-similarity SIMILARITY` | how much the prompt of a request must match the prompt of a slot in order to use that slot (default: 0.10, 0.0 = disabled) |
|
||||
| `--lora-init-without-apply` | load LoRA adapters without applying them (apply later via POST /lora-adapters) (default: disabled) |
|
||||
| `--sleep-idle-seconds SECONDS` | number of seconds of idleness after which the server will sleep (default: -1; -1 = disabled) |
|
||||
| `-td, --threads-draft N` | number of threads to use during generation (default: same as --threads) |
|
||||
| `-tbd, --threads-batch-draft N` | number of threads to use during batch and prompt processing (default: same as --threads-draft) |
|
||||
| `--draft-max, --draft, --draft-n N` | number of tokens to draft for speculative decoding (default: 16)<br/>(env: LLAMA_ARG_DRAFT_MAX) |
|
||||
| `--draft, --draft-n, --draft-max N` | number of tokens to draft for speculative decoding (default: 16)<br/>(env: LLAMA_ARG_DRAFT_MAX) |
|
||||
| `--draft-min, --draft-n-min N` | minimum number of draft tokens to use for speculative decoding (default: 0)<br/>(env: LLAMA_ARG_DRAFT_MIN) |
|
||||
| `--draft-p-min P` | minimum speculative decoding probability (greedy) (default: 0.8)<br/>(env: LLAMA_ARG_DRAFT_P_MIN) |
|
||||
| `-cd, --ctx-size-draft N` | size of the prompt context for the draft model (default: 0, 0 = loaded from model)<br/>(env: LLAMA_ARG_CTX_SIZE_DRAFT) |
|
||||
@@ -234,6 +237,7 @@ For the ful list of features, please refer to [server's changelog](https://githu
|
||||
| `--vision-gemma-4b-default` | use Gemma 3 4B QAT (note: can download weights from the internet) |
|
||||
| `--vision-gemma-12b-default` | use Gemma 3 12B QAT (note: can download weights from the internet) |
|
||||
|
||||
<!-- HELP_END -->
|
||||
|
||||
Note: If both command line argument and environment variable are both set for the same param, the argument will take precedence over env var.
|
||||
|
||||
@@ -1443,6 +1447,12 @@ Example:
|
||||
```ini
|
||||
version = 1
|
||||
|
||||
; (Optional) This section provides global settings shared across all presets.
|
||||
; If the same key is defined in a specific preset, it will override the value in this global section.
|
||||
[*]
|
||||
c = 8192
|
||||
n-gpu-layer = 8
|
||||
|
||||
; If the key corresponds to an existing model on the server,
|
||||
; this will be used as the default config for that model
|
||||
[ggml-org/MY-MODEL-GGUF:Q8_0]
|
||||
@@ -1462,12 +1472,20 @@ model-draft = ./my-models/draft.gguf
|
||||
model-draft = /Users/abc/my-models/draft.gguf
|
||||
|
||||
; If the key does NOT correspond to an existing model,
|
||||
; you need to specify at least the model path
|
||||
; you need to specify at least the model path or HF repo
|
||||
[custom_model]
|
||||
model = /Users/abc/my-awesome-model-Q4_K_M.gguf
|
||||
```
|
||||
|
||||
Note: some arguments are controlled by router (e.g., host, port, API key, HF repo, model alias). They will be removed or overwritten upload loading.
|
||||
Note: some arguments are controlled by router (e.g., host, port, API key, HF repo, model alias). They will be removed or overwritten upon loading.
|
||||
|
||||
The precedence rule for preset options is as follows:
|
||||
1. **Command-line arguments** passed to `llama-server` (highest priority)
|
||||
2. **Model-specific options** defined in the preset file (e.g. `[ggml-org/MY-MODEL...]`)
|
||||
3. **Global options** defined in the preset file (`[*]`)
|
||||
|
||||
We also offer additional options that are exclusive to presets (these aren't treated as command-line arguments):
|
||||
- `load-on-startup` (boolean): Controls whether the model loads automatically when the server starts
|
||||
|
||||
### Routing requests
|
||||
|
||||
@@ -1553,7 +1571,6 @@ Load a model
|
||||
|
||||
Payload:
|
||||
- `model`: name of the model to be loaded.
|
||||
- `extra_args`: (optional) an array of additional arguments to be passed to the model instance. Note: you must start the server with `--models-allow-extra-args` to enable this feature.
|
||||
|
||||
```json
|
||||
{
|
||||
@@ -1607,6 +1624,16 @@ Example of an error:
|
||||
}
|
||||
```
|
||||
|
||||
## Sleeping on Idle
|
||||
|
||||
The server supports an automatic sleep mode that activates after a specified period of inactivity (no incoming tasks). This feature, introduced in [PR #18228](https://github.com/ggml-org/llama.cpp/pull/18228), can be enabled using the `--sleep-idle-seconds` command-line argument. It works seamlessly in both single-model and multi-model configurations.
|
||||
|
||||
When the server enters sleep mode, the model and its associated memory (including the KV cache) are unloaded from RAM to conserve resources. Any new incoming task will automatically trigger the model to reload.
|
||||
|
||||
Note that the following endpoints are exempt from being considered as incoming tasks. They do not trigger model reloading and do not reset the idle timer:
|
||||
- `GET /health`
|
||||
- `GET /props`
|
||||
|
||||
## More examples
|
||||
|
||||
### Interactive mode
|
||||
|
||||
Binary file not shown.
@@ -115,26 +115,14 @@ bool lora_should_clear_cache(
|
||||
!lora_all_alora(next));
|
||||
}
|
||||
|
||||
std::vector<common_adapter_lora_info> parse_lora_request(
|
||||
const std::vector<common_adapter_lora_info> & lora_base,
|
||||
const json & data) {
|
||||
std::vector<common_adapter_lora_info> lora(lora_base);
|
||||
int max_idx = lora.size();
|
||||
|
||||
// clear existing value
|
||||
for (auto & entry : lora) {
|
||||
entry.scale = 0.0f;
|
||||
}
|
||||
std::map<int, float> parse_lora_request(const json & data) {
|
||||
std::map<int, float> lora;
|
||||
|
||||
// set value
|
||||
for (const auto & entry : data) {
|
||||
int id = json_value(entry, "id", -1);
|
||||
float scale = json_value(entry, "scale", 0.0f);
|
||||
if (0 <= id && id < max_idx) {
|
||||
lora[id].scale = scale;
|
||||
} else {
|
||||
throw std::runtime_error("invalid adapter id");
|
||||
}
|
||||
lora[id] = scale;
|
||||
}
|
||||
|
||||
return lora;
|
||||
@@ -1435,7 +1423,7 @@ std::string safe_json_to_str(const json & data) {
|
||||
|
||||
// TODO: reuse llama_detokenize
|
||||
template <class Iter>
|
||||
static std::string tokens_to_str(llama_context * ctx, Iter begin, Iter end) {
|
||||
static std::string tokens_to_str(const llama_vocab * ctx, Iter begin, Iter end) {
|
||||
std::string ret;
|
||||
for (; begin != end; ++begin) {
|
||||
ret += common_token_to_piece(ctx, *begin);
|
||||
@@ -1445,7 +1433,12 @@ static std::string tokens_to_str(llama_context * ctx, Iter begin, Iter end) {
|
||||
}
|
||||
|
||||
std::string tokens_to_str(llama_context * ctx, const llama_tokens & tokens) {
|
||||
return tokens_to_str(ctx, tokens.begin(), tokens.end());
|
||||
auto model = llama_get_model(ctx);
|
||||
return tokens_to_str(llama_model_get_vocab(model), tokens.begin(), tokens.end());
|
||||
}
|
||||
|
||||
std::string tokens_to_str(const llama_vocab * vocab, const llama_tokens & tokens) {
|
||||
return tokens_to_str(vocab, tokens.begin(), tokens.end());
|
||||
}
|
||||
|
||||
// format incomplete utf-8 multibyte character for output
|
||||
|
||||
@@ -107,9 +107,7 @@ bool lora_should_clear_cache(
|
||||
const std::vector<common_adapter_lora_info> & current,
|
||||
const std::vector<common_adapter_lora_info> & next);
|
||||
|
||||
std::vector<common_adapter_lora_info> parse_lora_request(
|
||||
const std::vector<common_adapter_lora_info> & lora_base,
|
||||
const json & data);
|
||||
std::map<int, float> parse_lora_request(const json & data);
|
||||
|
||||
bool are_lora_equal(
|
||||
const std::vector<common_adapter_lora_info> & l1,
|
||||
@@ -325,6 +323,7 @@ std::vector<llama_token_data> get_token_probabilities(llama_context * ctx, int i
|
||||
std::string safe_json_to_str(const json & data);
|
||||
|
||||
std::string tokens_to_str(llama_context * ctx, const llama_tokens & tokens);
|
||||
std::string tokens_to_str(const llama_vocab * vocab, const llama_tokens & tokens);
|
||||
|
||||
// format incomplete utf-8 multibyte character for output
|
||||
std::string tokens_to_output_formatted_string(const llama_context * ctx, const llama_token token);
|
||||
|
||||
+388
-260
File diff suppressed because it is too large
Load Diff
@@ -9,11 +9,35 @@
|
||||
|
||||
struct server_context_impl; // private implementation
|
||||
|
||||
struct server_context_info {
|
||||
struct server_context_meta {
|
||||
std::string build_info;
|
||||
std::string model_name;
|
||||
std::string model_path;
|
||||
bool has_mtmd;
|
||||
bool has_inp_image;
|
||||
bool has_inp_audio;
|
||||
json json_webui_settings;
|
||||
int slot_n_ctx;
|
||||
enum llama_pooling_type pooling_type;
|
||||
|
||||
// chat template
|
||||
std::string chat_template;
|
||||
std::string chat_template_tool_use;
|
||||
|
||||
// tokens
|
||||
std::string bos_token_str;
|
||||
std::string eos_token_str;
|
||||
llama_token fim_pre_token;
|
||||
llama_token fim_sub_token;
|
||||
llama_token fim_mid_token;
|
||||
|
||||
// model meta
|
||||
enum llama_vocab_type model_vocab_type;
|
||||
int32_t model_vocab_n_tokens;
|
||||
int32_t model_n_ctx_train;
|
||||
int32_t model_n_embd_inp;
|
||||
uint64_t model_n_params;
|
||||
uint64_t model_size;
|
||||
};
|
||||
|
||||
struct server_context {
|
||||
@@ -22,9 +46,6 @@ struct server_context {
|
||||
server_context();
|
||||
~server_context();
|
||||
|
||||
// initialize slots and server-related data
|
||||
void init();
|
||||
|
||||
// load the model and initialize llama_context
|
||||
// returns true on success
|
||||
bool load_model(const common_params & params);
|
||||
@@ -35,15 +56,16 @@ struct server_context {
|
||||
// terminate main loop (will unblock start_loop)
|
||||
void terminate();
|
||||
|
||||
// get the underlaying llama_context
|
||||
// get the underlaying llama_context, can return nullptr if sleeping
|
||||
// not thread-safe, should only be used from the main thread
|
||||
llama_context * get_llama_context() const;
|
||||
|
||||
// get a new response reader, used by CLI application
|
||||
server_response_reader get_response_reader();
|
||||
|
||||
// get server info
|
||||
// used by CLI application
|
||||
server_context_info get_info() const;
|
||||
// get server metadata (read-only), can only be called after load_model()
|
||||
// not thread-safe, should only be used from the main thread
|
||||
server_context_meta get_meta() const;
|
||||
};
|
||||
|
||||
|
||||
@@ -51,13 +73,17 @@ struct server_context {
|
||||
struct server_res_generator;
|
||||
|
||||
struct server_routes {
|
||||
server_routes(const common_params & params, server_context & ctx_server, std::function<bool()> is_ready = []() { return true; })
|
||||
: params(params), ctx_server(*ctx_server.impl), is_ready(is_ready) {
|
||||
init_routes();
|
||||
}
|
||||
server_routes(const common_params & params, server_context & ctx_server);
|
||||
|
||||
void init_routes();
|
||||
|
||||
// note: this is not thread-safe and can only when ctx_http.is_ready is false
|
||||
void update_meta(const server_context & ctx_server) {
|
||||
this->meta = std::make_unique<server_context_meta>(ctx_server.get_meta());
|
||||
}
|
||||
|
||||
// handlers using lambda function, so that they can capture `this` without `std::bind`
|
||||
// they won't be called until ctx_http.is_ready is set to true
|
||||
server_http_context::handler_t get_health;
|
||||
server_http_context::handler_t get_metrics;
|
||||
server_http_context::handler_t get_slots;
|
||||
@@ -81,13 +107,24 @@ struct server_routes {
|
||||
server_http_context::handler_t get_lora_adapters;
|
||||
server_http_context::handler_t post_lora_adapters;
|
||||
private:
|
||||
// TODO: move these outside of server_routes?
|
||||
std::unique_ptr<server_res_generator> handle_completions_impl(
|
||||
const server_http_req & req,
|
||||
server_task_type type,
|
||||
const json & data,
|
||||
const std::vector<raw_buffer> & files,
|
||||
task_response_type res_type);
|
||||
std::unique_ptr<server_res_generator> handle_slots_save(const server_http_req & req, int id_slot);
|
||||
std::unique_ptr<server_res_generator> handle_slots_restore(const server_http_req & req, int id_slot);
|
||||
std::unique_ptr<server_res_generator> handle_slots_erase(const server_http_req &, int id_slot);
|
||||
std::unique_ptr<server_res_generator> handle_embeddings_impl(const server_http_req & req, task_response_type res_type);
|
||||
|
||||
// using unique_ptr to allow late initialization of const
|
||||
std::unique_ptr<const server_context_meta> meta;
|
||||
|
||||
const common_params & params;
|
||||
server_context_impl & ctx_server;
|
||||
std::function<bool()> is_ready;
|
||||
const server_context_impl & ctx_server;
|
||||
|
||||
server_queue & queue_tasks;
|
||||
server_response & queue_results;
|
||||
std::unique_ptr<server_res_generator> create_response(bool bypass_sleep = false);
|
||||
};
|
||||
|
||||
@@ -177,12 +177,11 @@ bool server_http_context::init(const common_params & params) {
|
||||
if (!ready) {
|
||||
auto tmp = string_split<std::string>(req.path, '.');
|
||||
if (req.path == "/" || tmp.back() == "html") {
|
||||
res.set_content(reinterpret_cast<const char*>(loading_html), loading_html_len, "text/html; charset=utf-8");
|
||||
res.status = 503;
|
||||
} else if (req.path == "/models" || req.path == "/v1/models" || req.path == "/api/tags") {
|
||||
// allow the models endpoint to be accessed during loading
|
||||
return true;
|
||||
res.set_content(reinterpret_cast<const char*>(loading_html), loading_html_len, "text/html; charset=utf-8");
|
||||
} else {
|
||||
// no endpoints is allowed to be accessed when the server is not ready
|
||||
// this is to prevent any data races or inconsistent states
|
||||
res.status = 503;
|
||||
res.set_content(
|
||||
safe_json_to_str(json {
|
||||
@@ -334,12 +333,16 @@ static std::map<std::string, std::string> get_headers(const httplib::Request & r
|
||||
return headers;
|
||||
}
|
||||
|
||||
static void process_handler_response(server_http_res_ptr & response, httplib::Response & res) {
|
||||
// using unique_ptr for request to allow safe capturing in lambdas
|
||||
using server_http_req_ptr = std::unique_ptr<server_http_req>;
|
||||
|
||||
static void process_handler_response(server_http_req_ptr && request, server_http_res_ptr & response, httplib::Response & res) {
|
||||
if (response->is_stream()) {
|
||||
res.status = response->status;
|
||||
set_headers(res, response->headers);
|
||||
std::string content_type = response->content_type;
|
||||
// convert to shared_ptr as both chunked_content_provider() and on_complete() need to use it
|
||||
std::shared_ptr<server_http_req> q_ptr = std::move(request);
|
||||
std::shared_ptr<server_http_res> r_ptr = std::move(response);
|
||||
const auto chunked_content_provider = [response = r_ptr](size_t, httplib::DataSink & sink) -> bool {
|
||||
std::string chunk;
|
||||
@@ -355,8 +358,9 @@ static void process_handler_response(server_http_res_ptr & response, httplib::Re
|
||||
}
|
||||
return has_next;
|
||||
};
|
||||
const auto on_complete = [response = r_ptr](bool) mutable {
|
||||
const auto on_complete = [request = q_ptr, response = r_ptr](bool) mutable {
|
||||
response.reset(); // trigger the destruction of the response object
|
||||
request.reset(); // trigger the destruction of the request object
|
||||
};
|
||||
res.set_chunked_content_provider(content_type, chunked_content_provider, on_complete);
|
||||
} else {
|
||||
@@ -368,27 +372,29 @@ static void process_handler_response(server_http_res_ptr & response, httplib::Re
|
||||
|
||||
void server_http_context::get(const std::string & path, const server_http_context::handler_t & handler) const {
|
||||
pimpl->srv->Get(path_prefix + path, [handler](const httplib::Request & req, httplib::Response & res) {
|
||||
server_http_res_ptr response = handler(server_http_req{
|
||||
server_http_req_ptr request = std::make_unique<server_http_req>(server_http_req{
|
||||
get_params(req),
|
||||
get_headers(req),
|
||||
req.path,
|
||||
req.body,
|
||||
req.is_connection_closed
|
||||
});
|
||||
process_handler_response(response, res);
|
||||
server_http_res_ptr response = handler(*request);
|
||||
process_handler_response(std::move(request), response, res);
|
||||
});
|
||||
}
|
||||
|
||||
void server_http_context::post(const std::string & path, const server_http_context::handler_t & handler) const {
|
||||
pimpl->srv->Post(path_prefix + path, [handler](const httplib::Request & req, httplib::Response & res) {
|
||||
server_http_res_ptr response = handler(server_http_req{
|
||||
server_http_req_ptr request = std::make_unique<server_http_req>(server_http_req{
|
||||
get_params(req),
|
||||
get_headers(req),
|
||||
req.path,
|
||||
req.body,
|
||||
req.is_connection_closed
|
||||
});
|
||||
process_handler_response(response, res);
|
||||
server_http_res_ptr response = handler(*request);
|
||||
process_handler_response(std::move(request), response, res);
|
||||
});
|
||||
}
|
||||
|
||||
|
||||
+116
-231
@@ -82,154 +82,30 @@ static std::filesystem::path get_server_exec_path() {
|
||||
#endif
|
||||
}
|
||||
|
||||
struct local_model {
|
||||
std::string name;
|
||||
std::string path;
|
||||
std::string path_mmproj;
|
||||
};
|
||||
|
||||
static std::vector<local_model> list_local_models(const std::string & dir) {
|
||||
if (!std::filesystem::exists(dir) || !std::filesystem::is_directory(dir)) {
|
||||
throw std::runtime_error(string_format("error: '%s' does not exist or is not a directory\n", dir.c_str()));
|
||||
}
|
||||
|
||||
std::vector<local_model> models;
|
||||
auto scan_subdir = [&models](const std::string & subdir_path, const std::string & name) {
|
||||
auto files = fs_list(subdir_path, false);
|
||||
common_file_info model_file;
|
||||
common_file_info first_shard_file;
|
||||
common_file_info mmproj_file;
|
||||
for (const auto & file : files) {
|
||||
if (string_ends_with(file.name, ".gguf")) {
|
||||
if (file.name.find("mmproj") != std::string::npos) {
|
||||
mmproj_file = file;
|
||||
} else if (file.name.find("-00001-of-") != std::string::npos) {
|
||||
first_shard_file = file;
|
||||
} else {
|
||||
model_file = file;
|
||||
}
|
||||
}
|
||||
}
|
||||
// single file model
|
||||
local_model model{
|
||||
/* name */ name,
|
||||
/* path */ first_shard_file.path.empty() ? model_file.path : first_shard_file.path,
|
||||
/* path_mmproj */ mmproj_file.path // can be empty
|
||||
};
|
||||
if (!model.path.empty()) {
|
||||
models.push_back(model);
|
||||
}
|
||||
};
|
||||
|
||||
auto files = fs_list(dir, true);
|
||||
for (const auto & file : files) {
|
||||
if (file.is_dir) {
|
||||
scan_subdir(file.path, file.name);
|
||||
} else if (string_ends_with(file.name, ".gguf")) {
|
||||
// single file model
|
||||
std::string name = file.name;
|
||||
string_replace_all(name, ".gguf", "");
|
||||
local_model model{
|
||||
/* name */ name,
|
||||
/* path */ file.path,
|
||||
/* path_mmproj */ ""
|
||||
};
|
||||
models.push_back(model);
|
||||
}
|
||||
}
|
||||
return models;
|
||||
}
|
||||
|
||||
//
|
||||
// server_presets
|
||||
//
|
||||
|
||||
|
||||
server_presets::server_presets(int argc, char ** argv, common_params & base_params, const std::string & presets_path)
|
||||
: ctx_params(common_params_parser_init(base_params, LLAMA_EXAMPLE_SERVER)) {
|
||||
if (!presets_path.empty()) {
|
||||
presets = common_presets_load(presets_path, ctx_params);
|
||||
SRV_INF("Loaded %zu presets from %s\n", presets.size(), presets_path.c_str());
|
||||
}
|
||||
|
||||
// populate reserved args (will be appended by the router)
|
||||
for (auto & opt : ctx_params.options) {
|
||||
if (opt.env == nullptr) {
|
||||
continue;
|
||||
}
|
||||
std::string env = opt.env;
|
||||
if (env == "LLAMA_ARG_PORT" ||
|
||||
env == "LLAMA_ARG_HOST" ||
|
||||
env == "LLAMA_ARG_ALIAS" ||
|
||||
env == "LLAMA_ARG_API_KEY" ||
|
||||
env == "LLAMA_ARG_MODELS_DIR" ||
|
||||
env == "LLAMA_ARG_MODELS_MAX" ||
|
||||
env == "LLAMA_ARG_MODELS_PRESET" ||
|
||||
env == "LLAMA_ARG_MODEL" ||
|
||||
env == "LLAMA_ARG_MMPROJ" ||
|
||||
env == "LLAMA_ARG_HF_REPO" ||
|
||||
env == "LLAMA_ARG_NO_MODELS_AUTOLOAD" ||
|
||||
env == "LLAMA_ARG_SSL_KEY_FILE" ||
|
||||
env == "LLAMA_ARG_SSL_CERT_FILE") {
|
||||
control_args[env] = opt;
|
||||
}
|
||||
}
|
||||
|
||||
// read base args from router's argv
|
||||
common_params_to_map(argc, argv, LLAMA_EXAMPLE_SERVER, base_args);
|
||||
|
||||
// remove any router-controlled args from base_args
|
||||
for (const auto & cargs : control_args) {
|
||||
auto it = base_args.find(cargs.second);
|
||||
if (it != base_args.end()) {
|
||||
base_args.erase(it);
|
||||
}
|
||||
static void unset_reserved_args(common_preset & preset, bool unset_model_args) {
|
||||
preset.unset_option("LLAMA_ARG_SSL_KEY_FILE");
|
||||
preset.unset_option("LLAMA_ARG_SSL_CERT_FILE");
|
||||
preset.unset_option("LLAMA_API_KEY");
|
||||
preset.unset_option("LLAMA_ARG_MODELS_DIR");
|
||||
preset.unset_option("LLAMA_ARG_MODELS_MAX");
|
||||
preset.unset_option("LLAMA_ARG_MODELS_PRESET");
|
||||
preset.unset_option("LLAMA_ARG_MODELS_AUTOLOAD");
|
||||
if (unset_model_args) {
|
||||
preset.unset_option("LLAMA_ARG_MODEL");
|
||||
preset.unset_option("LLAMA_ARG_MMPROJ");
|
||||
preset.unset_option("LLAMA_ARG_HF_REPO");
|
||||
}
|
||||
}
|
||||
|
||||
common_preset server_presets::get_preset(const std::string & name) {
|
||||
auto it = presets.find(name);
|
||||
if (it != presets.end()) {
|
||||
return it->second;
|
||||
}
|
||||
return common_preset();
|
||||
}
|
||||
|
||||
void server_presets::render_args(server_model_meta & meta) {
|
||||
common_preset preset = meta.preset; // copy
|
||||
// merging 3 kinds of args:
|
||||
// 1. model-specific args (from preset)
|
||||
// force removing control args if any
|
||||
for (auto & cargs : control_args) {
|
||||
if (preset.options.find(cargs.second) != preset.options.end()) {
|
||||
SRV_WRN("Preset '%s' contains reserved arg '%s', removing it\n", preset.name.c_str(), cargs.second.args[0]);
|
||||
preset.options.erase(cargs.second);
|
||||
}
|
||||
}
|
||||
// 2. base args (from router)
|
||||
// inherit from base args
|
||||
for (const auto & [arg, value] : base_args) {
|
||||
preset.options[arg] = value;
|
||||
}
|
||||
// 3. control args (from router)
|
||||
// set control values
|
||||
preset.options[control_args["LLAMA_ARG_HOST"]] = CHILD_ADDR;
|
||||
preset.options[control_args["LLAMA_ARG_PORT"]] = std::to_string(meta.port);
|
||||
preset.options[control_args["LLAMA_ARG_ALIAS"]] = meta.name;
|
||||
if (meta.in_cache) {
|
||||
preset.options[control_args["LLAMA_ARG_HF_REPO"]] = meta.name;
|
||||
} else {
|
||||
preset.options[control_args["LLAMA_ARG_MODEL"]] = meta.path;
|
||||
if (!meta.path_mmproj.empty()) {
|
||||
preset.options[control_args["LLAMA_ARG_MMPROJ"]] = meta.path_mmproj;
|
||||
}
|
||||
}
|
||||
// disable SSL for child processes (HTTPS already handled by router)
|
||||
preset.options[control_args["LLAMA_ARG_SSL_KEY_FILE"]] = "";
|
||||
preset.options[control_args["LLAMA_ARG_SSL_CERT_FILE"]] = "";
|
||||
meta.args = preset.to_args();
|
||||
// add back the binary path at the front
|
||||
meta.args.insert(meta.args.begin(), get_server_exec_path().string());
|
||||
void server_model_meta::update_args(common_preset_context & ctx_preset, std::string bin_path) {
|
||||
// update params
|
||||
unset_reserved_args(preset, false);
|
||||
preset.set_option(ctx_preset, "LLAMA_ARG_HOST", CHILD_ADDR);
|
||||
preset.set_option(ctx_preset, "LLAMA_ARG_PORT", std::to_string(port));
|
||||
preset.set_option(ctx_preset, "LLAMA_ARG_ALIAS", name);
|
||||
// TODO: maybe validate preset before rendering ?
|
||||
// render args
|
||||
args = preset.to_args(bin_path);
|
||||
}
|
||||
|
||||
//
|
||||
@@ -240,20 +116,22 @@ server_models::server_models(
|
||||
const common_params & params,
|
||||
int argc,
|
||||
char ** argv,
|
||||
char ** envp) : base_params(params), presets(argc, argv, base_params, params.models_preset) {
|
||||
for (int i = 0; i < argc; i++) {
|
||||
base_args.push_back(std::string(argv[i]));
|
||||
}
|
||||
char ** envp)
|
||||
: ctx_preset(LLAMA_EXAMPLE_SERVER),
|
||||
base_params(params),
|
||||
base_preset(ctx_preset.load_from_args(argc, argv)) {
|
||||
for (char ** env = envp; *env != nullptr; env++) {
|
||||
base_env.push_back(std::string(*env));
|
||||
}
|
||||
GGML_ASSERT(!base_args.empty());
|
||||
// clean up base preset
|
||||
unset_reserved_args(base_preset, true);
|
||||
// set binary path
|
||||
try {
|
||||
base_args[0] = get_server_exec_path().string();
|
||||
bin_path = get_server_exec_path().string();
|
||||
} catch (const std::exception & e) {
|
||||
bin_path = argv[0];
|
||||
LOG_WRN("failed to get server executable path: %s\n", e.what());
|
||||
LOG_WRN("using original argv[0] as fallback: %s\n", base_args[0].c_str());
|
||||
LOG_WRN("using original argv[0] as fallback: %s\n", argv[0]);
|
||||
}
|
||||
load_models();
|
||||
}
|
||||
@@ -262,7 +140,7 @@ void server_models::add_model(server_model_meta && meta) {
|
||||
if (mapping.find(meta.name) != mapping.end()) {
|
||||
throw std::runtime_error(string_format("model '%s' appears multiple times", meta.name.c_str()));
|
||||
}
|
||||
presets.render_args(meta); // populate meta.args
|
||||
meta.update_args(ctx_preset, bin_path); // render args
|
||||
std::string name = meta.name;
|
||||
mapping[name] = instance_t{
|
||||
/* subproc */ std::make_shared<subprocess_s>(),
|
||||
@@ -271,86 +149,62 @@ void server_models::add_model(server_model_meta && meta) {
|
||||
};
|
||||
}
|
||||
|
||||
static std::vector<local_model> list_custom_path_models(server_presets & presets) {
|
||||
// detect any custom-path models in presets
|
||||
std::vector<local_model> custom_models;
|
||||
for (auto & [model_name, preset] : presets.presets) {
|
||||
local_model model;
|
||||
model.name = model_name;
|
||||
std::vector<common_arg> to_erase;
|
||||
for (auto & [arg, value] : preset.options) {
|
||||
std::string env(arg.env ? arg.env : "");
|
||||
if (env == "LLAMA_ARG_MODEL") {
|
||||
model.path = value;
|
||||
to_erase.push_back(arg);
|
||||
}
|
||||
if (env == "LLAMA_ARG_MMPROJ") {
|
||||
model.path_mmproj = value;
|
||||
to_erase.push_back(arg);
|
||||
}
|
||||
}
|
||||
for (auto & arg : to_erase) {
|
||||
preset.options.erase(arg);
|
||||
}
|
||||
if (!model.name.empty() && !model.path.empty()) {
|
||||
custom_models.push_back(model);
|
||||
}
|
||||
}
|
||||
return custom_models;
|
||||
}
|
||||
|
||||
// TODO: allow refreshing cached model list
|
||||
void server_models::load_models() {
|
||||
// loading models from 3 sources:
|
||||
// 1. cached models
|
||||
auto cached_models = common_list_cached_models();
|
||||
for (const auto & model : cached_models) {
|
||||
server_model_meta meta{
|
||||
/* preset */ presets.get_preset(model.to_string()),
|
||||
/* name */ model.to_string(),
|
||||
/* path */ model.manifest_path,
|
||||
/* path_mmproj */ "", // auto-detected when loading
|
||||
/* in_cache */ true,
|
||||
/* port */ 0,
|
||||
/* status */ SERVER_MODEL_STATUS_UNLOADED,
|
||||
/* last_used */ 0,
|
||||
/* args */ std::vector<std::string>(),
|
||||
/* exit_code */ 0
|
||||
};
|
||||
add_model(std::move(meta));
|
||||
}
|
||||
// 2. local models specificed via --models-dir
|
||||
common_presets cached_models = ctx_preset.load_from_cache();
|
||||
SRV_INF("Loaded %zu cached model presets\n", cached_models.size());
|
||||
// 2. local models from --models-dir
|
||||
common_presets local_models;
|
||||
if (!base_params.models_dir.empty()) {
|
||||
auto local_models = list_local_models(base_params.models_dir);
|
||||
for (const auto & model : local_models) {
|
||||
if (mapping.find(model.name) != mapping.end()) {
|
||||
// already exists in cached models, skip
|
||||
continue;
|
||||
}
|
||||
server_model_meta meta{
|
||||
/* preset */ presets.get_preset(model.name),
|
||||
/* name */ model.name,
|
||||
/* path */ model.path,
|
||||
/* path_mmproj */ model.path_mmproj,
|
||||
/* in_cache */ false,
|
||||
/* port */ 0,
|
||||
/* status */ SERVER_MODEL_STATUS_UNLOADED,
|
||||
/* last_used */ 0,
|
||||
/* args */ std::vector<std::string>(),
|
||||
/* exit_code */ 0
|
||||
};
|
||||
add_model(std::move(meta));
|
||||
local_models = ctx_preset.load_from_models_dir(base_params.models_dir);
|
||||
SRV_INF("Loaded %zu local model presets from %s\n", local_models.size(), base_params.models_dir.c_str());
|
||||
}
|
||||
// 3. custom-path models from presets
|
||||
common_preset global = {};
|
||||
common_presets custom_presets = {};
|
||||
if (!base_params.models_preset.empty()) {
|
||||
custom_presets = ctx_preset.load_from_ini(base_params.models_preset, global);
|
||||
SRV_INF("Loaded %zu custom model presets from %s\n", custom_presets.size(), base_params.models_preset.c_str());
|
||||
}
|
||||
|
||||
// cascade, apply global preset first
|
||||
cached_models = ctx_preset.cascade(global, cached_models);
|
||||
local_models = ctx_preset.cascade(global, local_models);
|
||||
custom_presets = ctx_preset.cascade(global, custom_presets);
|
||||
|
||||
// note: if a model exists in both cached and local, local takes precedence
|
||||
common_presets final_presets;
|
||||
for (const auto & [name, preset] : cached_models) {
|
||||
final_presets[name] = preset;
|
||||
}
|
||||
for (const auto & [name, preset] : local_models) {
|
||||
final_presets[name] = preset;
|
||||
}
|
||||
|
||||
// process custom presets from INI
|
||||
for (const auto & [name, custom] : custom_presets) {
|
||||
if (final_presets.find(name) != final_presets.end()) {
|
||||
// apply custom config if exists
|
||||
common_preset & target = final_presets[name];
|
||||
target.merge(custom);
|
||||
} else {
|
||||
// otherwise add directly
|
||||
final_presets[name] = custom;
|
||||
}
|
||||
}
|
||||
// 3. custom-path models specified in presets
|
||||
auto custom_models = list_custom_path_models(presets);
|
||||
for (const auto & model : custom_models) {
|
||||
|
||||
// server base preset from CLI args take highest precedence
|
||||
for (auto & [name, preset] : final_presets) {
|
||||
preset.merge(base_preset);
|
||||
}
|
||||
|
||||
// convert presets to server_model_meta and add to mapping
|
||||
for (const auto & preset : final_presets) {
|
||||
server_model_meta meta{
|
||||
/* preset */ presets.get_preset(model.name),
|
||||
/* name */ model.name,
|
||||
/* path */ model.path,
|
||||
/* path_mmproj */ model.path_mmproj,
|
||||
/* in_cache */ false,
|
||||
/* preset */ preset.second,
|
||||
/* name */ preset.first,
|
||||
/* port */ 0,
|
||||
/* status */ SERVER_MODEL_STATUS_UNLOADED,
|
||||
/* last_used */ 0,
|
||||
@@ -359,10 +213,38 @@ void server_models::load_models() {
|
||||
};
|
||||
add_model(std::move(meta));
|
||||
}
|
||||
|
||||
// log available models
|
||||
SRV_INF("Available models (%zu) (*: custom preset)\n", mapping.size());
|
||||
{
|
||||
std::unordered_set<std::string> custom_names;
|
||||
for (const auto & [name, preset] : custom_presets) {
|
||||
custom_names.insert(name);
|
||||
}
|
||||
SRV_INF("Available models (%zu) (*: custom preset)\n", mapping.size());
|
||||
for (const auto & [name, inst] : mapping) {
|
||||
bool has_custom = custom_names.find(name) != custom_names.end();
|
||||
SRV_INF(" %c %s\n", has_custom ? '*' : ' ', name.c_str());
|
||||
}
|
||||
}
|
||||
|
||||
// load any autoload models
|
||||
std::vector<std::string> models_to_load;
|
||||
for (const auto & [name, inst] : mapping) {
|
||||
SRV_INF(" %c %s\n", inst.meta.preset.name.empty() ? ' ' : '*', name.c_str());
|
||||
std::string val;
|
||||
if (inst.meta.preset.get_option(COMMON_ARG_PRESET_LOAD_ON_STARTUP, val)) {
|
||||
models_to_load.push_back(name);
|
||||
}
|
||||
}
|
||||
if ((int)models_to_load.size() > base_params.models_max) {
|
||||
throw std::runtime_error(string_format(
|
||||
"number of models to load on startup (%zu) exceeds models_max (%d)",
|
||||
models_to_load.size(),
|
||||
base_params.models_max
|
||||
));
|
||||
}
|
||||
for (const auto & name : models_to_load) {
|
||||
SRV_INF("(startup) loading model %s\n", name.c_str());
|
||||
load(name);
|
||||
}
|
||||
}
|
||||
|
||||
@@ -526,7 +408,7 @@ void server_models::load(const std::string & name) {
|
||||
{
|
||||
SRV_INF("spawning server instance with name=%s on port %d\n", inst.meta.name.c_str(), inst.meta.port);
|
||||
|
||||
presets.render_args(inst.meta); // update meta.args
|
||||
inst.meta.update_args(ctx_preset, bin_path); // render args
|
||||
|
||||
std::vector<std::string> child_args = inst.meta.args; // copy
|
||||
std::vector<std::string> child_env = base_env; // copy
|
||||
@@ -877,7 +759,12 @@ void server_models_routes::init_routes() {
|
||||
{"args", meta.args},
|
||||
};
|
||||
if (!meta.preset.name.empty()) {
|
||||
status["preset"] = meta.preset.to_ini();
|
||||
common_preset preset_copy = meta.preset;
|
||||
unset_reserved_args(preset_copy, false);
|
||||
preset_copy.unset_option("LLAMA_ARG_HOST");
|
||||
preset_copy.unset_option("LLAMA_ARG_PORT");
|
||||
preset_copy.unset_option("LLAMA_ARG_ALIAS");
|
||||
status["preset"] = preset_copy.to_ini();
|
||||
}
|
||||
if (meta.is_failed()) {
|
||||
status["exit_code"] = meta.exit_code;
|
||||
@@ -888,8 +775,6 @@ void server_models_routes::init_routes() {
|
||||
{"object", "model"}, // for OAI-compat
|
||||
{"owned_by", "llamacpp"}, // for OAI-compat
|
||||
{"created", t}, // for OAI-compat
|
||||
{"in_cache", meta.in_cache},
|
||||
{"path", meta.path},
|
||||
{"status", status},
|
||||
// TODO: add other fields, may require reading GGUF metadata
|
||||
});
|
||||
|
||||
@@ -51,9 +51,6 @@ static std::string server_model_status_to_string(server_model_status status) {
|
||||
struct server_model_meta {
|
||||
common_preset preset;
|
||||
std::string name;
|
||||
std::string path;
|
||||
std::string path_mmproj; // only available if in_cache=false
|
||||
bool in_cache = false; // if true, use -hf; use -m otherwise
|
||||
int port = 0;
|
||||
server_model_status status = SERVER_MODEL_STATUS_UNLOADED;
|
||||
int64_t last_used = 0; // for LRU unloading
|
||||
@@ -67,19 +64,8 @@ struct server_model_meta {
|
||||
bool is_failed() const {
|
||||
return status == SERVER_MODEL_STATUS_UNLOADED && exit_code != 0;
|
||||
}
|
||||
};
|
||||
|
||||
// the server_presets struct holds the presets read from presets.ini
|
||||
// as well as base args from the router server
|
||||
struct server_presets {
|
||||
common_presets presets;
|
||||
common_params_context ctx_params;
|
||||
std::map<common_arg, std::string> base_args;
|
||||
std::map<std::string, common_arg> control_args; // args reserved for server control
|
||||
|
||||
server_presets(int argc, char ** argv, common_params & base_params, const std::string & models_dir);
|
||||
common_preset get_preset(const std::string & name);
|
||||
void render_args(server_model_meta & meta);
|
||||
void update_args(common_preset_context & ctx_presets, std::string bin_path);
|
||||
};
|
||||
|
||||
struct subprocess_s;
|
||||
@@ -97,11 +83,12 @@ private:
|
||||
std::condition_variable cv;
|
||||
std::map<std::string, instance_t> mapping;
|
||||
|
||||
common_params base_params;
|
||||
std::vector<std::string> base_args;
|
||||
std::vector<std::string> base_env;
|
||||
common_preset_context ctx_preset;
|
||||
|
||||
server_presets presets;
|
||||
common_params base_params;
|
||||
std::string bin_path;
|
||||
std::vector<std::string> base_env;
|
||||
common_preset base_preset; // base preset from llama-server CLI args
|
||||
|
||||
void update_meta(const std::string & name, const server_model_meta & meta);
|
||||
|
||||
@@ -116,27 +103,29 @@ public:
|
||||
|
||||
void load_models();
|
||||
|
||||
// check if a model instance exists
|
||||
// check if a model instance exists (thread-safe)
|
||||
bool has_model(const std::string & name);
|
||||
|
||||
// return a copy of model metadata
|
||||
// return a copy of model metadata (thread-safe)
|
||||
std::optional<server_model_meta> get_meta(const std::string & name);
|
||||
|
||||
// return a copy of all model metadata
|
||||
// return a copy of all model metadata (thread-safe)
|
||||
std::vector<server_model_meta> get_all_meta();
|
||||
|
||||
// load and unload model instances
|
||||
// these functions are thread-safe
|
||||
void load(const std::string & name);
|
||||
void unload(const std::string & name);
|
||||
void unload_all();
|
||||
|
||||
// update the status of a model instance
|
||||
// update the status of a model instance (thread-safe)
|
||||
void update_status(const std::string & name, server_model_status status);
|
||||
|
||||
// wait until the model instance is fully loaded
|
||||
// wait until the model instance is fully loaded (thread-safe)
|
||||
// return when the model is loaded or failed to load
|
||||
void wait_until_loaded(const std::string & name);
|
||||
|
||||
// load the model if not loaded, otherwise do nothing
|
||||
// load the model if not loaded, otherwise do nothing (thread-safe)
|
||||
// return false if model is already loaded; return true otherwise (meta may need to be refreshed)
|
||||
bool ensure_model_loaded(const std::string & name);
|
||||
|
||||
|
||||
@@ -33,6 +33,7 @@ int server_queue::post(server_task && task, bool front) {
|
||||
} else {
|
||||
queue_tasks.push_back(std::move(task));
|
||||
}
|
||||
time_last_task = ggml_time_ms();
|
||||
condition_tasks.notify_one();
|
||||
return task_id;
|
||||
}
|
||||
@@ -54,6 +55,7 @@ int server_queue::post(std::vector<server_task> && tasks, bool front) {
|
||||
queue_tasks.push_back(std::move(task));
|
||||
}
|
||||
}
|
||||
time_last_task = ggml_time_ms();
|
||||
condition_tasks.notify_one();
|
||||
return 0;
|
||||
}
|
||||
@@ -62,6 +64,7 @@ void server_queue::defer(server_task && task) {
|
||||
std::unique_lock<std::mutex> lock(mutex_tasks);
|
||||
QUE_DBG("defer task, id = %d\n", task.id);
|
||||
queue_tasks_deferred.push_back(std::move(task));
|
||||
time_last_task = ggml_time_ms();
|
||||
condition_tasks.notify_one();
|
||||
}
|
||||
|
||||
@@ -71,31 +74,52 @@ int server_queue::get_new_id() {
|
||||
return new_id;
|
||||
}
|
||||
|
||||
void server_queue::on_new_task(std::function<void(server_task &&)> callback) {
|
||||
callback_new_task = std::move(callback);
|
||||
}
|
||||
|
||||
void server_queue::on_update_slots(std::function<void(void)> callback) {
|
||||
callback_update_slots = std::move(callback);
|
||||
}
|
||||
|
||||
void server_queue::pop_deferred_task() {
|
||||
std::unique_lock<std::mutex> lock(mutex_tasks);
|
||||
if (!queue_tasks_deferred.empty()) {
|
||||
queue_tasks.emplace_front(std::move(queue_tasks_deferred.front()));
|
||||
queue_tasks_deferred.pop_front();
|
||||
}
|
||||
time_last_task = ggml_time_ms();
|
||||
condition_tasks.notify_one();
|
||||
}
|
||||
|
||||
void server_queue::wait_until_no_sleep() {
|
||||
std::unique_lock<std::mutex> lock(mutex_tasks);
|
||||
if (!sleeping) {
|
||||
return;
|
||||
} else {
|
||||
if (!req_stop_sleeping) {
|
||||
QUE_DBG("%s", "requesting to stop sleeping\n");
|
||||
req_stop_sleeping = true;
|
||||
condition_tasks.notify_one(); // only main thread is waiting on this
|
||||
}
|
||||
QUE_DBG("%s", "waiting until no sleep\n");
|
||||
condition_tasks.wait(lock, [&]{
|
||||
return !sleeping;
|
||||
});
|
||||
}
|
||||
}
|
||||
|
||||
void server_queue::terminate() {
|
||||
std::unique_lock<std::mutex> lock(mutex_tasks);
|
||||
running = false;
|
||||
condition_tasks.notify_all();
|
||||
}
|
||||
|
||||
void server_queue::start_loop() {
|
||||
void server_queue::start_loop(int64_t idle_sleep_ms) {
|
||||
running = true;
|
||||
time_last_task = ggml_time_ms();
|
||||
|
||||
constexpr auto max_wait_time = std::chrono::seconds(1);
|
||||
auto should_sleep = [&]() -> bool {
|
||||
// caller must hold mutex_tasks
|
||||
if (idle_sleep_ms < 0) {
|
||||
return false;
|
||||
}
|
||||
int64_t now = ggml_time_ms();
|
||||
return (now - time_last_task) >= idle_sleep_ms;
|
||||
};
|
||||
|
||||
while (true) {
|
||||
QUE_DBG("%s", "processing new tasks\n");
|
||||
@@ -117,23 +141,53 @@ void server_queue::start_loop() {
|
||||
QUE_DBG("processing task, id = %d\n", task.id);
|
||||
callback_new_task(std::move(task));
|
||||
}
|
||||
|
||||
// all tasks in the current loop is processed, slots data is now ready
|
||||
QUE_DBG("%s", "update slots\n");
|
||||
|
||||
// this will run the main inference process for all slots
|
||||
callback_update_slots();
|
||||
{
|
||||
// update_slots() may take a while to finish, we need to make sure it's not counted as idle
|
||||
std::unique_lock<std::mutex> lock(mutex_tasks);
|
||||
time_last_task = ggml_time_ms();
|
||||
}
|
||||
|
||||
QUE_DBG("%s", "waiting for new tasks\n");
|
||||
{
|
||||
while (true) {
|
||||
std::unique_lock<std::mutex> lock(mutex_tasks);
|
||||
if (!running) {
|
||||
QUE_DBG("%s", "terminate\n");
|
||||
return;
|
||||
if (!running || !queue_tasks.empty()) {
|
||||
break; // go back to process new tasks or terminate
|
||||
}
|
||||
if (queue_tasks.empty()) {
|
||||
|
||||
// no tasks, check for sleeping state
|
||||
if (should_sleep()) {
|
||||
QUE_INF("%s", "entering sleeping state\n");
|
||||
sleeping = true;
|
||||
callback_sleeping_state(true);
|
||||
req_stop_sleeping = false;
|
||||
// wait until we are requested to exit sleeping state
|
||||
condition_tasks.wait(lock, [&]{
|
||||
return (!running || req_stop_sleeping);
|
||||
});
|
||||
if (!running) { // may changed during sleep
|
||||
break; // terminate
|
||||
}
|
||||
QUE_INF("%s", "exiting sleeping state\n");
|
||||
req_stop_sleeping = false;
|
||||
callback_sleeping_state(false);
|
||||
sleeping = false;
|
||||
time_last_task = ggml_time_ms();
|
||||
condition_tasks.notify_all(); // notify wait_until_no_sleep()
|
||||
break; // process new tasks
|
||||
} else {
|
||||
// wait for new tasks or timeout for checking sleeping condition
|
||||
bool res = condition_tasks.wait_for(lock, max_wait_time, [&]{
|
||||
return (!queue_tasks.empty() || !running);
|
||||
});
|
||||
if (res) {
|
||||
break; // new task arrived or terminate
|
||||
}
|
||||
// otherwise, loop again to check sleeping condition
|
||||
}
|
||||
}
|
||||
}
|
||||
@@ -271,23 +325,25 @@ void server_response::terminate() {
|
||||
// server_response_reader
|
||||
//
|
||||
|
||||
void server_response_reader::post_task(server_task && task) {
|
||||
void server_response_reader::post_task(server_task && task, bool front) {
|
||||
GGML_ASSERT(id_tasks.empty() && "post_task() can only be called once per reader");
|
||||
task.index = 0;
|
||||
id_tasks.insert(task.id);
|
||||
states.push_back(task.create_state());
|
||||
queue_results.add_waiting_task_id(task.id);
|
||||
queue_tasks.post(std::move(task));
|
||||
queue_tasks.post(std::move(task), front);
|
||||
}
|
||||
|
||||
void server_response_reader::post_tasks(std::vector<server_task> && tasks) {
|
||||
void server_response_reader::post_tasks(std::vector<server_task> && tasks, bool front) {
|
||||
GGML_ASSERT(id_tasks.empty() && "post_tasks() can only be called once per reader");
|
||||
id_tasks = server_task::get_list_id(tasks);
|
||||
states.reserve(tasks.size());
|
||||
for (size_t i = 0; i < tasks.size(); i++) {
|
||||
tasks[i].index = i;
|
||||
states.push_back(tasks[i].create_state());
|
||||
}
|
||||
queue_results.add_waiting_tasks(tasks);
|
||||
queue_tasks.post(std::move(tasks));
|
||||
queue_tasks.post(std::move(tasks), front);
|
||||
}
|
||||
|
||||
bool server_response_reader::has_next() const {
|
||||
@@ -313,7 +369,7 @@ server_task_result_ptr server_response_reader::next(const std::function<bool()>
|
||||
}
|
||||
if (!states.empty()) {
|
||||
// update the generation state if needed
|
||||
size_t idx = result->get_index();
|
||||
const size_t idx = result->index;
|
||||
GGML_ASSERT(idx < states.size());
|
||||
result->update(states[idx]);
|
||||
}
|
||||
@@ -329,6 +385,7 @@ server_task_result_ptr server_response_reader::next(const std::function<bool()>
|
||||
|
||||
server_response_reader::batch_response server_response_reader::wait_for_all(const std::function<bool()> & should_stop) {
|
||||
batch_response batch_res;
|
||||
batch_res.results.clear();
|
||||
batch_res.results.resize(id_tasks.size());
|
||||
while (has_next()) {
|
||||
auto res = next(should_stop);
|
||||
@@ -340,7 +397,7 @@ server_response_reader::batch_response server_response_reader::wait_for_all(cons
|
||||
batch_res.error = std::move(res);
|
||||
return batch_res;
|
||||
}
|
||||
const size_t idx = res->get_index();
|
||||
const size_t idx = res->index;
|
||||
GGML_ASSERT(idx < batch_res.results.size() && "index out of range");
|
||||
GGML_ASSERT(batch_res.results[idx] == nullptr && "duplicate result received");
|
||||
batch_res.results[idx] = std::move(res);
|
||||
|
||||
+48
-10
@@ -5,6 +5,7 @@
|
||||
#include <condition_variable>
|
||||
#include <deque>
|
||||
#include <mutex>
|
||||
#include <vector>
|
||||
#include <unordered_set>
|
||||
|
||||
// struct for managing server tasks
|
||||
@@ -12,7 +13,10 @@
|
||||
struct server_queue {
|
||||
private:
|
||||
int id = 0;
|
||||
bool running;
|
||||
bool running = false;
|
||||
bool sleeping = false;
|
||||
bool req_stop_sleeping = false;
|
||||
int64_t time_last_task = 0;
|
||||
|
||||
// queues
|
||||
std::deque<server_task> queue_tasks;
|
||||
@@ -24,6 +28,7 @@ private:
|
||||
// callback functions
|
||||
std::function<void(server_task &&)> callback_new_task;
|
||||
std::function<void(void)> callback_update_slots;
|
||||
std::function<void(bool)> callback_sleeping_state;
|
||||
|
||||
public:
|
||||
// Add a new task to the end of the queue
|
||||
@@ -38,15 +43,18 @@ public:
|
||||
// Get the next id for creating a new task
|
||||
int get_new_id();
|
||||
|
||||
// Register function to process a new task
|
||||
void on_new_task(std::function<void(server_task &&)> callback);
|
||||
|
||||
// Register the function to be called when all slots data is ready to be processed
|
||||
void on_update_slots(std::function<void(void)> callback);
|
||||
|
||||
// Call when the state of one slot is changed, it will move one task from deferred to main queue
|
||||
void pop_deferred_task();
|
||||
|
||||
// if sleeping, request exiting sleep state and wait until it is done
|
||||
// returns immediately if not sleeping
|
||||
void wait_until_no_sleep();
|
||||
|
||||
bool is_sleeping() {
|
||||
std::unique_lock<std::mutex> lock(mutex_tasks);
|
||||
return sleeping;
|
||||
}
|
||||
|
||||
// end the start_loop routine
|
||||
void terminate();
|
||||
|
||||
@@ -56,8 +64,15 @@ public:
|
||||
* - Process the task (i.e. maybe copy data into slot)
|
||||
* - Check if multitask is finished
|
||||
* - Update all slots
|
||||
*
|
||||
* Sleeping procedure (disabled if idle_sleep_ms < 0):
|
||||
* - If there is no task after idle_sleep_ms, enter sleeping state
|
||||
* - Call callback_sleeping_state(true)
|
||||
* - Wait until req_stop_sleeping is set to true
|
||||
* - Call callback_sleeping_state(false)
|
||||
* - Exit sleeping state
|
||||
*/
|
||||
void start_loop();
|
||||
void start_loop(int64_t idle_sleep_ms = -1);
|
||||
|
||||
// for metrics
|
||||
size_t queue_tasks_deferred_size() {
|
||||
@@ -65,6 +80,27 @@ public:
|
||||
return queue_tasks_deferred.size();
|
||||
}
|
||||
|
||||
//
|
||||
// Functions below are not thread-safe, must only be used before start_loop() is called
|
||||
//
|
||||
|
||||
// Register function to process a new task
|
||||
void on_new_task(std::function<void(server_task &&)> callback) {
|
||||
callback_new_task = std::move(callback);
|
||||
}
|
||||
|
||||
// Register the function to be called when all slots data is ready to be processed
|
||||
void on_update_slots(std::function<void(void)> callback) {
|
||||
callback_update_slots = std::move(callback);
|
||||
}
|
||||
|
||||
// Register callback for sleeping state change
|
||||
// note: when entering sleeping state, the callback is called AFTER sleeping is set to true
|
||||
// when leaving sleeping state, the callback is called BEFORE sleeping is set to false
|
||||
void on_sleeping_state(std::function<void(bool)> callback) {
|
||||
callback_sleeping_state = std::move(callback);
|
||||
}
|
||||
|
||||
private:
|
||||
void cleanup_pending_task(int id_target);
|
||||
};
|
||||
@@ -138,8 +174,10 @@ struct server_response_reader {
|
||||
int get_new_id() {
|
||||
return queue_tasks.get_new_id();
|
||||
}
|
||||
void post_task(server_task && task);
|
||||
void post_tasks(std::vector<server_task> && tasks);
|
||||
|
||||
// if front = true, the task will be posted to the front of the queue (high priority)
|
||||
void post_task(server_task && task, bool front = false);
|
||||
void post_tasks(std::vector<server_task> && tasks, bool front = false);
|
||||
bool has_next() const;
|
||||
|
||||
// return nullptr if should_stop() is true before receiving a result
|
||||
|
||||
@@ -32,8 +32,8 @@ json task_params::to_json(bool only_metrics) const {
|
||||
}
|
||||
|
||||
json lora = json::array();
|
||||
for (size_t i = 0; i < this->lora.size(); ++i) {
|
||||
lora.push_back({{"id", i}, {"scale", this->lora[i].scale}});
|
||||
for (auto & it : this->lora) {
|
||||
lora.push_back({{"id", it.first}, {"scale", it.second}});
|
||||
}
|
||||
|
||||
if (only_metrics) {
|
||||
@@ -145,12 +145,10 @@ json task_params::to_json(bool only_metrics) const {
|
||||
//
|
||||
|
||||
task_params server_task::params_from_json_cmpl(
|
||||
const llama_context * ctx,
|
||||
const llama_vocab * vocab,
|
||||
const common_params & params_base,
|
||||
const int n_ctx_slot,
|
||||
const json & data) {
|
||||
const llama_model * model = llama_get_model(ctx);
|
||||
const llama_vocab * vocab = llama_model_get_vocab(model);
|
||||
|
||||
task_params params;
|
||||
|
||||
// Sampling parameter defaults are loaded from the global server context (but individual requests can still them)
|
||||
@@ -223,12 +221,12 @@ task_params server_task::params_from_json_cmpl(
|
||||
|
||||
if (data.contains("lora")) {
|
||||
if (data.at("lora").is_array()) {
|
||||
params.lora = parse_lora_request(params_base.lora_adapters, data.at("lora"));
|
||||
params.lora = parse_lora_request(data.at("lora"));
|
||||
} else {
|
||||
throw std::runtime_error("Error: 'lora' must be an array of objects with 'id' and 'scale' fields");
|
||||
}
|
||||
} else {
|
||||
params.lora = params_base.lora_adapters;
|
||||
params.lora = {};
|
||||
}
|
||||
|
||||
// TODO: add more sanity checks for the input parameters
|
||||
@@ -243,11 +241,11 @@ task_params server_task::params_from_json_cmpl(
|
||||
|
||||
if (params.sampling.penalty_last_n == -1) {
|
||||
// note: should be the slot's context and not the full context, but it's ok
|
||||
params.sampling.penalty_last_n = llama_n_ctx(ctx);
|
||||
params.sampling.penalty_last_n = n_ctx_slot;
|
||||
}
|
||||
|
||||
if (params.sampling.dry_penalty_last_n == -1) {
|
||||
params.sampling.dry_penalty_last_n = llama_n_ctx(ctx);
|
||||
params.sampling.dry_penalty_last_n = n_ctx_slot;
|
||||
}
|
||||
|
||||
if (params.sampling.dry_base < 1.0f) {
|
||||
@@ -1153,7 +1151,7 @@ json server_task_result_rerank::to_json() {
|
||||
json server_task_result_cmpl_partial::to_json_anthropic() {
|
||||
json events = json::array();
|
||||
bool first = (n_decoded == 1);
|
||||
static bool text_block_started = false;
|
||||
bool text_block_started = false;
|
||||
|
||||
if (first) {
|
||||
text_block_started = false;
|
||||
@@ -1324,6 +1322,30 @@ json server_task_result_slot_erase::to_json() {
|
||||
};
|
||||
}
|
||||
|
||||
//
|
||||
// server_task_result_get_lora
|
||||
//
|
||||
|
||||
json server_task_result_get_lora::to_json() {
|
||||
json result = json::array();
|
||||
for (size_t i = 0; i < loras.size(); ++i) {
|
||||
auto & lora = loras[i];
|
||||
json entry = {
|
||||
{"id", i},
|
||||
{"path", lora.info.path},
|
||||
{"scale", lora.info.scale},
|
||||
{"task_name", lora.info.task_name},
|
||||
{"prompt_prefix", lora.info.prompt_prefix},
|
||||
};
|
||||
if (!lora.alora_invocation_tokens.empty()) {
|
||||
entry["alora_invocation_string"] = lora.alora_invocation_string;
|
||||
entry["alora_invocation_tokens"] = lora.alora_invocation_tokens;
|
||||
}
|
||||
result.push_back(std::move(entry));
|
||||
}
|
||||
return result;
|
||||
}
|
||||
|
||||
//
|
||||
// server_task_result_apply_lora
|
||||
//
|
||||
|
||||
+28
-35
@@ -6,6 +6,7 @@
|
||||
#include <string>
|
||||
#include <unordered_set>
|
||||
#include <list>
|
||||
#include <map>
|
||||
|
||||
// TODO: prevent including the whole server-common.h as we only use server_tokens
|
||||
#include "server-common.h"
|
||||
@@ -23,6 +24,7 @@ enum server_task_type {
|
||||
SERVER_TASK_TYPE_SLOT_SAVE,
|
||||
SERVER_TASK_TYPE_SLOT_RESTORE,
|
||||
SERVER_TASK_TYPE_SLOT_ERASE,
|
||||
SERVER_TASK_TYPE_GET_LORA,
|
||||
SERVER_TASK_TYPE_SET_LORA,
|
||||
};
|
||||
|
||||
@@ -60,7 +62,7 @@ struct task_params {
|
||||
int64_t t_max_prompt_ms = -1; // TODO: implement
|
||||
int64_t t_max_predict_ms = -1; // if positive, limit the generation phase to this time limit
|
||||
|
||||
std::vector<common_adapter_lora_info> lora;
|
||||
std::map<int, float> lora; // mapping adapter ID -> scale
|
||||
|
||||
std::vector<std::string> antiprompt;
|
||||
std::vector<std::string> response_fields;
|
||||
@@ -105,8 +107,10 @@ struct task_result_state {
|
||||
};
|
||||
|
||||
struct server_task {
|
||||
int id = -1; // to be filled by server_queue
|
||||
int index = -1; // used when there are multiple prompts (batch request)
|
||||
int id = -1; // to be filled by server_queue
|
||||
|
||||
// TODO @ngxson : remove this field and implement a mapping task_id -> idx in the response_reader
|
||||
size_t index = 0; // used when there are multiple prompts (batch request)
|
||||
|
||||
// used by SERVER_TASK_TYPE_CANCEL
|
||||
int id_target = -1;
|
||||
@@ -138,7 +142,7 @@ struct server_task {
|
||||
bool metrics_reset_bucket = false;
|
||||
|
||||
// used by SERVER_TASK_TYPE_SET_LORA
|
||||
std::vector<common_adapter_lora_info> set_lora;
|
||||
std::map<int, float> set_lora; // mapping adapter ID -> scale
|
||||
|
||||
server_task() = default;
|
||||
|
||||
@@ -149,9 +153,10 @@ struct server_task {
|
||||
}
|
||||
|
||||
static task_params params_from_json_cmpl(
|
||||
const llama_context * ctx,
|
||||
const common_params & params_base,
|
||||
const json & data);
|
||||
const llama_vocab * vocab,
|
||||
const common_params & params_base,
|
||||
const int n_ctx_slot,
|
||||
const json & data);
|
||||
|
||||
// utility function
|
||||
static std::unordered_set<int> get_list_id(const std::vector<server_task> & tasks) {
|
||||
@@ -162,10 +167,9 @@ struct server_task {
|
||||
return ids;
|
||||
}
|
||||
|
||||
server_task create_child(int id_parent, int id_child, int idx) const {
|
||||
server_task create_child(int id_parent, int id_child) const {
|
||||
server_task copy;
|
||||
copy.id = id_child;
|
||||
copy.index = idx;
|
||||
copy.id_parent = id_parent;
|
||||
copy.params = params;
|
||||
copy.type = type;
|
||||
@@ -212,6 +216,10 @@ struct result_prompt_progress {
|
||||
struct server_task_result {
|
||||
int id = -1;
|
||||
int id_slot = -1;
|
||||
|
||||
// TODO @ngxson : remove this field and implement a mapping task_id -> idx in the response_reader
|
||||
size_t index = 0; // to be used for batched tasks
|
||||
|
||||
virtual bool is_error() {
|
||||
// only used by server_task_result_error
|
||||
return false;
|
||||
@@ -220,9 +228,6 @@ struct server_task_result {
|
||||
// only used by server_task_result_cmpl_*
|
||||
return true;
|
||||
}
|
||||
virtual int get_index() {
|
||||
return -1;
|
||||
}
|
||||
virtual void update(task_result_state &) {
|
||||
// only used by server_task_result_cmpl_*
|
||||
}
|
||||
@@ -255,8 +260,6 @@ struct completion_token_output {
|
||||
};
|
||||
|
||||
struct server_task_result_cmpl_final : server_task_result {
|
||||
int index = 0;
|
||||
|
||||
std::string content;
|
||||
llama_tokens tokens;
|
||||
|
||||
@@ -289,10 +292,6 @@ struct server_task_result_cmpl_final : server_task_result {
|
||||
std::vector<common_chat_msg_diff> oaicompat_msg_diffs; // to be populated by update()
|
||||
bool is_updated = false;
|
||||
|
||||
virtual int get_index() override {
|
||||
return index;
|
||||
}
|
||||
|
||||
virtual bool is_stop() override {
|
||||
return true; // in stream mode, final responses are considered stop
|
||||
}
|
||||
@@ -318,8 +317,6 @@ struct server_task_result_cmpl_final : server_task_result {
|
||||
};
|
||||
|
||||
struct server_task_result_cmpl_partial : server_task_result {
|
||||
int index = 0;
|
||||
|
||||
std::string content;
|
||||
llama_tokens tokens;
|
||||
|
||||
@@ -340,10 +337,6 @@ struct server_task_result_cmpl_partial : server_task_result {
|
||||
std::vector<common_chat_msg_diff> oaicompat_msg_diffs; // to be populated by update()
|
||||
bool is_updated = false;
|
||||
|
||||
virtual int get_index() override {
|
||||
return index;
|
||||
}
|
||||
|
||||
virtual bool is_stop() override {
|
||||
return false; // in stream mode, partial responses are not considered stop
|
||||
}
|
||||
@@ -365,7 +358,6 @@ struct server_task_result_cmpl_partial : server_task_result {
|
||||
};
|
||||
|
||||
struct server_task_result_embd : server_task_result {
|
||||
int index = 0;
|
||||
std::vector<std::vector<float>> embedding;
|
||||
|
||||
int32_t n_tokens;
|
||||
@@ -373,10 +365,6 @@ struct server_task_result_embd : server_task_result {
|
||||
// response formatting
|
||||
task_response_type res_type = TASK_RESPONSE_TYPE_NONE;
|
||||
|
||||
virtual int get_index() override {
|
||||
return index;
|
||||
}
|
||||
|
||||
virtual json to_json() override;
|
||||
|
||||
json to_json_non_oaicompat();
|
||||
@@ -385,20 +373,14 @@ struct server_task_result_embd : server_task_result {
|
||||
};
|
||||
|
||||
struct server_task_result_rerank : server_task_result {
|
||||
int index = 0;
|
||||
float score = -1e6;
|
||||
|
||||
int32_t n_tokens;
|
||||
|
||||
virtual int get_index() override {
|
||||
return index;
|
||||
}
|
||||
|
||||
virtual json to_json() override;
|
||||
};
|
||||
|
||||
struct server_task_result_error : server_task_result {
|
||||
int index = 0;
|
||||
error_type err_type = ERROR_TYPE_SERVER;
|
||||
std::string err_msg;
|
||||
|
||||
@@ -460,6 +442,17 @@ struct server_task_result_slot_erase : server_task_result {
|
||||
virtual json to_json() override;
|
||||
};
|
||||
|
||||
struct server_task_result_get_lora : server_task_result {
|
||||
struct lora {
|
||||
common_adapter_lora_info info;
|
||||
std::string alora_invocation_string;
|
||||
llama_tokens alora_invocation_tokens;
|
||||
};
|
||||
std::vector<lora> loras;
|
||||
|
||||
virtual json to_json() override;
|
||||
};
|
||||
|
||||
struct server_task_result_apply_lora : server_task_result {
|
||||
virtual json to_json() override;
|
||||
};
|
||||
|
||||
@@ -119,7 +119,7 @@ int main(int argc, char ** argv, char ** envp) {
|
||||
//
|
||||
|
||||
// register API routes
|
||||
server_routes routes(params, ctx_server, [&ctx_http]() { return ctx_http.is_ready.load(); });
|
||||
server_routes routes(params, ctx_server);
|
||||
|
||||
bool is_router_server = params.model.path.empty();
|
||||
std::optional<server_models_routes> models_routes{};
|
||||
@@ -252,7 +252,7 @@ int main(int argc, char ** argv, char ** envp) {
|
||||
return 1;
|
||||
}
|
||||
|
||||
ctx_server.init();
|
||||
routes.update_meta(ctx_server);
|
||||
ctx_http.is_ready.store(true);
|
||||
|
||||
LOG_INF("%s: model loaded\n", __func__);
|
||||
@@ -309,7 +309,11 @@ int main(int argc, char ** argv, char ** envp) {
|
||||
if (monitor_thread.joinable()) {
|
||||
monitor_thread.join();
|
||||
}
|
||||
llama_memory_breakdown_print(ctx_server.get_llama_context());
|
||||
|
||||
auto * ll_ctx = ctx_server.get_llama_context();
|
||||
if (ll_ctx != nullptr) {
|
||||
llama_memory_breakdown_print(ll_ctx);
|
||||
}
|
||||
}
|
||||
|
||||
return 0;
|
||||
|
||||
@@ -0,0 +1,39 @@
|
||||
import pytest
|
||||
import time
|
||||
from utils import *
|
||||
|
||||
server = ServerPreset.tinyllama2()
|
||||
|
||||
|
||||
@pytest.fixture(autouse=True)
|
||||
def create_server():
|
||||
global server
|
||||
server = ServerPreset.tinyllama2()
|
||||
|
||||
|
||||
def test_server_sleep():
|
||||
global server
|
||||
server.sleep_idle_seconds = 1
|
||||
server.start()
|
||||
|
||||
# wait a bit so that server can go to sleep
|
||||
time.sleep(2)
|
||||
|
||||
# make sure these endpoints are still responsive after sleep
|
||||
res = server.make_request("GET", "/health")
|
||||
assert res.status_code == 200
|
||||
res = server.make_request("GET", "/props")
|
||||
assert res.status_code == 200
|
||||
assert res.body["is_sleeping"] == True
|
||||
|
||||
# make a generation request to wake up the server
|
||||
res = server.make_request("POST", "/completion", data={
|
||||
"n_predict": 1,
|
||||
"prompt": "Hello",
|
||||
})
|
||||
assert res.status_code == 200
|
||||
|
||||
# it should no longer be sleeping
|
||||
res = server.make_request("GET", "/props")
|
||||
assert res.status_code == 200
|
||||
assert res.body["is_sleeping"] == False
|
||||
@@ -100,6 +100,7 @@ class ServerProcess:
|
||||
server_path: str | None = None
|
||||
mmproj_url: str | None = None
|
||||
media_path: str | None = None
|
||||
sleep_idle_seconds: int | None = None
|
||||
|
||||
# session variables
|
||||
process: subprocess.Popen | None = None
|
||||
@@ -230,6 +231,8 @@ class ServerProcess:
|
||||
server_args.extend(["--mmproj-url", self.mmproj_url])
|
||||
if self.media_path:
|
||||
server_args.extend(["--media-path", self.media_path])
|
||||
if self.sleep_idle_seconds is not None:
|
||||
server_args.extend(["--sleep-idle-seconds", self.sleep_idle_seconds])
|
||||
|
||||
args = [str(arg) for arg in [server_path, *server_args]]
|
||||
print(f"tests: starting server with: {' '.join(args)}")
|
||||
|
||||
@@ -11,6 +11,8 @@ flowchart TB
|
||||
C_Screen["ChatScreen"]
|
||||
C_Form["ChatForm"]
|
||||
C_Messages["ChatMessages"]
|
||||
C_Message["ChatMessage"]
|
||||
C_MessageEditForm["ChatMessageEditForm"]
|
||||
C_ModelsSelector["ModelsSelector"]
|
||||
C_Settings["ChatSettings"]
|
||||
end
|
||||
@@ -54,7 +56,9 @@ flowchart TB
|
||||
|
||||
%% Component hierarchy
|
||||
C_Screen --> C_Form & C_Messages & C_Settings
|
||||
C_Form & C_Messages --> C_ModelsSelector
|
||||
C_Messages --> C_Message
|
||||
C_Message --> C_MessageEditForm
|
||||
C_Form & C_MessageEditForm --> C_ModelsSelector
|
||||
|
||||
%% Components → Hooks → Stores
|
||||
C_Form & C_Messages --> H1 & H2
|
||||
@@ -93,7 +97,7 @@ flowchart TB
|
||||
classDef apiStyle fill:#e3f2fd,stroke:#1565c0,stroke-width:2px
|
||||
|
||||
class R1,R2,RL routeStyle
|
||||
class C_Sidebar,C_Screen,C_Form,C_Messages,C_ModelsSelector,C_Settings componentStyle
|
||||
class C_Sidebar,C_Screen,C_Form,C_Messages,C_Message,C_MessageEditForm,C_ModelsSelector,C_Settings componentStyle
|
||||
class H1,H2 hookStyle
|
||||
class S1,S2,S3,S4,S5 storeStyle
|
||||
class SV1,SV2,SV3,SV4,SV5 serviceStyle
|
||||
|
||||
@@ -16,6 +16,8 @@ end
|
||||
C_Form["ChatForm"]
|
||||
C_Messages["ChatMessages"]
|
||||
C_Message["ChatMessage"]
|
||||
C_MessageUser["ChatMessageUser"]
|
||||
C_MessageEditForm["ChatMessageEditForm"]
|
||||
C_Attach["ChatAttachments"]
|
||||
C_ModelsSelector["ModelsSelector"]
|
||||
C_Settings["ChatSettings"]
|
||||
@@ -38,7 +40,7 @@ end
|
||||
S1Error["<b>Error Handling:</b><br/>showErrorDialog()<br/>dismissErrorDialog()<br/>isAbortError()"]
|
||||
S1Msg["<b>Message Operations:</b><br/>addMessage()<br/>sendMessage()<br/>updateMessage()<br/>deleteMessage()<br/>getDeletionInfo()"]
|
||||
S1Regen["<b>Regeneration:</b><br/>regenerateMessage()<br/>regenerateMessageWithBranching()<br/>continueAssistantMessage()"]
|
||||
S1Edit["<b>Editing:</b><br/>editAssistantMessage()<br/>editUserMessagePreserveResponses()<br/>editMessageWithBranching()"]
|
||||
S1Edit["<b>Editing:</b><br/>editAssistantMessage()<br/>editUserMessagePreserveResponses()<br/>editMessageWithBranching()<br/>clearEditMode()<br/>isEditModeActive()<br/>getAddFilesHandler()<br/>setEditModeActive()"]
|
||||
S1Utils["<b>Utilities:</b><br/>getApiOptions()<br/>parseTimingData()<br/>getOrCreateAbortController()<br/>getConversationModel()"]
|
||||
end
|
||||
subgraph S2["conversationsStore"]
|
||||
@@ -88,6 +90,10 @@ end
|
||||
RE7["getChatStreaming()"]
|
||||
RE8["getAllLoadingChats()"]
|
||||
RE9["getAllStreamingChats()"]
|
||||
RE9a["isEditModeActive()"]
|
||||
RE9b["getAddFilesHandler()"]
|
||||
RE9c["setEditModeActive()"]
|
||||
RE9d["clearEditMode()"]
|
||||
end
|
||||
subgraph ConvExports["conversationsStore"]
|
||||
RE10["conversations()"]
|
||||
@@ -182,7 +188,10 @@ end
|
||||
%% Component hierarchy
|
||||
C_Screen --> C_Form & C_Messages & C_Settings
|
||||
C_Messages --> C_Message
|
||||
C_Message --> C_ModelsSelector
|
||||
C_Message --> C_MessageUser
|
||||
C_MessageUser --> C_MessageEditForm
|
||||
C_MessageEditForm --> C_ModelsSelector
|
||||
C_MessageEditForm --> C_Attach
|
||||
C_Form --> C_ModelsSelector
|
||||
C_Form --> C_Attach
|
||||
C_Message --> C_Attach
|
||||
@@ -190,6 +199,7 @@ end
|
||||
%% Components use Hooks
|
||||
C_Form --> H1
|
||||
C_Message --> H1 & H2
|
||||
C_MessageEditForm --> H1
|
||||
C_Screen --> H2
|
||||
|
||||
%% Hooks use Stores
|
||||
@@ -244,7 +254,7 @@ end
|
||||
classDef apiStyle fill:#e3f2fd,stroke:#1565c0,stroke-width:2px
|
||||
|
||||
class R1,R2,RL routeStyle
|
||||
class C_Sidebar,C_Screen,C_Form,C_Messages,C_Message componentStyle
|
||||
class C_Sidebar,C_Screen,C_Form,C_Messages,C_Message,C_MessageUser,C_MessageEditForm componentStyle
|
||||
class C_ModelsSelector,C_Settings componentStyle
|
||||
class C_Attach componentStyle
|
||||
class H1,H2,H3 methodStyle
|
||||
|
||||
Generated
+4
-4
@@ -25,7 +25,7 @@
|
||||
"@chromatic-com/storybook": "^4.1.2",
|
||||
"@eslint/compat": "^1.2.5",
|
||||
"@eslint/js": "^9.18.0",
|
||||
"@internationalized/date": "^3.8.2",
|
||||
"@internationalized/date": "^3.10.1",
|
||||
"@lucide/svelte": "^0.515.0",
|
||||
"@playwright/test": "^1.49.1",
|
||||
"@storybook/addon-a11y": "^10.0.7",
|
||||
@@ -862,9 +862,9 @@
|
||||
}
|
||||
},
|
||||
"node_modules/@internationalized/date": {
|
||||
"version": "3.8.2",
|
||||
"resolved": "https://registry.npmjs.org/@internationalized/date/-/date-3.8.2.tgz",
|
||||
"integrity": "sha512-/wENk7CbvLbkUvX1tu0mwq49CVkkWpkXubGel6birjRPyo6uQ4nQpnq5xZu823zRCwwn82zgHrvgF1vZyvmVgA==",
|
||||
"version": "3.10.1",
|
||||
"resolved": "https://registry.npmjs.org/@internationalized/date/-/date-3.10.1.tgz",
|
||||
"integrity": "sha512-oJrXtQiAXLvT9clCf1K4kxp3eKsQhIaZqxEyowkBcsvZDdZkbWrVmnGknxs5flTD0VGsxrxKgBCZty1EzoiMzA==",
|
||||
"dev": true,
|
||||
"license": "Apache-2.0",
|
||||
"dependencies": {
|
||||
|
||||
@@ -26,7 +26,7 @@
|
||||
"@chromatic-com/storybook": "^4.1.2",
|
||||
"@eslint/compat": "^1.2.5",
|
||||
"@eslint/js": "^9.18.0",
|
||||
"@internationalized/date": "^3.8.2",
|
||||
"@internationalized/date": "^3.10.1",
|
||||
"@lucide/svelte": "^0.515.0",
|
||||
"@playwright/test": "^1.49.1",
|
||||
"@storybook/addon-a11y": "^10.0.7",
|
||||
|
||||
@@ -8,6 +8,7 @@
|
||||
ChatFormTextarea
|
||||
} from '$lib/components/app';
|
||||
import { INPUT_CLASSES } from '$lib/constants/input-classes';
|
||||
import { SETTING_CONFIG_DEFAULT } from '$lib/constants/settings-config';
|
||||
import { config } from '$lib/stores/settings.svelte';
|
||||
import { modelsStore, modelOptions, selectedModelId } from '$lib/stores/models.svelte';
|
||||
import { isRouterMode } from '$lib/stores/server.svelte';
|
||||
@@ -66,7 +67,7 @@
|
||||
let message = $state('');
|
||||
let pasteLongTextToFileLength = $derived.by(() => {
|
||||
const n = Number(currentConfig.pasteLongTextToFileLen);
|
||||
return Number.isNaN(n) ? 2500 : n;
|
||||
return Number.isNaN(n) ? Number(SETTING_CONFIG_DEFAULT.pasteLongTextToFileLen) : n;
|
||||
});
|
||||
let previousIsLoading = $state(isLoading);
|
||||
let recordingSupported = $state(false);
|
||||
|
||||
@@ -12,13 +12,21 @@
|
||||
onCopy?: (message: DatabaseMessage) => void;
|
||||
onContinueAssistantMessage?: (message: DatabaseMessage) => void;
|
||||
onDelete?: (message: DatabaseMessage) => void;
|
||||
onEditWithBranching?: (message: DatabaseMessage, newContent: string) => void;
|
||||
onEditWithBranching?: (
|
||||
message: DatabaseMessage,
|
||||
newContent: string,
|
||||
newExtras?: DatabaseMessageExtra[]
|
||||
) => void;
|
||||
onEditWithReplacement?: (
|
||||
message: DatabaseMessage,
|
||||
newContent: string,
|
||||
shouldBranch: boolean
|
||||
) => void;
|
||||
onEditUserMessagePreserveResponses?: (message: DatabaseMessage, newContent: string) => void;
|
||||
onEditUserMessagePreserveResponses?: (
|
||||
message: DatabaseMessage,
|
||||
newContent: string,
|
||||
newExtras?: DatabaseMessageExtra[]
|
||||
) => void;
|
||||
onNavigateToSibling?: (siblingId: string) => void;
|
||||
onRegenerateWithBranching?: (message: DatabaseMessage, modelOverride?: string) => void;
|
||||
siblingInfo?: ChatMessageSiblingInfo | null;
|
||||
@@ -45,6 +53,8 @@
|
||||
messageTypes: string[];
|
||||
} | null>(null);
|
||||
let editedContent = $state(message.content);
|
||||
let editedExtras = $state<DatabaseMessageExtra[]>(message.extra ? [...message.extra] : []);
|
||||
let editedUploadedFiles = $state<ChatUploadedFile[]>([]);
|
||||
let isEditing = $state(false);
|
||||
let showDeleteDialog = $state(false);
|
||||
let shouldBranchAfterEdit = $state(false);
|
||||
@@ -85,6 +95,16 @@
|
||||
function handleCancelEdit() {
|
||||
isEditing = false;
|
||||
editedContent = message.content;
|
||||
editedExtras = message.extra ? [...message.extra] : [];
|
||||
editedUploadedFiles = [];
|
||||
}
|
||||
|
||||
function handleEditedExtrasChange(extras: DatabaseMessageExtra[]) {
|
||||
editedExtras = extras;
|
||||
}
|
||||
|
||||
function handleEditedUploadedFilesChange(files: ChatUploadedFile[]) {
|
||||
editedUploadedFiles = files;
|
||||
}
|
||||
|
||||
async function handleCopy() {
|
||||
@@ -107,6 +127,8 @@
|
||||
function handleEdit() {
|
||||
isEditing = true;
|
||||
editedContent = message.content;
|
||||
editedExtras = message.extra ? [...message.extra] : [];
|
||||
editedUploadedFiles = [];
|
||||
|
||||
setTimeout(() => {
|
||||
if (textareaElement) {
|
||||
@@ -143,9 +165,10 @@
|
||||
onContinueAssistantMessage?.(message);
|
||||
}
|
||||
|
||||
function handleSaveEdit() {
|
||||
async function handleSaveEdit() {
|
||||
if (message.role === 'user' || message.role === 'system') {
|
||||
onEditWithBranching?.(message, editedContent.trim());
|
||||
const finalExtras = await getMergedExtras();
|
||||
onEditWithBranching?.(message, editedContent.trim(), finalExtras);
|
||||
} else {
|
||||
// For assistant messages, preserve exact content including trailing whitespace
|
||||
// This is important for the Continue feature to work properly
|
||||
@@ -154,15 +177,30 @@
|
||||
|
||||
isEditing = false;
|
||||
shouldBranchAfterEdit = false;
|
||||
editedUploadedFiles = [];
|
||||
}
|
||||
|
||||
function handleSaveEditOnly() {
|
||||
async function handleSaveEditOnly() {
|
||||
if (message.role === 'user') {
|
||||
// For user messages, trim to avoid accidental whitespace
|
||||
onEditUserMessagePreserveResponses?.(message, editedContent.trim());
|
||||
const finalExtras = await getMergedExtras();
|
||||
onEditUserMessagePreserveResponses?.(message, editedContent.trim(), finalExtras);
|
||||
}
|
||||
|
||||
isEditing = false;
|
||||
editedUploadedFiles = [];
|
||||
}
|
||||
|
||||
async function getMergedExtras(): Promise<DatabaseMessageExtra[]> {
|
||||
if (editedUploadedFiles.length === 0) {
|
||||
return editedExtras;
|
||||
}
|
||||
|
||||
const { parseFilesToMessageExtras } = await import('$lib/utils/browser-only');
|
||||
const result = await parseFilesToMessageExtras(editedUploadedFiles);
|
||||
const newExtras = result?.extras || [];
|
||||
|
||||
return [...editedExtras, ...newExtras];
|
||||
}
|
||||
|
||||
function handleShowDeleteDialogChange(show: boolean) {
|
||||
@@ -197,6 +235,8 @@
|
||||
class={className}
|
||||
{deletionInfo}
|
||||
{editedContent}
|
||||
{editedExtras}
|
||||
{editedUploadedFiles}
|
||||
{isEditing}
|
||||
{message}
|
||||
onCancelEdit={handleCancelEdit}
|
||||
@@ -206,6 +246,8 @@
|
||||
onEdit={handleEdit}
|
||||
onEditKeydown={handleEditKeydown}
|
||||
onEditedContentChange={handleEditedContentChange}
|
||||
onEditedExtrasChange={handleEditedExtrasChange}
|
||||
onEditedUploadedFilesChange={handleEditedUploadedFilesChange}
|
||||
{onNavigateToSibling}
|
||||
onSaveEdit={handleSaveEdit}
|
||||
onSaveEditOnly={handleSaveEditOnly}
|
||||
|
||||
+391
@@ -0,0 +1,391 @@
|
||||
<script lang="ts">
|
||||
import { X, ArrowUp, Paperclip, AlertTriangle } from '@lucide/svelte';
|
||||
import { Button } from '$lib/components/ui/button';
|
||||
import { Switch } from '$lib/components/ui/switch';
|
||||
import { ChatAttachmentsList, DialogConfirmation, ModelsSelector } from '$lib/components/app';
|
||||
import { INPUT_CLASSES } from '$lib/constants/input-classes';
|
||||
import { SETTING_CONFIG_DEFAULT } from '$lib/constants/settings-config';
|
||||
import { AttachmentType, FileTypeCategory, MimeTypeText } from '$lib/enums';
|
||||
import { config } from '$lib/stores/settings.svelte';
|
||||
import { useModelChangeValidation } from '$lib/hooks/use-model-change-validation.svelte';
|
||||
import { setEditModeActive, clearEditMode } from '$lib/stores/chat.svelte';
|
||||
import { conversationsStore } from '$lib/stores/conversations.svelte';
|
||||
import { modelsStore } from '$lib/stores/models.svelte';
|
||||
import { isRouterMode } from '$lib/stores/server.svelte';
|
||||
import {
|
||||
autoResizeTextarea,
|
||||
getFileTypeCategory,
|
||||
getFileTypeCategoryByExtension,
|
||||
parseClipboardContent
|
||||
} from '$lib/utils';
|
||||
|
||||
interface Props {
|
||||
messageId: string;
|
||||
editedContent: string;
|
||||
editedExtras?: DatabaseMessageExtra[];
|
||||
editedUploadedFiles?: ChatUploadedFile[];
|
||||
originalContent: string;
|
||||
originalExtras?: DatabaseMessageExtra[];
|
||||
showSaveOnlyOption?: boolean;
|
||||
onCancelEdit: () => void;
|
||||
onSaveEdit: () => void;
|
||||
onSaveEditOnly?: () => void;
|
||||
onEditKeydown: (event: KeyboardEvent) => void;
|
||||
onEditedContentChange: (content: string) => void;
|
||||
onEditedExtrasChange?: (extras: DatabaseMessageExtra[]) => void;
|
||||
onEditedUploadedFilesChange?: (files: ChatUploadedFile[]) => void;
|
||||
textareaElement?: HTMLTextAreaElement;
|
||||
}
|
||||
|
||||
let {
|
||||
messageId,
|
||||
editedContent,
|
||||
editedExtras = [],
|
||||
editedUploadedFiles = [],
|
||||
originalContent,
|
||||
originalExtras = [],
|
||||
showSaveOnlyOption = false,
|
||||
onCancelEdit,
|
||||
onSaveEdit,
|
||||
onSaveEditOnly,
|
||||
onEditKeydown,
|
||||
onEditedContentChange,
|
||||
onEditedExtrasChange,
|
||||
onEditedUploadedFilesChange,
|
||||
textareaElement = $bindable()
|
||||
}: Props = $props();
|
||||
|
||||
let fileInputElement: HTMLInputElement | undefined = $state();
|
||||
let saveWithoutRegenerate = $state(false);
|
||||
let showDiscardDialog = $state(false);
|
||||
let isRouter = $derived(isRouterMode());
|
||||
let currentConfig = $derived(config());
|
||||
|
||||
let pasteLongTextToFileLength = $derived.by(() => {
|
||||
const n = Number(currentConfig.pasteLongTextToFileLen);
|
||||
|
||||
return Number.isNaN(n) ? Number(SETTING_CONFIG_DEFAULT.pasteLongTextToFileLen) : n;
|
||||
});
|
||||
|
||||
let hasUnsavedChanges = $derived.by(() => {
|
||||
if (editedContent !== originalContent) return true;
|
||||
if (editedUploadedFiles.length > 0) return true;
|
||||
|
||||
const extrasChanged =
|
||||
editedExtras.length !== originalExtras.length ||
|
||||
editedExtras.some((extra, i) => extra !== originalExtras[i]);
|
||||
|
||||
if (extrasChanged) return true;
|
||||
|
||||
return false;
|
||||
});
|
||||
|
||||
let hasAttachments = $derived(
|
||||
(editedExtras && editedExtras.length > 0) ||
|
||||
(editedUploadedFiles && editedUploadedFiles.length > 0)
|
||||
);
|
||||
|
||||
let canSubmit = $derived(editedContent.trim().length > 0 || hasAttachments);
|
||||
|
||||
function getEditedAttachmentsModalities(): ModelModalities {
|
||||
const modalities: ModelModalities = { vision: false, audio: false };
|
||||
|
||||
for (const extra of editedExtras) {
|
||||
if (extra.type === AttachmentType.IMAGE) {
|
||||
modalities.vision = true;
|
||||
}
|
||||
|
||||
if (
|
||||
extra.type === AttachmentType.PDF &&
|
||||
'processedAsImages' in extra &&
|
||||
extra.processedAsImages
|
||||
) {
|
||||
modalities.vision = true;
|
||||
}
|
||||
|
||||
if (extra.type === AttachmentType.AUDIO) {
|
||||
modalities.audio = true;
|
||||
}
|
||||
}
|
||||
|
||||
for (const file of editedUploadedFiles) {
|
||||
const category = getFileTypeCategory(file.type) || getFileTypeCategoryByExtension(file.name);
|
||||
if (category === FileTypeCategory.IMAGE) {
|
||||
modalities.vision = true;
|
||||
}
|
||||
if (category === FileTypeCategory.AUDIO) {
|
||||
modalities.audio = true;
|
||||
}
|
||||
}
|
||||
|
||||
return modalities;
|
||||
}
|
||||
|
||||
function getRequiredModalities(): ModelModalities {
|
||||
const beforeModalities = conversationsStore.getModalitiesUpToMessage(messageId);
|
||||
const editedModalities = getEditedAttachmentsModalities();
|
||||
|
||||
return {
|
||||
vision: beforeModalities.vision || editedModalities.vision,
|
||||
audio: beforeModalities.audio || editedModalities.audio
|
||||
};
|
||||
}
|
||||
|
||||
const { handleModelChange } = useModelChangeValidation({
|
||||
getRequiredModalities,
|
||||
onValidationFailure: async (previousModelId) => {
|
||||
if (previousModelId) {
|
||||
await modelsStore.selectModelById(previousModelId);
|
||||
}
|
||||
}
|
||||
});
|
||||
|
||||
function handleFileInputChange(event: Event) {
|
||||
const input = event.target as HTMLInputElement;
|
||||
if (!input.files || input.files.length === 0) return;
|
||||
|
||||
const files = Array.from(input.files);
|
||||
|
||||
processNewFiles(files);
|
||||
input.value = '';
|
||||
}
|
||||
|
||||
function handleGlobalKeydown(event: KeyboardEvent) {
|
||||
if (event.key === 'Escape') {
|
||||
event.preventDefault();
|
||||
attemptCancel();
|
||||
}
|
||||
}
|
||||
|
||||
function attemptCancel() {
|
||||
if (hasUnsavedChanges) {
|
||||
showDiscardDialog = true;
|
||||
} else {
|
||||
onCancelEdit();
|
||||
}
|
||||
}
|
||||
|
||||
function handleRemoveExistingAttachment(index: number) {
|
||||
if (!onEditedExtrasChange) return;
|
||||
|
||||
const newExtras = [...editedExtras];
|
||||
|
||||
newExtras.splice(index, 1);
|
||||
onEditedExtrasChange(newExtras);
|
||||
}
|
||||
|
||||
function handleRemoveUploadedFile(fileId: string) {
|
||||
if (!onEditedUploadedFilesChange) return;
|
||||
|
||||
const newFiles = editedUploadedFiles.filter((f) => f.id !== fileId);
|
||||
|
||||
onEditedUploadedFilesChange(newFiles);
|
||||
}
|
||||
|
||||
function handleSubmit() {
|
||||
if (!canSubmit) return;
|
||||
|
||||
if (saveWithoutRegenerate && onSaveEditOnly) {
|
||||
onSaveEditOnly();
|
||||
} else {
|
||||
onSaveEdit();
|
||||
}
|
||||
|
||||
saveWithoutRegenerate = false;
|
||||
}
|
||||
|
||||
async function processNewFiles(files: File[]) {
|
||||
if (!onEditedUploadedFilesChange) return;
|
||||
|
||||
const { processFilesToChatUploaded } = await import('$lib/utils/browser-only');
|
||||
const processed = await processFilesToChatUploaded(files);
|
||||
|
||||
onEditedUploadedFilesChange([...editedUploadedFiles, ...processed]);
|
||||
}
|
||||
|
||||
function handlePaste(event: ClipboardEvent) {
|
||||
if (!event.clipboardData) return;
|
||||
|
||||
const files = Array.from(event.clipboardData.items)
|
||||
.filter((item) => item.kind === 'file')
|
||||
.map((item) => item.getAsFile())
|
||||
.filter((file): file is File => file !== null);
|
||||
|
||||
if (files.length > 0) {
|
||||
event.preventDefault();
|
||||
processNewFiles(files);
|
||||
|
||||
return;
|
||||
}
|
||||
|
||||
const text = event.clipboardData.getData(MimeTypeText.PLAIN);
|
||||
|
||||
if (text.startsWith('"')) {
|
||||
const parsed = parseClipboardContent(text);
|
||||
|
||||
if (parsed.textAttachments.length > 0) {
|
||||
event.preventDefault();
|
||||
onEditedContentChange(parsed.message);
|
||||
|
||||
const attachmentFiles = parsed.textAttachments.map(
|
||||
(att) =>
|
||||
new File([att.content], att.name, {
|
||||
type: MimeTypeText.PLAIN
|
||||
})
|
||||
);
|
||||
|
||||
processNewFiles(attachmentFiles);
|
||||
|
||||
setTimeout(() => {
|
||||
textareaElement?.focus();
|
||||
}, 10);
|
||||
|
||||
return;
|
||||
}
|
||||
}
|
||||
|
||||
if (
|
||||
text.length > 0 &&
|
||||
pasteLongTextToFileLength > 0 &&
|
||||
text.length > pasteLongTextToFileLength
|
||||
) {
|
||||
event.preventDefault();
|
||||
|
||||
const textFile = new File([text], 'Pasted', {
|
||||
type: MimeTypeText.PLAIN
|
||||
});
|
||||
|
||||
processNewFiles([textFile]);
|
||||
}
|
||||
}
|
||||
|
||||
$effect(() => {
|
||||
if (textareaElement) {
|
||||
autoResizeTextarea(textareaElement);
|
||||
}
|
||||
});
|
||||
|
||||
$effect(() => {
|
||||
setEditModeActive(processNewFiles);
|
||||
|
||||
return () => {
|
||||
clearEditMode();
|
||||
};
|
||||
});
|
||||
</script>
|
||||
|
||||
<svelte:window onkeydown={handleGlobalKeydown} />
|
||||
|
||||
<input
|
||||
bind:this={fileInputElement}
|
||||
type="file"
|
||||
multiple
|
||||
class="hidden"
|
||||
onchange={handleFileInputChange}
|
||||
/>
|
||||
|
||||
<div
|
||||
class="{INPUT_CLASSES} w-full max-w-[80%] overflow-hidden rounded-3xl backdrop-blur-md"
|
||||
data-slot="edit-form"
|
||||
>
|
||||
<ChatAttachmentsList
|
||||
attachments={editedExtras}
|
||||
uploadedFiles={editedUploadedFiles}
|
||||
readonly={false}
|
||||
onFileRemove={(fileId) => {
|
||||
if (fileId.startsWith('attachment-')) {
|
||||
const index = parseInt(fileId.replace('attachment-', ''), 10);
|
||||
if (!isNaN(index) && index >= 0 && index < editedExtras.length) {
|
||||
handleRemoveExistingAttachment(index);
|
||||
}
|
||||
} else {
|
||||
handleRemoveUploadedFile(fileId);
|
||||
}
|
||||
}}
|
||||
limitToSingleRow
|
||||
class="py-5"
|
||||
style="scroll-padding: 1rem;"
|
||||
/>
|
||||
|
||||
<div class="relative min-h-[48px] px-5 py-3">
|
||||
<textarea
|
||||
bind:this={textareaElement}
|
||||
bind:value={editedContent}
|
||||
class="field-sizing-content max-h-80 min-h-10 w-full resize-none bg-transparent text-sm outline-none"
|
||||
onkeydown={onEditKeydown}
|
||||
oninput={(e) => {
|
||||
autoResizeTextarea(e.currentTarget);
|
||||
onEditedContentChange(e.currentTarget.value);
|
||||
}}
|
||||
onpaste={handlePaste}
|
||||
placeholder="Edit your message..."
|
||||
></textarea>
|
||||
|
||||
<div class="flex w-full items-center gap-3" style="container-type: inline-size">
|
||||
<Button
|
||||
class="h-8 w-8 shrink-0 rounded-full bg-transparent p-0 text-muted-foreground hover:bg-foreground/10 hover:text-foreground"
|
||||
onclick={() => fileInputElement?.click()}
|
||||
type="button"
|
||||
title="Add attachment"
|
||||
>
|
||||
<span class="sr-only">Attach files</span>
|
||||
|
||||
<Paperclip class="h-4 w-4" />
|
||||
</Button>
|
||||
|
||||
<div class="flex-1"></div>
|
||||
|
||||
{#if isRouter}
|
||||
<ModelsSelector
|
||||
forceForegroundText={true}
|
||||
useGlobalSelection={true}
|
||||
onModelChange={handleModelChange}
|
||||
/>
|
||||
{/if}
|
||||
|
||||
<Button
|
||||
class="h-8 w-8 shrink-0 rounded-full p-0"
|
||||
onclick={handleSubmit}
|
||||
disabled={!canSubmit}
|
||||
type="button"
|
||||
title={saveWithoutRegenerate ? 'Save changes' : 'Send and regenerate'}
|
||||
>
|
||||
<span class="sr-only">{saveWithoutRegenerate ? 'Save' : 'Send'}</span>
|
||||
|
||||
<ArrowUp class="h-5 w-5" />
|
||||
</Button>
|
||||
</div>
|
||||
</div>
|
||||
</div>
|
||||
|
||||
<div class="mt-2 flex w-full max-w-[80%] items-center justify-between">
|
||||
{#if showSaveOnlyOption && onSaveEditOnly}
|
||||
<div class="flex items-center gap-2">
|
||||
<Switch id="save-only-switch" bind:checked={saveWithoutRegenerate} class="scale-75" />
|
||||
|
||||
<label for="save-only-switch" class="cursor-pointer text-xs text-muted-foreground">
|
||||
Update without re-sending
|
||||
</label>
|
||||
</div>
|
||||
{:else}
|
||||
<div></div>
|
||||
{/if}
|
||||
|
||||
<Button class="h-7 px-3 text-xs" onclick={attemptCancel} size="sm" variant="ghost">
|
||||
<X class="mr-1 h-3 w-3" />
|
||||
|
||||
Cancel
|
||||
</Button>
|
||||
</div>
|
||||
|
||||
<DialogConfirmation
|
||||
bind:open={showDiscardDialog}
|
||||
title="Discard changes?"
|
||||
description="You have unsaved changes. Are you sure you want to discard them?"
|
||||
confirmText="Discard"
|
||||
cancelText="Keep editing"
|
||||
variant="destructive"
|
||||
icon={AlertTriangle}
|
||||
onConfirm={onCancelEdit}
|
||||
onCancel={() => (showDiscardDialog = false)}
|
||||
/>
|
||||
+26
-48
@@ -1,18 +1,17 @@
|
||||
<script lang="ts">
|
||||
import { Check, X, Send } from '@lucide/svelte';
|
||||
import { Card } from '$lib/components/ui/card';
|
||||
import { Button } from '$lib/components/ui/button';
|
||||
import { ChatAttachmentsList, MarkdownContent } from '$lib/components/app';
|
||||
import { INPUT_CLASSES } from '$lib/constants/input-classes';
|
||||
import { config } from '$lib/stores/settings.svelte';
|
||||
import { autoResizeTextarea } from '$lib/utils';
|
||||
import ChatMessageActions from './ChatMessageActions.svelte';
|
||||
import ChatMessageEditForm from './ChatMessageEditForm.svelte';
|
||||
|
||||
interface Props {
|
||||
class?: string;
|
||||
message: DatabaseMessage;
|
||||
isEditing: boolean;
|
||||
editedContent: string;
|
||||
editedExtras?: DatabaseMessageExtra[];
|
||||
editedUploadedFiles?: ChatUploadedFile[];
|
||||
siblingInfo?: ChatMessageSiblingInfo | null;
|
||||
showDeleteDialog: boolean;
|
||||
deletionInfo: {
|
||||
@@ -26,6 +25,8 @@
|
||||
onSaveEditOnly?: () => void;
|
||||
onEditKeydown: (event: KeyboardEvent) => void;
|
||||
onEditedContentChange: (content: string) => void;
|
||||
onEditedExtrasChange?: (extras: DatabaseMessageExtra[]) => void;
|
||||
onEditedUploadedFilesChange?: (files: ChatUploadedFile[]) => void;
|
||||
onCopy: () => void;
|
||||
onEdit: () => void;
|
||||
onDelete: () => void;
|
||||
@@ -40,6 +41,8 @@
|
||||
message,
|
||||
isEditing,
|
||||
editedContent,
|
||||
editedExtras = [],
|
||||
editedUploadedFiles = [],
|
||||
siblingInfo = null,
|
||||
showDeleteDialog,
|
||||
deletionInfo,
|
||||
@@ -48,6 +51,8 @@
|
||||
onSaveEditOnly,
|
||||
onEditKeydown,
|
||||
onEditedContentChange,
|
||||
onEditedExtrasChange,
|
||||
onEditedUploadedFilesChange,
|
||||
onCopy,
|
||||
onEdit,
|
||||
onDelete,
|
||||
@@ -61,12 +66,6 @@
|
||||
let messageElement: HTMLElement | undefined = $state();
|
||||
const currentConfig = config();
|
||||
|
||||
$effect(() => {
|
||||
if (isEditing && textareaElement) {
|
||||
autoResizeTextarea(textareaElement);
|
||||
}
|
||||
});
|
||||
|
||||
$effect(() => {
|
||||
if (!messageElement || !message.content.trim()) return;
|
||||
|
||||
@@ -98,44 +97,23 @@
|
||||
role="group"
|
||||
>
|
||||
{#if isEditing}
|
||||
<div class="w-full max-w-[80%]">
|
||||
<textarea
|
||||
bind:this={textareaElement}
|
||||
bind:value={editedContent}
|
||||
class="min-h-[60px] w-full resize-none rounded-2xl px-3 py-2 text-sm {INPUT_CLASSES}"
|
||||
onkeydown={onEditKeydown}
|
||||
oninput={(e) => {
|
||||
autoResizeTextarea(e.currentTarget);
|
||||
onEditedContentChange(e.currentTarget.value);
|
||||
}}
|
||||
placeholder="Edit your message..."
|
||||
></textarea>
|
||||
|
||||
<div class="mt-2 flex justify-end gap-2">
|
||||
<Button class="h-8 px-3" onclick={onCancelEdit} size="sm" variant="ghost">
|
||||
<X class="mr-1 h-3 w-3" />
|
||||
Cancel
|
||||
</Button>
|
||||
|
||||
{#if onSaveEditOnly}
|
||||
<Button
|
||||
class="h-8 px-3"
|
||||
onclick={onSaveEditOnly}
|
||||
disabled={!editedContent.trim()}
|
||||
size="sm"
|
||||
variant="outline"
|
||||
>
|
||||
<Check class="mr-1 h-3 w-3" />
|
||||
Save
|
||||
</Button>
|
||||
{/if}
|
||||
|
||||
<Button class="h-8 px-3" onclick={onSaveEdit} disabled={!editedContent.trim()} size="sm">
|
||||
<Send class="mr-1 h-3 w-3" />
|
||||
Send
|
||||
</Button>
|
||||
</div>
|
||||
</div>
|
||||
<ChatMessageEditForm
|
||||
bind:textareaElement
|
||||
messageId={message.id}
|
||||
{editedContent}
|
||||
{editedExtras}
|
||||
{editedUploadedFiles}
|
||||
originalContent={message.content}
|
||||
originalExtras={message.extra}
|
||||
showSaveOnlyOption={!!onSaveEditOnly}
|
||||
{onCancelEdit}
|
||||
{onSaveEdit}
|
||||
{onSaveEditOnly}
|
||||
{onEditKeydown}
|
||||
{onEditedContentChange}
|
||||
{onEditedExtrasChange}
|
||||
{onEditedUploadedFilesChange}
|
||||
/>
|
||||
{:else}
|
||||
{#if message.extra && message.extra.length > 0}
|
||||
<div class="mb-2 max-w-[80%]">
|
||||
|
||||
Some files were not shown because too many files have changed in this diff Show More
Reference in New Issue
Block a user